DLP-системы неплохо справляются с защитой от утечек данных, когда дело касается данных в движении. Сложности начинаются, когда мы хотим охватить оставшиеся 2 типа: данные в покое и данные в работе. Ниже речь пойдёт о первом из них. Под катом рассказ о том, какие задачи наших клиентов мы решили, создав первую российскую DCAP-систему. Немного кейсов, немного интерфейса, немного планов на будущее.
Что не так при контроле данных в покое с помощью DLP?Как правило, DLP-системы обладают механизмом eDiscovery для работы с данными в покое. В за данное направление отвечает модуль под названием «Индексация рабочих станций» (ИРС). Он хорош, но для своей задачи.
Задача eDiscovery – найти конфиденциальное содержимое. Просто найти. Не выявлять подробности о правах доступа или действиях с этой информацией. В этом и есть разница. Но у ИБ-специалистов возникают задачи не просто точечного поиска документов. Нужно выявить всех сотрудников, которые имеют доступ к файлам, определить, какие были внесены последние изменения, какие редакции критичных файлов сохранены и т.п. И здесь в дело должен вступить DCAP.

Коротко о DCAP
Пора расшифровать аббревиатуру, уже примелькавшуюся в тексте. DCAP-системы (Data-Centric Audit and Protection) предназначены для автоматизированного аудита данных в файловой системе, поиска нарушений прав доступа и отслеживания изменений в критичных документах.
В основном DCAP-системы по Gartner должны концентрироваться на следующем:
· Классификация данных.
· Хранение конфиденциальных данных.
· Управление безопасностью данных.
· Мониторинг и аудит данных.
· Защита всех данных от несанкционированного доступа и использования.
Подробно на анализе рынка DCAP-систем в рамках данного поста останавливаться было бы излишне.
Прошлое
Задумываясь о новом продукте в начале 2018 года, задачи для альфа-версии ставились следующие:
· Для аналитики использовать собственный движок, хорошо зарекомендовавший себя во флагманской DLP-системе.
· Поддерживать «агентский» и «сетевой» режимы работы.
· При этом быть независимым продуктом. То бишь, не конфликтовать со сторонними решениями.
· Быть быстрее-выше-сильнее конкурентов. И вообще, «пишите сразу без багов».
Логика работы закладывалась следующая:
· Система находит файл.
· Файл проверяется по правилам и получает служебную метку.
· При необходимости файл копируется в хранилище.
· Логируются все действия с файлами и папками.
· При последующих проверках система сканирует только изменённые и вновь добавленные файлы.
· Вычитываются права доступа для файлов и папок.
Если говорить о пожеланиях заказчиков, то в первую очередь они хотели узнать:
· Где что лежит в сети и на машинах сотрудников?
· Кто к этому имеет доступ?
· Утекли ли данные?
Процесс получения ответов начинался с создания Правила контроля данных. В Правиле описывается к каким объектам оно будет применено, по каким условиям будет осуществляться поиск и что делать системе, если файл подпадает под правило.
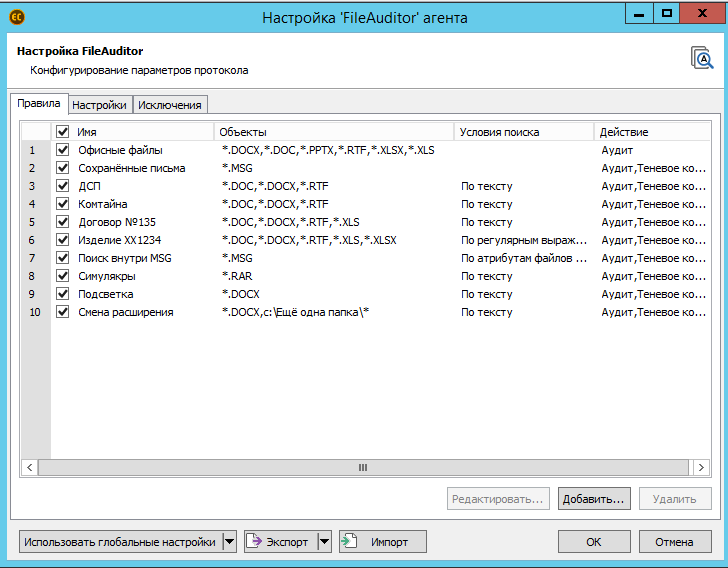
Первым делом в правиле задаются объекты интереса. Ими могут выступать, как расширение файла (определяется по имени либо по сигнатуре), так и место. Если задавать несколько условий, система будет объединять их по логическому «И».
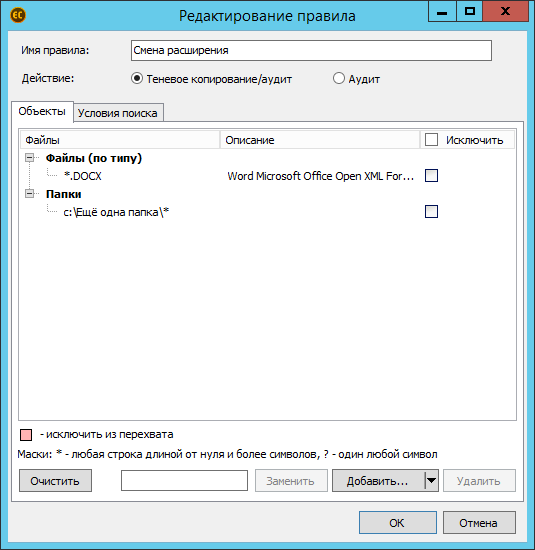
Как видно из скриншота, система поддерживает маски.
