
Проверка надежности Web приложений
Эта статья одна из трех публикаций, посвященных проверке надежности Web приложений. В первой части описывается проверка надежности и анализ Web приложений, способы организации их работы, взаимодействия с пользователями, а также стандартные ошибки разработчиков, способные дать доступ к данным и системе.
Эта статья одна из трех публикаций, посвященных проверке надежности Web приложений. В первой части описывается проверка надежности и анализ Web приложений, способы организации их работы, взаимодействия с пользователями, а также стандартные ошибки разработчиков, способные дать доступ к данным и системе.
Примичание: предполагается, что читатель знаком с архитектурой HTTP протокола, HTTP Get и Post запросами, и значениями полей заголовков. Эту информацию можно получить из RFC2616.
Web приложения становятся все более распространенными и еще в большей мере сложными, и, таким образом, важными для всех видов онлайн бизнеса. Наряду с общими вопросами безопасности, уязвимости в Web приложениях возникают в основном из-за некорректного запроса со стороны клиента и/или из-за недостаточной проверки вводимых данных, реализуемых на уровне приложений.
Истинную природу Web приложений – возможность сопоставлять, обрабатывать и распространять информацию по Интернет – можно реализовать двумя способами. Первый и самый очевидный – Web приложения доступны по своей природе всем. Это делает безопасность посредством сокрытия таких приложений невозможной и повышает требования к устойчивости кода. Второй, самый важный для перспективы проверки надежности; ведется передача элементов данных посредством HTTP запросов – протокола, который может выполнять множество задач по шифрованию и инкапсуляции.
Почти все среды разработки Web приложений (включая ASP и PHP, которые будут использоваться для примеров) предоставляют использование данных разработчику таким образом, что невозможно определить способ их перехвата, и вследствие, какой вид подтверждения и проверки должен быть использован. Поскольку среды разработок различны, и состоят из многих видов программируемого содержания, подтверждение ввода и логический контроль являются ключом к решению проблем с безопасностью Web приложений. Это касается и идентификации, и обеспечения верного домена для каждого определенного пользователем элемента данных, так же, как и полное понимание источника всех элементов данных для обозначения потенциальных данных, определенных пользователем.
Главная задача: Подтверждение ввода
Задачи подтверждения ввода могут вызвать сложности при расположении их в объемной базе с большим количеством взаимодействий пользователей между собой, что, собственно, и является главной причиной, принуждающей разработчиков использовать методологию проверки безопасности для решения этих проблем. Web приложения все же не имеют иммунитета к обычным формам атак. Непрофессиональные методы аутентификации, логические просчеты, непредусмотренное обнаружение скрытой информации, обычные бинарные ошибки приложений (переполнение буфера) встречаются очень часто. Анализируя Web приложения на предмет наличия уязвимостей, все вышесказанное должно учитываться; должны также применятся методичный процесс проверки ввода/вывода (метод «черного ящика»), по возможности, вместе с аудитом кода (методом «белого ящика»).
Что же на самом деле представляет из себя Web приложение?
Web приложение является приложением, включающим в себя набор скриптов, расположенных на Web сервере и взаимодействующих с базами данных или другими ресурсами динамического содержимого. Они становятся более распространенными, так как позволяют поставщикам услуг и их клиентам быстро обмениваться информацией часто, независимо от платформ, посредством инфраструктуры Интернета. Примерами таких приложения являются поисковые и почтовые системы, онлайн магазины и порталы.
Как это выглядит для пользователя?
Web приложения часто взаимодействуют с пользователями используя элементы ФОРМЫ и переменные GET или POST (даже кнопка «Нажми здесь» обычно является подтверждением формы). При использовании переменных GET данные из формы могут быть видны в самом URL запросе, в то время, как POST запросы требуют изучения кода страницы формы или перехвата и расшифровки запроса для получения данных, введенных пользователем.
Пример HTTP запроса для обычного Web приложения
| GET /sample.php?var=value&var2=value2 HTTP/1.1 |
| HTTP-METHOD REQUEST-URI PROTOCOL/VERSION |
| Session-ID: 361873127da673c |
| Session-ID Header |
| Host: www.webserver.com |
| Host Header |
| |
| Two carriage return line feeds |
Каждый элемент данного запроса может быть использован Web приложением, обрабатывающим данный запрос. REQUEST-URI указывает единицу кода, которая будет приведена в действие строкой запроса: перечень разделенных пар &variable=value обозначают параметры ввода. Это основная форма ввода данных для Web приложений. Заголовок Session-ID является обозначением установки сессии с клиентом как первичная форма аутентификации. Host Header обычно используется для различения виртуальных хостов, принадлежащих одному IP адресу и обычно фильтруется Web сервером, но находится, согласно теории, внутри домена Web приложения.
Для проверки надежности нужно использовать все возможные методы ввода, дабы вызвать критические условия для приложения. Не следует полагаться на ограниченные возможности, которые дают броузер или различные инструменты. Очень просто создавать HTTP запросы используя такие утилиты, как curl, или консольные скрипты пользуясь netcat. Процесс тестирования Web приложения, используя метод черного ящика, дает возможность обнаружить каждый элемент данных, определяя ожиданный ввод, взаимодействуя с ним и повреждая его, а также анализируя вывод приложения на предмет наличия нестандартного поведения.
