
IAMeter: не ошибается ли SAST-сканер?
SAST (static application security testing) — способ тестирования приложений на безопасность методом белого ящика. Это означает, что анализатору необходим исходный код проверяемого приложения, однако, в отличие от методов серого или черного ящика, этот исходный код необязательно должен работать или вообще собираться, потому что SAST в процессе анализа не запускает проверяемое приложение.

Довольно часто можно услышать, что при использовании SAST возникает много ложных срабатываний. Ошибочные результаты можно разделить на две группы:
- False positive — ситуация, когда на самом деле уязвимости нет в коде, но анализатор сообщает о ней. Такие срабатывания, особенно в большом количестве, отнимают много времени у тех, кто разбирает результаты анализа: есть вероятность пропустить верное срабатывание или окончательно потерять доверие к результатам.
- False negative — ситуация, когда уязвимость есть в коде, но анализатор не сообщает о ней. Это еще хуже: уязвимость, несмотря на попытку ее найти, остается.
Как можно оценить качество работы SAST-инструмента? Ответ простой: посмотреть на количество false positive и false negative срабатываний на заранее подготовленном уязвимом приложении.
IAMeter: что это и зачем
Мы выложили в открытый доступ на GitHub новую версию IAMeter — уязвимого приложения, созданного специально для оценки эффективности SAST-анализаторов. В этой статье все примеры будут для языка PHP, но постепенно мы будем добавлять в репозиторий и другие языки
Может возникнуть вопрос, зачем еще одно приложение, если похожих уже достаточно (xvwa, dvwa, OWASPWebGoatPHP …). IAMeter имеет важное от них отличие: его целью является не имитирование случайно допущенных уязвимостей в исходном коде приложений, а целенаправленное использование семантически сложных конструкций. Такой бенчмарк позволит в по-настоящему тяжелых, но не оторванных от реальности условиях проверить SAST-анализатор. Именно из-за неспособности многих анализаторов белого ящика эмулировать семантически сложное поведение и сложилось мнение о сильно «фолзящем» SAST-анализе.
Ложные срабатывания случаются по многим причинам, но самые частые из них — это отсутствие информации о возможных уязвимостях в базе знаний инструмента и несовершенство самого алгоритма анализа. IAMeter призван проверить второе: не ширину охвата знаний анализатора, а качество используемой технологии.
Но почему некоторые анализаторы выдают ложные срабатывания? Давайте залезем «под капот» SAST-инструментов и узнаем, как выбранный способ анализа влияет на качество результата.
Как анализируется исходный код
Статический анализ программного обеспечения существует уже достаточно давно и успел обзавестись различными методиками. В этом разделе мы рассмотрим самые популярные технологии, применяемые в SAST-инструментах.
Поиск по шаблонам
Поиск по шаблонам, или сигнатурный анализ, — это то, что приходит в голову, если возникает задача найти какие-либо свойства исходного кода. Что может быть проще, чем написать регулярное выражение для поиска определенных моментов или дефектов? Такой подход основан на поиске заданных шаблонов, причем они могут быть заданы не только регулярным выражением, но и другими методами описания. Поиск также может производиться не только на строковом представлении исходного кода, но и, например, на потоке токенов или абстрактном синтаксическом дереве (слово «абстрактный» означает, что в таком дереве не представлены не значимые для анализа конструкции языка, например пробелы или комментарии).

Пример абстрактного синтаксического дерева
Недостатки такого подхода достаточно очевидны: он не учитывает семантику анализируемого приложения и уж тем более поток выполнения. Поэтому такой вид анализа достаточно неточен: в результате он имеет много ложных срабатываний. Однако стоит отметить, что поиск по шаблонам проходит относительно быстро, так как имеет линейную сложность.
Поиску по шаблонам посвящен цикл статей Positive Technologies, мы же пойдем дальше.
Анализ потока данных
Анализ потока данных, или taint-анализ, использует уже более сложные представления исходного кода. Например, граф потока данных (поток данных — множество возможных путей следования данных внутри программы), граф потока управления (поток управления — множество возможных путей выполнения программы) или различные их комбинации. Taint-анализ находит в коде зараженные данные (те, на которые может повлиять злоумышленник) и отслеживает все пути их распространения. Затем, если данные, которые как-то были связаны с зараженными, попадают в место потенциальной уязвимости, то об этой уязвимости сообщается в результатах анализа.