Следом работа перетекает на вкладку «Условия поиска». Их также можно объединять. Здесь задаются условия по содержимому файла. Ведь важно найти не все подряд файлы, а файлы с определённым содержимым. Например, с грифами.
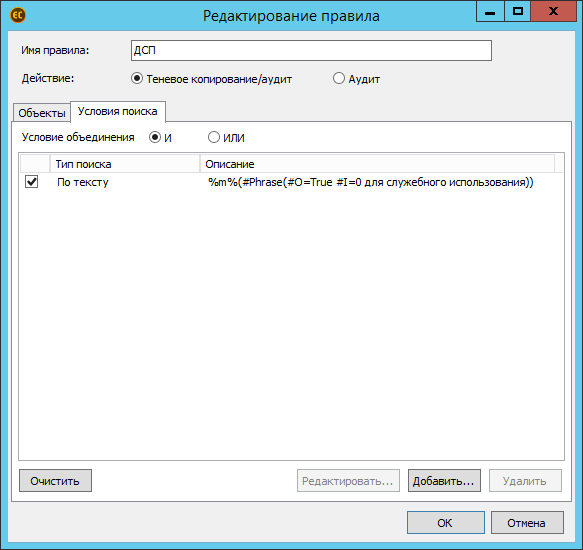
На момент выхода в публичный релиз в августе 2019 года мы поддерживали 3 вида поиска:
· По тексту.
· По атрибутам файлов.
· По регулярным выражениям.
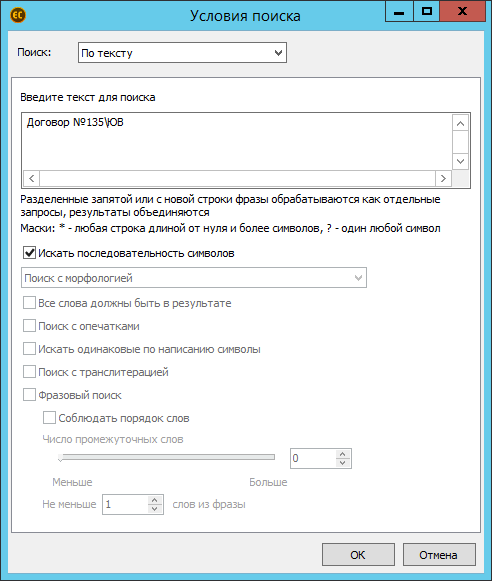
Поиск по тексту
Это полноценный фразовый поиск с кучей «примочек».
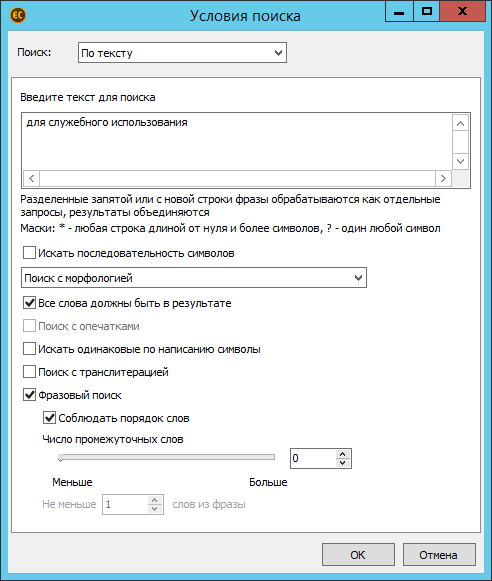
Отдельно хотелось бы отметить опцию поиска по последовательности символов, которая позволяет искать по неиндексированной информации (например, по символам №, @, , /, “ и прочим). В итоге, лёгким движением рук можно отыскать все копии и версии какого-нибудь важного договора.
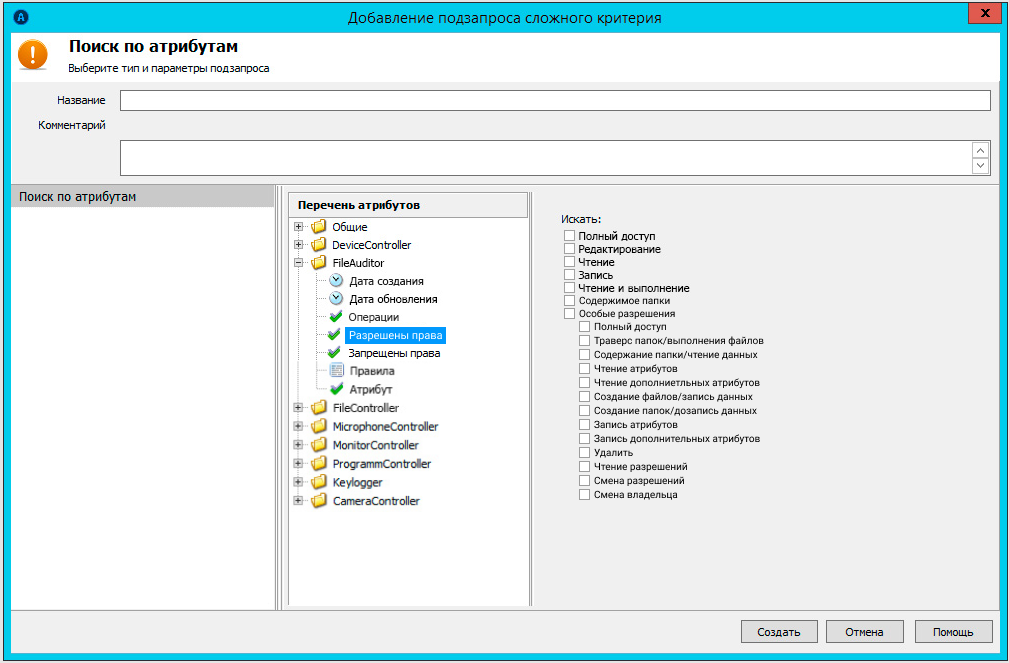
Поиск по атрибутам файла
На данный момент доступен поиск по 4 атрибутам:
· Имя файла.