Фаза сбора информации
Отпечатки
Один из первых шагов проверки надежности приложения – это определение среды его разработки и функционирования, включая язык скриптов, программное обеспечение Web сервера, операционную систему. Эти важные детали очень просто получить от сервера используя следующие методы:
1. Исследования ответа на HTTP запросы - HEAD и OPTIONS
Заголовок и любая страница полученная в следствии запроса HEAD или OPTIONS содержит обычно строку SERVER: или детальное описание версии программного обеспечения Web сервера, и, возможно, описание скриптов или операционной системы.
OPTIONS / HTTP/1.0
HTTP/1.1 200 OK
Server: Microsoft-IIS/5.0
Date: Wed, 04 Jun 2003 11:02:45 GMT
MS-Author-Via: DAV
Content-Length: 0
Accept-Ranges: none
DASL:
DAV: 1, 2
Public: OPTIONS, TRACE, GET, HEAD, DELETE, PUT, POST, COPY, MOVE, MKCOL, PROPFIND,
PROPPATCH, LOCK, UNLOCK, SEARCH
Allow: OPTIONS, TRACE, GET, HEAD, COPY, PROPFIND, SEARCH, LOCK, UNLOCK
Cache-Control: private
2. Исследование формата и надписей на страницах, сообщающих об ошибках (404/и другие)
Некоторые приложения (такие как ColdFusion) имеют стандартные, а значит, легко узнаваемые страницы сообщающие об ошибках и выдают версию программного обеспечения и язык скриптов. Исследователь должен внимательно изучить получаемые страницы и использовать полученную информацию от различных запросов(POST/PUT/и т.д.) для сбора информации о сервере.
Ниже приведен пример страницы, сообщающей об 404 ошибке приложения ColdFusion:
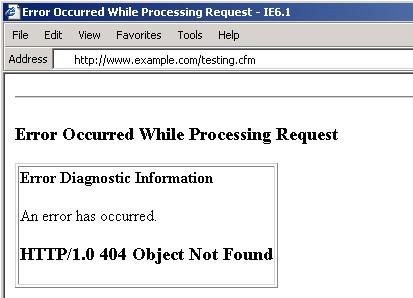
3. Тест на распознавание типов фалов/расширений/директорий
Многие Web сервисы (например Microsoft IIS) будут вести себя по разному на запрос к известному и поддерживаемому файловому разрешению и к неизвестному. Проверяющий должен попытаться запросить файлы с обычными разрешениями (ASP, .HTM, .PHP, .EXE) и проследить за необычными ответами или кодами ошибок.
GET /blah.idq HTTP/1.0 HTTP/1.1 200 OK Server: Microsoft-IIS/5.0 Date: Wed, 04 Jun 2003 11:12:24 GMT Content-Type: text/html <HTML>The IDQ file blah.idq could not be found.
4. Исследование исходных кодов доступных страниц.
Исходный код непосредственно доступных страниц может дать исчерпывающую информацию о приложении
<title>Home Page</title> <meta content="Microsoft Visual Studio 7.0" name="GENERATOR"> <meta content="C#" name="CODE_LANGUAGE"> <meta content="JavaScript" name="vs_defaultClientScript">
В данной ситуации разработчик, похоже, использует MS Visual Studio 7. Средой может быть, в данном случае, Microsoft IIS 5.0 с .NET framework.
5. Управление вводом для поиска ошибок в скриптах.
В данном примере очевидная переменная (ItemID) была изменена для наблюдения за Web приложением:
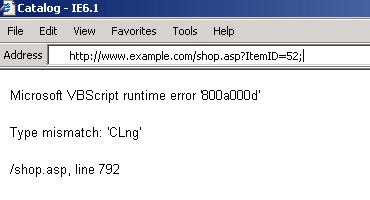
1. Отпечатки сервиса и TCP/ICMP
Используя обычные средства для снятия отпечатков - Nmap и Queso - или более популярные Amap и WebServerFP, проверяющий может получить более точные данные об операционной системе и Web приложении по отношению к другим методам. NMAP и Queso исследуют способ реализации TCP/IP данного хоста для определения сведений об операционной системе, в некоторых случаях, о версии ядра и патчах. Такие приложения полагаются на данные, полученные от HTTP заголовков сервера для определения ПО.
Скрытые элементы формы и анализ кода
Во многих случаях разработчики требуют защищенный от изменений ввод данных, таких, как переменные пользователя, которые создаются динамически, приписываются клиенту и требуются в дальнейших запросах. Для того, чтобы скрыть данные от глаз пользователя и возможно от их изменения, часто используются тэги в форме с атрибутом HIDDEN. К сожалению, эти тэги не видны лишь в представляющейся пользователю на обозрение части страницы, но их легко обнаружить, заглянув в сам код.