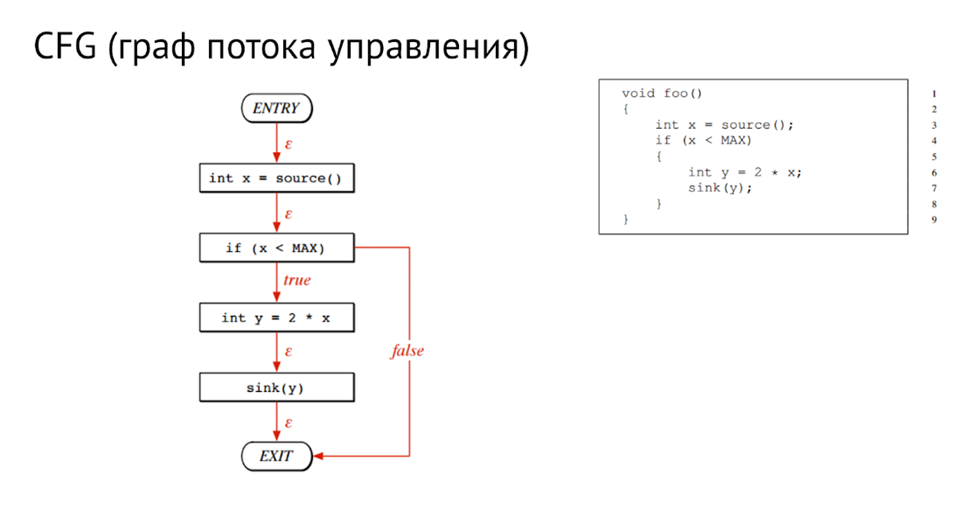
Пример графа потока управления
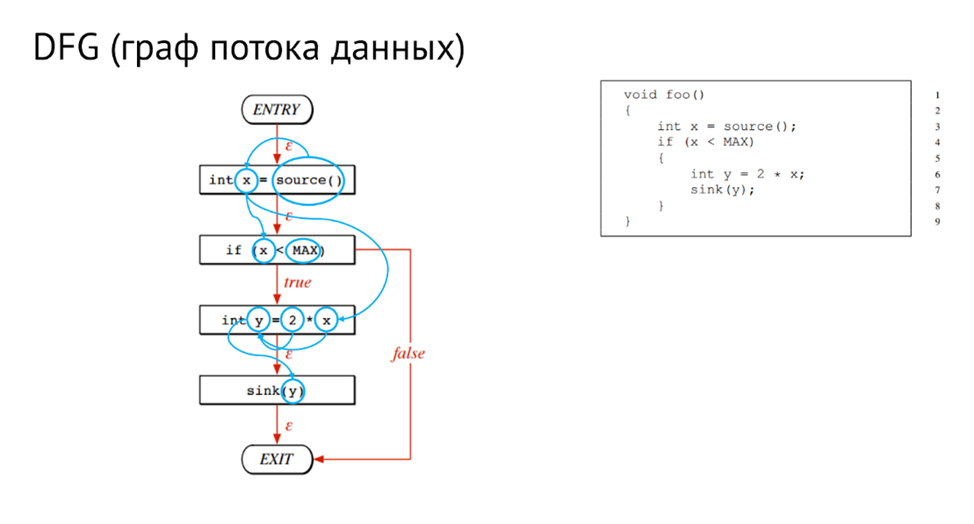
Пример графа потока данных
Такой подход дает уже меньше ложных срабатываний, чем поиск по шаблонам, однако и он бывает неправ. Taint-анализ не учитывает условия достижимости путей выполнения и следует по всем ветвям, даже заведомо недостижимым. Кроме того, информация о том, может ли контролируемый извне поток данных достичь точки выполнения, которая потенциально приводит к уязвимости, не отвечает на вопросы о том, насколько сильно этот зараженный поток будет изменен, способен ли он привести к негативным последствиям и может ли такая ситуация вообще произойти.