· Размер.
· Дата создания.
· Дата изменения.

Тем самым, можно сфокусироваться не только на содержимом файла, но и на его «свежести». Например, искать только новые документы.
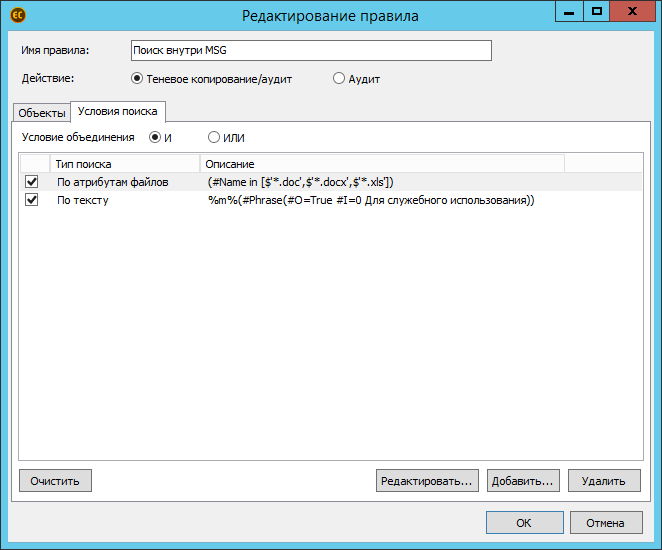
Может возникнуть вопрос: зачем здесь атрибут «Имя файла», если его и так можно задать в «Объектах»? Сделано это для того, чтобы решать задачу по поиску во вложенных документах. Поясню на примере. Изначально объектом выбраны файлы с расширением .msg. Будем искать сохранённую почту.

Но интересовать нас будут не все подряд письма, а лишь те, внутри которых есть вложение. Причём, определённого типа (.doc, .docx, .xls) и содержимого (обязательна фраза «Для служебного использования»).
Закономерно мог возникнуть вопрос: что будет, если придёт Ди Каприо и скажет «We need to go deeper»?
Всё будет в порядке. Поиск по атрибутам работает для любой вложенности, поэтому «счётчик уровней» в качестве отдельной опции добавлять не стали.
Поиск по регулярному выражению
Хорошо подходит для поиска структурированной информации. То есть таких данных, которые созданы по определённым правилам. Например, номер паспорта, номер телефона. Или локально придуманное только для вашей организации правило.

Регулярное выражение из скриншота выше ищет документы, содержащие слово «Изделие» (и его различные формы), затем допускается несколько «неучитываемых» символов. А следом обязательно должны быть 2 большие буквы из русского алфавита, 4 цифры и (опционально) одна маленькая буква. Тем самым, с помощью одного правила находим все вариации: и «Изделие ЛО3456х», и «Изделия АР1111».
Таким был путь от задумки в начале 2018 года. К августу 2019-го состоялся официальный релиз.
FileAuditor. Настоящее.
Сперва пару слов о доработках, которые были выполнены к релизу.
FileAuditor – самостоятельный продукт, который не конфликтует со сторонними системами. При этом он хорошо и бесшовно интегрируется с «СёрчИнформ КИБ».
Поддержаны и «агентский», и «сетевой» режимы работы. Как и в случае с DLP, у каждого из режимов есть свои плюсы и минусы. Так, агент может работать только с семейством Windows. В то же время многие хранилища работают на других ОС. И здесь на помощь приходит «сетевой» режим, для которого ни ОС, ни файловая система не важны. Важно лишь, чтобы служба могла «достучаться» до файлов по SMB. Также в сетевом режиме работы есть возможность взаимодействия с облачными сервисами хранения (Dropbox, Яндекс.Диск и др.), базами данных, системами документооборота и другими объектами ИТ-инфраструктуры.
Добавлена понятная статистика по сканированию. Чтобы наглядно было видно, чем сейчас заняты агенты и сетевая служба.

Можно задавать как общие правила анализа данных, так и персональные для отдельно взятой машины.