Существует множество примеров плохо написанных систем заказов, которые позволяют пользователям сохранять локально копию запроса подтверждаемой страницы, редактировать скрытые переменные, например, цену или счет за доставку, и повторно делать свой заказ. Web приложения не требуют аутентификации или поверки подтверждения формы и заказ может быть выполнен с большой скидкой!
<FORM METHOD="LINK" ACTION="/shop/checkout.htm"> <INPUT TYPE="HIDDEN" name="quoteprice" value="4.25">Quantity: <INPUT TYPE="text" NAME="totalnum"> <INPUT TYPE="submit" VALUE="Checkout"> </FORM>
Такие методы практикуются сейчас на многих сайтах. Обычно, в скрытых полях содержится нечувствительная информация, или данные в них зашифрованы. Небрежное отношение к информации в таких полях – способ изменения и управления данными для проверяющего.
Все коды страниц должны быть по возможности проанализированы на предмет обнаружения чувствительной или полезной информации, по невнимательности оставленной разработчиком – это могут быть активные элементы на странице, указатели на включенные или прилинкованные скрипты и содержание, неправильные разрешения на запись/чтение для файлов или каталогов. Все относительные приложения и скрипты должны быть проверенны, и по возможности, подробно рассмотрены.
Javascript и другие клиентские приложения могут также дать много информации о внутреннем устройстве Web приложения. Такую информацию можно получить пользуясь методом черного ящика. Также с помощью метода белого ящика (или аудита кода) можно получить доступ к логическому построению приложения. Для метода черного ящика эта информация является роскошью, которой следует воспользоваться для атак:
<INPUT TYPE="SUBMIT" onClick="
if (document.forms['product'].elements['quantity'].value >= 255) {
document.forms['product'].elements['quantity'].value='';
alert('Invalid quantity');
return false;
} else {
return true;
}
">
Предполагается, что приложение старается ограничить значение количества до 255 – максимального значения поля tinyint в большинстве СУБД. Было бы логично обойти клиентскую сторону проверки и вставить длинное числовое значение в переменную quantity запроса GET/POST, а затем проследить за действием приложения.
Определение механизма аутентификации
Один из больших недостатков Web приложений – отсутствие устойчивого механизма аутентификации. Самой частой ошибкой разработчиков является определение эффективности механизма аутентификации. Следует заметить, что условия проведения аутентификации зависят от протоколов, языков и форматов - HTTP, HTTPS, HTML, CSS, JavaScript, и т.д – используемых приложениями и зависящим от платформы, на которой работает приложение и от его архитектуры. НТТР обеспечивает два метода аутентификации Basic и Digest. Оба являются серией НТТР запросов и ответов, в которой клиент запрашивает ресурс, сервер требует аутентификацию, и клиент повторяет запрос согласно требованиям аутентификации. Разница между двумя методами аутентификации состоит в ном, что при методе Basic посылается серверу простой текст, а при Digest, хешированный, который используется сервером как криптографический ключ.
В природе проблемы передачи данных открытым текстом при использование метода Basic при НТТР аутентификации нет ничего неправильного, и эта проблема может быть решена использованием HTTPS. Проблема на самом деле заключается в двух вещах.
1. С тех пор, как Web сервер начал обрабатывать запрос на аутентификацию, сложно управлять Web приложением без взаимодействия с базой данных аутентификации Web сервера. Поэтому очень часто используются обычные методы аутентификации.
2. Разработчики часто делают ошибки в правильном определении к каждому средству доступа к ресурсу и соответственно используют неправильный алгоритм.
Проверяющий должен стараться выяснить сам механизм аутентификации и средство его применения к каждому ресурсу Web приложения. Многие среды разработок для Web предлагают возможность использования сессий, где пользователю записывается куки, или НТТР заголовок Session-ID содержит псевдо-уникальную строку для идентификации их статуса. Такие средства могут быть уязвимыми к таким атакам, как брутфорс, разбор строки, если она состоит из просто из хеша или связанной строки из известных элементов.
Каждая попытка должна быть сделана с целью получить доступ к ресурсу используя каждую входную точку. Проблемы возникнут, если ресурсы уровня администратора требуют аутентификацию, как например главное меню, или страница портала с последующими уровнями. Например, Web приложение осуществляет доступ ко многим документам для прошедшего аутентификацию пользователя, каждый документ представлен ссылкой на ресурс:
http://www.server.com/showdoc.asp?docid=10
Также, для доступа к меню требуется аутентификация, скрипт showdoc.asp сам по себе не требует аутентификации и предоставляет любому нужный документ. Это может позволить атакующему просто указать id документа и в GET запросе и получить желаемую страницу. Как элементарно это не звучит, но эта ошибка самая частая.
Заключение
В этой статье мы описали методы проверки надежности и в целом рассмотрели структуру Web приложений, а также методы контроля ввода данных со стороны пользователей. Мы также показали важность использования отпечатков для целевой среды и понимания скрытой части Web приложений. Вооружившись этой информацией, проверяющий сможет провести ряд тесов для поиска и использования уязвимостей. Следующие статьи этого цикла опишут способы атак посредством изменения кода и содержания, таких, как PHP/ASP code injection, SQL injection, Server-Side Includes и межсайтовый скриптинг..