Символьное исполнение
На все эти вопросы помогает ответить технология символьного исполнения (symbolic execution), лежащая в основе большинства перспективных направлений статического анализа.
В этой технологии все входные данные становятся неизвестными переменными (символьными значениями), а затем происходит абстрактная интерпретация (аппроксимация семантики) без конкретного вычисления анализируемой программы. Это позволяет построить достаточно подробное представление заданной программы — граф потока вычисления. Из такого представления становится возможным получить в каждой точке выполнения программы условия, при которых эта точка будет достигнута, а также все значения переменных под теми условиями, под которыми они будут доступны в данном месте.
Рассмотрим для примера следующий код:
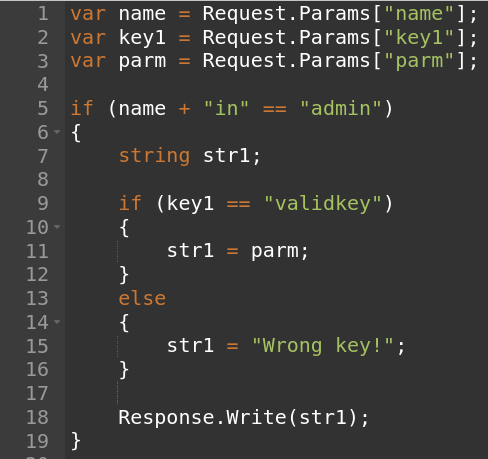
Уязвимый код
В коде берутся три параметра запроса (name, key1, parm), производятся некоторые действия, а затем строка str1 пишется в ответ сервера. Есть подозрение на уязвимость для XSS в строке 18. Чтобы проверить это подозрение, подумаем о том, как будет выглядеть граф потока вычисления в данной точке выполнения программы.
Программа дойдет до строки 18, только если name + “in” == “admin”. Это будет условием достижимости пути. Переменная str1, записываемая в ответ сервера, будет иметь значение parm, если key1 == “validkey”, иначе — “Wrong key!”. Поскольку переменная parm является значением параметра GET-запроса, на эти данные может повлиять злоумышленник. В результате состояние потока вычисления на строке 18 можно описать следующим образом:
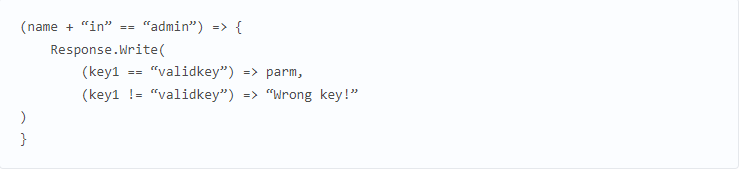
Имея граф потока вычисления, можно сказать, есть ли уязвимость в конкретной точке выполнения программы: необходимо решить уравнения, основанные на приравнивании вектора атаки и символьных выражений, пришедших в потенциально опасную операцию. Ответ находится несколькими способами: такую символьную формулу можно попросить вычислить SMT-решатель (satisfiability modulo theories — задача разрешимости формул, заданных в различных теориях, например целых чисел или строк) или, если известна обратная функция для заданной, можно запустить эту обратную функцию и получить настоящий результат.
Составим для нашего примера уравнение, которое отдадим SMT-решателю Z3. Попробовать его в деле можно на Z3 Online Demonstrator или Z3 Playground. Для начала объявим константы, обозначающие параметры запроса:
(declare-const name String) (declare-const key1 String) (declare-const parm String)
Затем запишем условие достижимости пути: (assert (= (str.++ name "in") "admin"))
Поскольку SMT имеет префиксную форму записи, операторы располагаются перед своими операндами. В приведенном assert мы требуем, чтобы конкатенация name и строки “in” была равна строке “admin”.
Также потребуем, чтобы то, что попадает в потенциально опасную операцию Response.Write, было равно вектору атаки. Для уязвимости XSS вектором атаки будем считать строку
"<script>alert(0)</script>":

Оператор ite представляет собой аналог инструкции if-then-else.