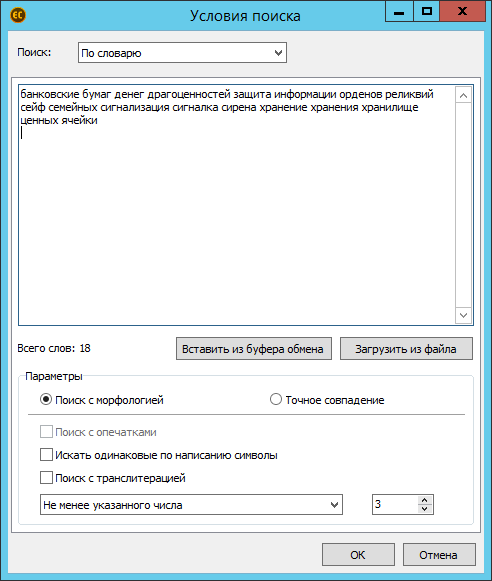
Добавился новый вид поиска – поиск по словарю, когда в файле ищется упоминание определённого количества слов.
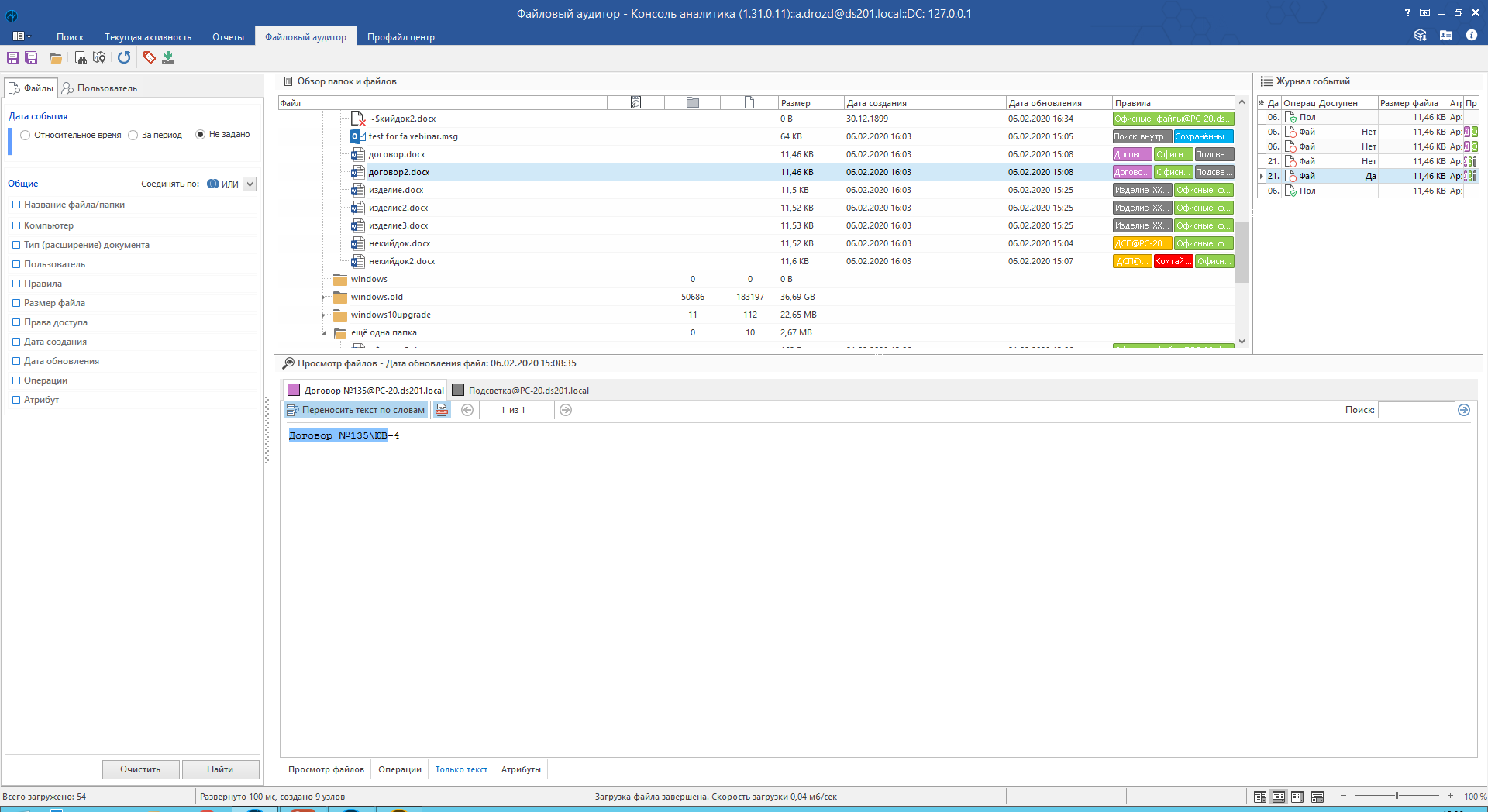
Рабочее пространство состоит из четырёх блоков:
1. Блок фильтров. Можно отобразить только нужное на данный момент: вывести список по определённому правилу, пользователю и т.д.
2. Блок поисковой выдачи. В него попадают папки и файлы, подошедшие под настроенные фильтры.
3. Блок журнала событий. Журнал ведётся для каждого файла. В случае контроля версий документов со стороны системы, переключения между версиями файла осуществляется именно из Журнала событий.
4. Блок просмотра. Совмещает в себе 3 режима просмотра. Поэтому рассмотрим его отдельно.
Режим «Просмотр файлов» позволяет глянуть файл в «родном» формате. Актуально для файлов, где для понимания содержимого важно видеть изначальное форматирование (например, таблицы Excel).
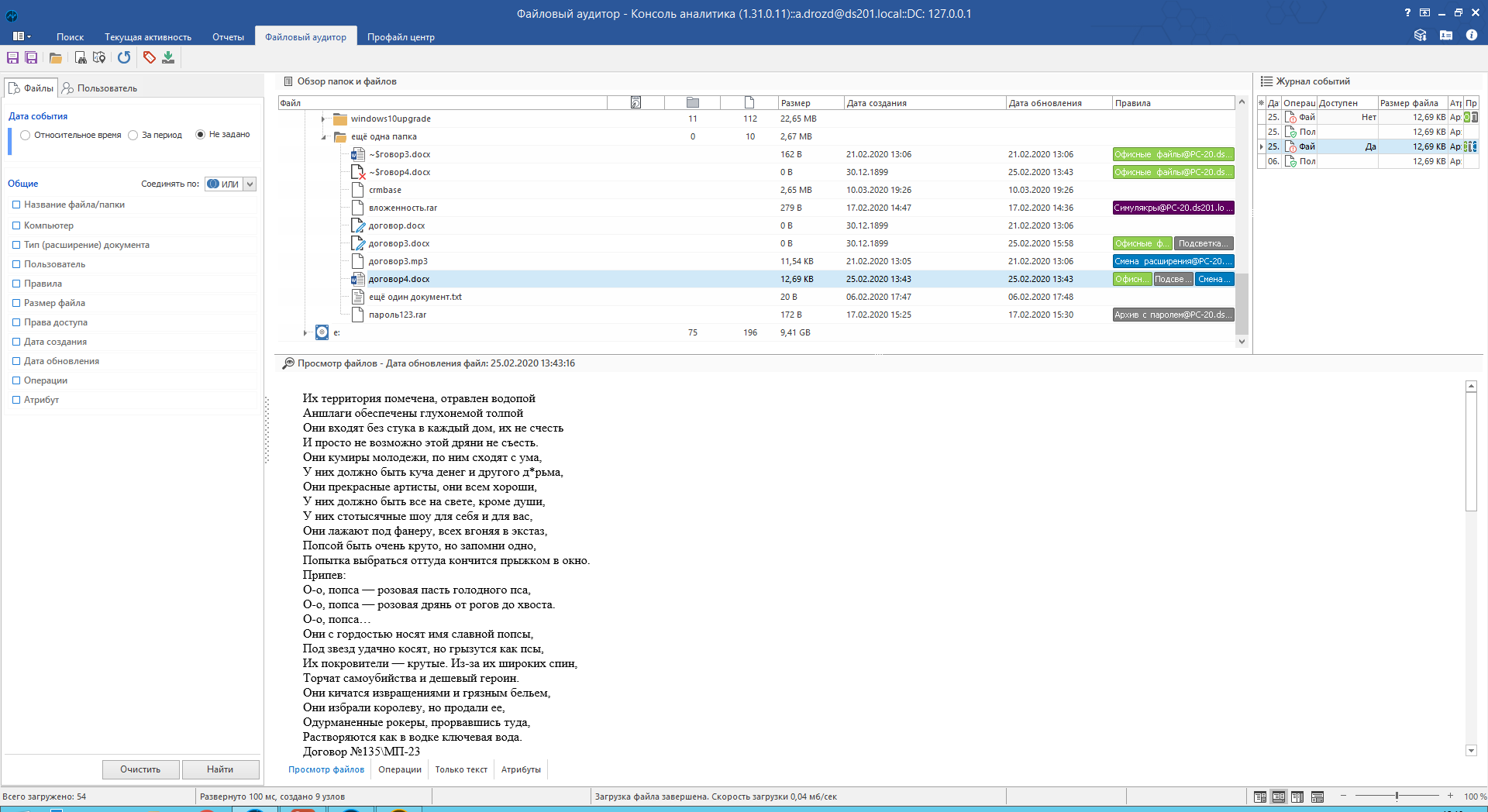
Режим «Только текст» показывает обработанный (проиндексированный) файл. Главная польза заключается в том, что система подсвечивает те места, по которым произошла сработка, и позволяет быстро «перескакивать» от одной сработки к другой. Актуально для больших многостраничных документов.