И попросим решение нашего уравнения:
( check-sat) (get-model)
Z3 представил такой результат:
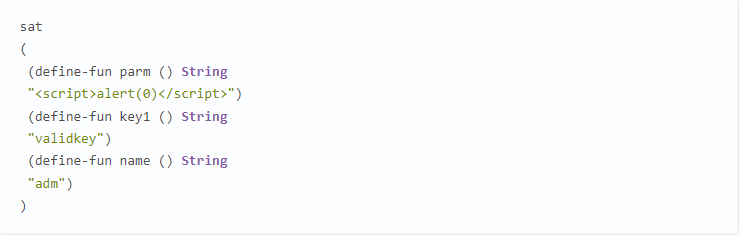
Понимаем, что уязвимость достижима, а также видим значения параметров, которые необходимо передать в запросе для эксплуатации уязвимости в приведенном фрагменте кода.
Описанный выше подход гарантирует минимальное количество ложных срабатываний, потому что решает условия достижимости уязвимостей и достаточно подробно эмулирует семантику анализируемого языка, а также позволяет получить дополнительную информацию о найденной уязвимости: работающий эксплойт или условия, при которых приведенный эксплойт будет работать.
Подробнее про технологию символьного исполнения в SAST-анализаторах можно посмотреть в записи доклада Владимира Кочеткова, руководителя отдела исследований и разработки анализаторов кода Positive Technologies.
А теперь опробуем анализатор, использующий символьное исполнение, на IAMeter, а заодно подробнее разберем те самые каверзные случаи, загоняющие инструменты в тупик.
Проверка символьного исполнения на IAMeter
Сканировать IAMeter будем анализатором PT Application Inspector, использующим «под капотом» символьное исполнение.
Для этого установим плагин для своей среды разработки (IntelliJ-based или VSCode) и запустим сканирование.
Процесс сканирования проекта
В результате анализатор нашел 12 уязвимостей:
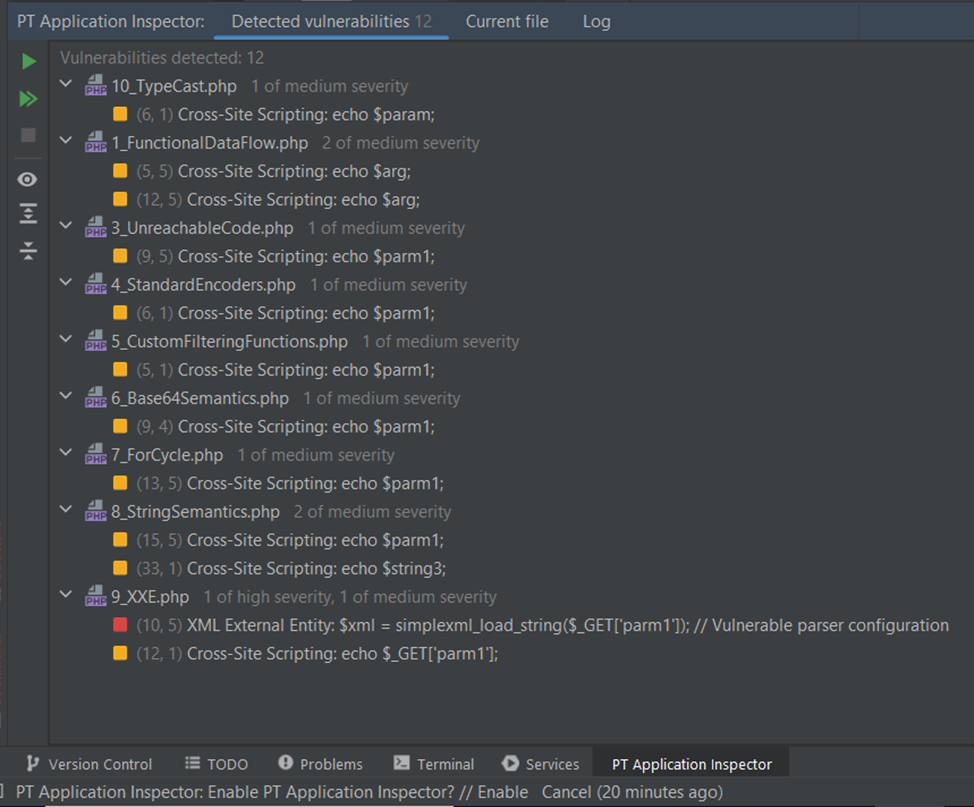
Найденные уязвимости
Попробуем разобраться в результатах сканирования. Начнем с файла UnreachableCode.