Сравните сами. Без подсветки:
И с ней:
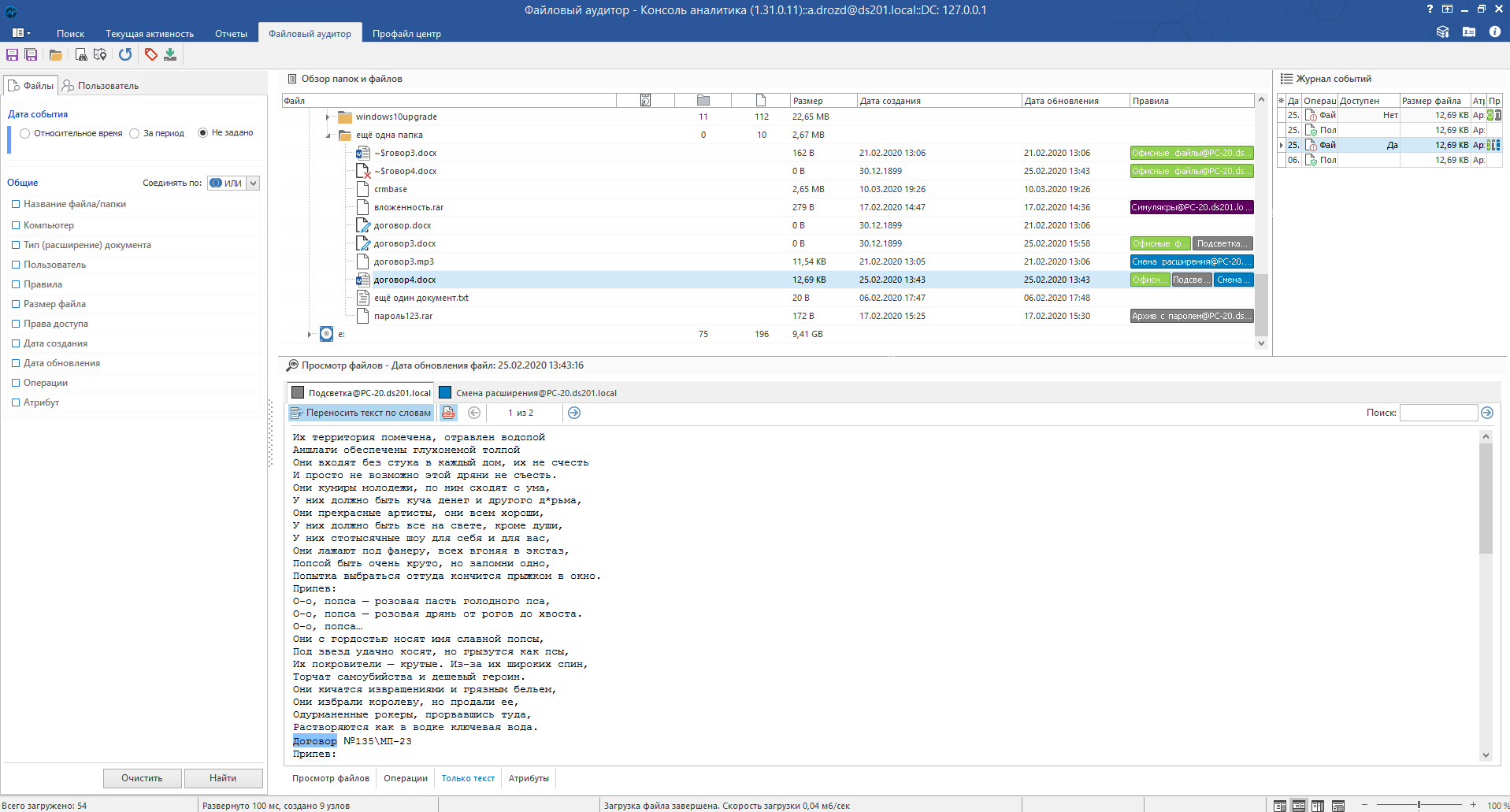
Сразу понятно, куда смотреть.
Если документ подпадает сразу под несколько правил, в режиме «Только текст» можно переключаться между результатами и смотреть, что «подсветилось» по каждому.


Тем самым, получаем обратную связь от системы для доработки правил аудита данных.
Режим «Операции» позволяет просматривать все операции, совершённые с файлом. Удобно, когда надо восстановить хронологию действий с документом.
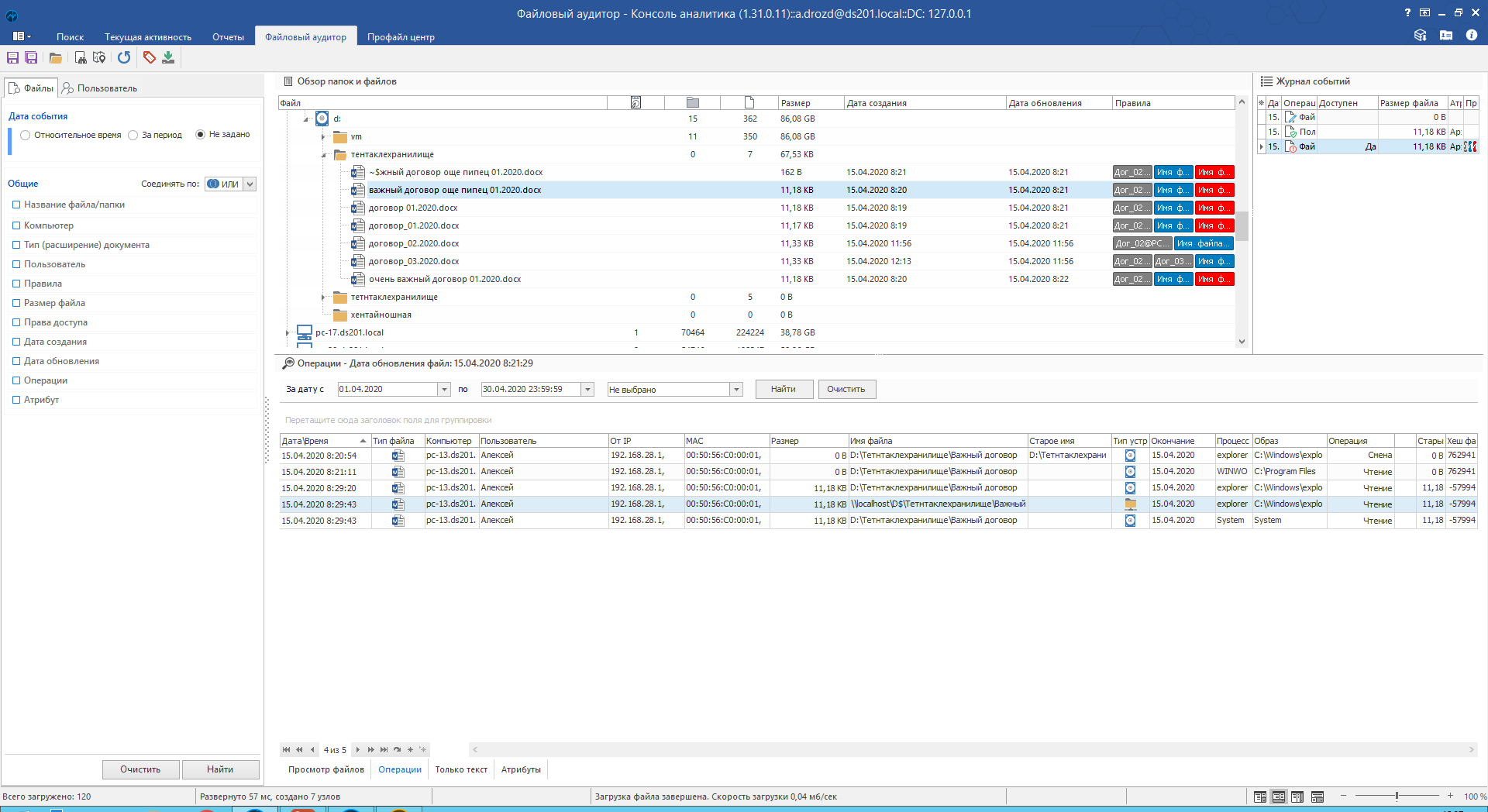
Ну и куда без прав доступа. Пригодится для наведения порядка.
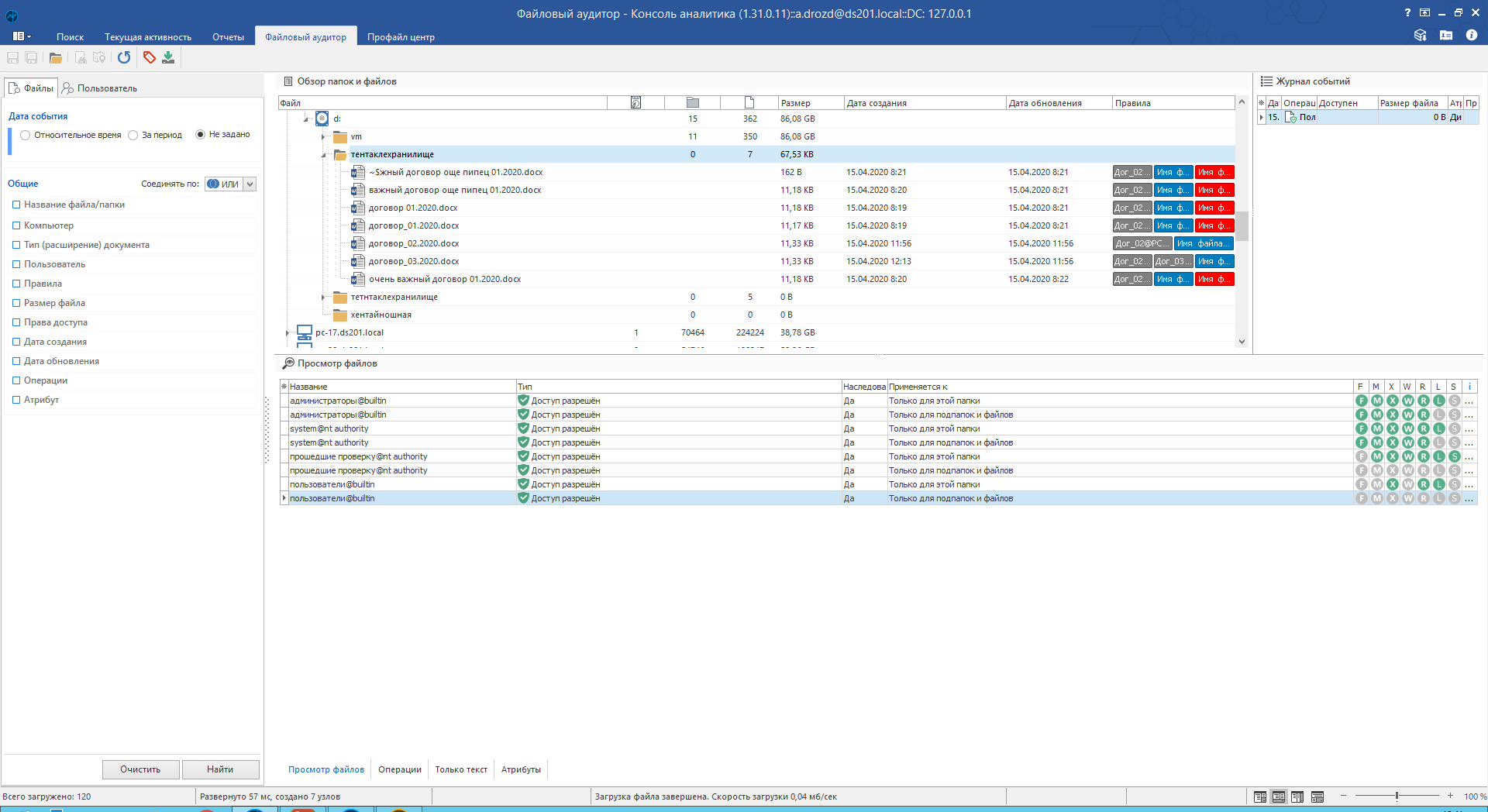
Интеграция с «КИБ» даёт FileAuditor’у дополнительные преимущества. По любому из файлов можно поискать файл в перехвате DLP-системы, а также сформировать по файлу контентный маршрут. Последний позволяет установить не только «нулевого пациента», с которого начал распространяться файл, но и всех «контактировавших» с этой информацией.