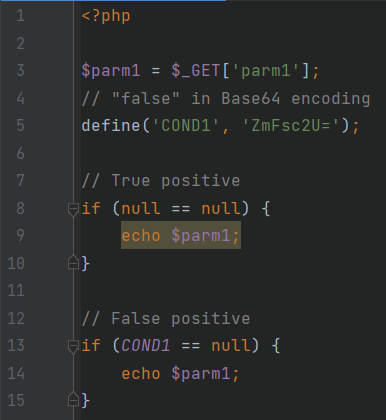
UnreachableCode.php
В нем, как и во многих других примерах, данные, на которые потенциально может повлиять злоумышленник (TDE), попадают в программу через получение параметра GET-запроса на строке 3. Опасной же операцией (PVO), в которую не должны попасть зараженные данные, считается вызов echo на строках 9 и 14. В первом случае на строке 9 уязвимость достигается в том случае, если null == null, что всегда является правдой, а значит, уязвимость действительно существует. Уязвимость на строке 14 достигается, если константа COND1 является null, но такого не может произойти, потому что она представляет собой зашифрованную в Base64 строку ‘false’. Анализаторы, которые игнорируют условия достижимости путей выполнения программы, сообщат об уязвимости в этом месте, что окажется ложноположительным результатом. PT Application Inspector же доказал, что уязвимости в этом месте нет.
Стандартная библиотека
В этом разделе рассмотрим примеры, в которых анализатор должен иметь представление о стандартной библиотеке языка, чтобы безошибочно обнаруживать уязвимости.
Посмотрим на файл Base64Semantics.
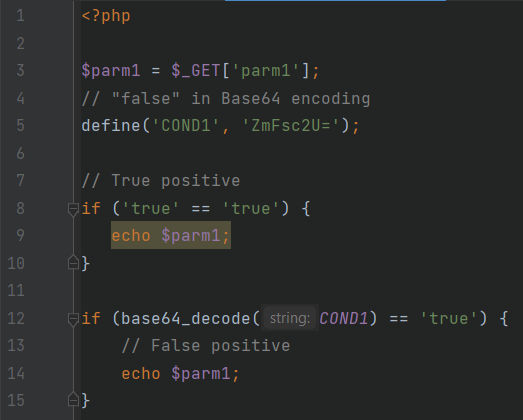
Base64Semantics.php
Он напоминает предыдущий пример, но проверка перед действительной уязвимостью выглядит как ‘true’ == ‘true’, что тоже всегда является правдой, а перед ложноположительной здесь выглядит иначе: ветка выполняется только в том случае, если константа COND1 при декодировании из Base64 является строкой ‘true’, что в нашем случае не является правдой. Анализаторы, которые не способны эмулировать семантику функций стандартной библиотеки языка, как в данном примере base64_decode, сообщат об уязвимости, что будет ложноположительным результатом.
В следующем файле проверяется наличие уязвимости XXE, которая будет действительной только при небезопасной настройке парсера.
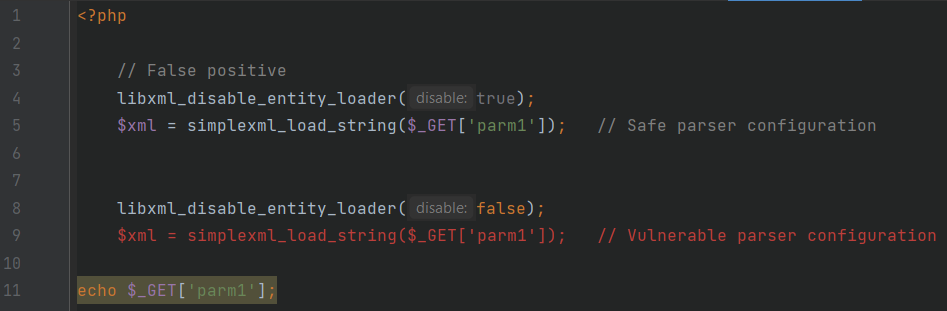
XXE.php
Так, после отключения загрузки внешних сущностей на строке 4 вызов XML-парсера, пусть и с потенциально зараженными данными, на строке 5 является безопасным. Чего не скажешь о таком же вызове на строке 9: так как загрузка внешних сущностей была разрешена на строке 8, это приводит к уязвимости XML External Entity, о чем нам и сообщает PT Application Inspector. Хороший анализатор должен уметь отслеживать состояние параметров сущностей стандартной библиотеки.