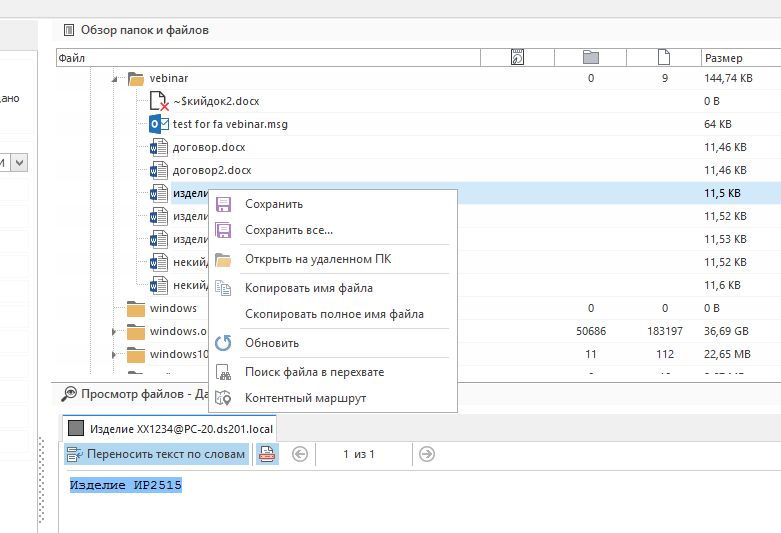
Для дополнительной автоматизации также есть интеграция с AlertCenter. Этот продукт входит в состав КИБ и отвечает за автоматическую проверку перехваченной информации по заданным поисковым запросам.
Этот симбиоз даёт больший простор для автоматизации. Из простого и очевидного: можно настроить получение уведомлений, если под правила FileAuditor’а попали новые файлы. Из более весёлого: AlertCenter позволяет к каждому созданному поисковому критерию подцепить выполнение внешнего скрипта. То есть в случае инцидента, система может отдавать определённые параметры скрипту, который даёт команду на запуск ядерных ракет.

FileAuditor. Будущее.
Очевидно, что продукту есть куда расти. И планы развития как минимум на пару лет уже расписаны. По понятным причинам приводить их здесь не хочется, чтобы не скатываться в продажи воздуха. А вот то, что уже оттестировано в боковых ветках и лишь ждёт намеченного часа, чтобы влиться в основной релиз, глянуть можно.
Самая значительная переработка коснулась поиска по регулярным выражениям. Одна донельзя неинформативная строчка превратилась в полноценный редактор. Есть и пояснения используемых квантификаторов, и область проверки. Добавили возможность создавать сложные регулярные выражения, состоящие из нескольких «простых».

Помните ранее в статье упоминалось, что FileAuditor ставит на файл «служебную» метку. Очень скоро настанет её звёздный час. На основе расставленных меток в «КИБ СёрчИнформ» можно будет создавать правила блокировок. Это значит, что передачу информации DLP сможет блокировать на лету по любым каналам, не нагружая при этом агент.
F. A. Q.
Что ж, хоть пост и получился объёмным, в нём нашли отражение далеко не все вопросы. Поэтому перечислим наиболее часто встречающиеся из них в блиц-формате вопрос-ответ.
1. Сильно тормозит машину?
Нет. Можно настроить так, чтобы сотрудник не почувствовал неудобств (проверка по расписанию, проверка только если загрузка ЦП меньше N%, проверка только в отсутствии активных сессий и т.д.).
2. Сколько места занимает перехват?
Может вообще не занимать, если вы включили только аудит данных. Если вы включили аудит и теневое копирование, то только тогда файлы, подпадающие под правила, будут копироваться в хранилище. В FileAuditor реализована система дедупликации. Если один и тот же файл, например, «разлетелся» по сети, то в хранилище будет лежать только один файл, а не 50.
3. В каком виде хранится перехваченная информация?
Все теневые копии передаются и хранятся только в зашифрованном виде.
4. Хранилище обязательно должно быть на том же сервере, что и остальная часть системы?
Нет. Можно указать любую сетевую папку, если вам надо.
5. Как долго идёт сканирование?
Принципиальный момент, первое ли это сканирование. Напомним, после первого сканирования агент уже фиксирует изменения и новые файлы. Если файл не менялся, агент это видит и не тратит на него время. Если же брать конкретные цифры, то на реальном тесте у клиента 70 ТБ в первый раз система индексировала порядка 10 дней. Второе сканирование этого же объёма заняло порядка 30 минут.
6. Со всеми форматами работаете?
Да (на самом деле нет). Зависит от самого правила. Если надо проверять содержимое файла, то мы ограничены теми форматами, которые на данный момент поддерживает SearchServer (порядка 150). Если же надо контролировать атрибуты (например, дата созданияизменения файла), то формат любой.