В качестве заключительного примера в этой группе посмотрим на файл StringSemantics. В нем содержится три примера, разберем их поэтапно.
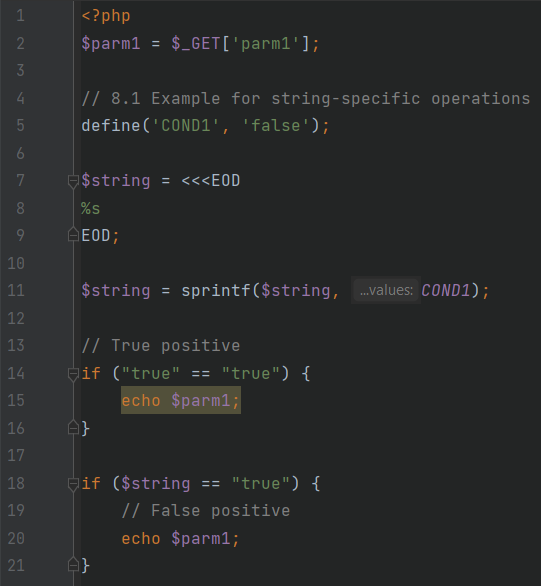
StringSemantics.php
Этот пример похож на разобранные ранее: уязвимость на строке 20 достижима только в том случае, если $string окажется равным “true”. Анализатор должен отследить все операции над переменной $string и учесть все ее возможные состояния. В нашем случае переменная не может оказаться “true”, поэтому уязвимость недостижима.
Два примера ниже демонстрируют случай, когда над зараженными данными происходит операция поиска и замены по регулярному выражению.
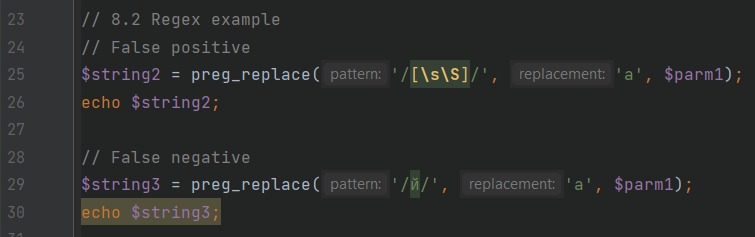
StringSemantics.php
В первом случае, на строке 25, все символы строки заменяются на безопасный символ, поэтому уязвимости на строке 26 нет, в отличие от примера на строке 30, где на безопасный заменяется только один конкретный символ. Статическому анализатору важно достаточно точно эмулировать семантику поведения типа string, потому что чаще всего для инъекций именно экземпляр строки является вектором атаки.
Фильтрующие функции
При правильном применении фильтрующих функций можно избежать попадания действительных векторов атаки в потенциально опасный вызов.
В примере StandartEncoders благодаря использованию фильтрующих функций из стандартной библиотеки urlencode, htmlspecialchars и htmlentities удается отфильтровать действительные векторы атак и избежать уязвимостей.
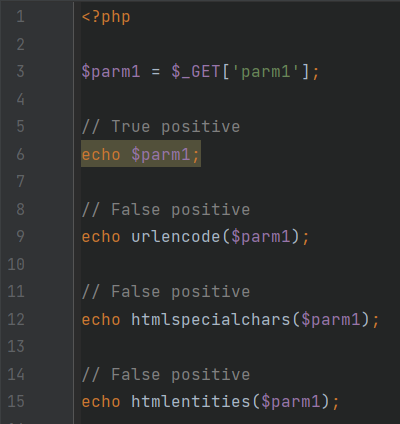
StandartEncoders.php
Фильтрующие функции могут быть написаны и самостоятельно, это демонстрируется в примере CustomFilteringFunctions.
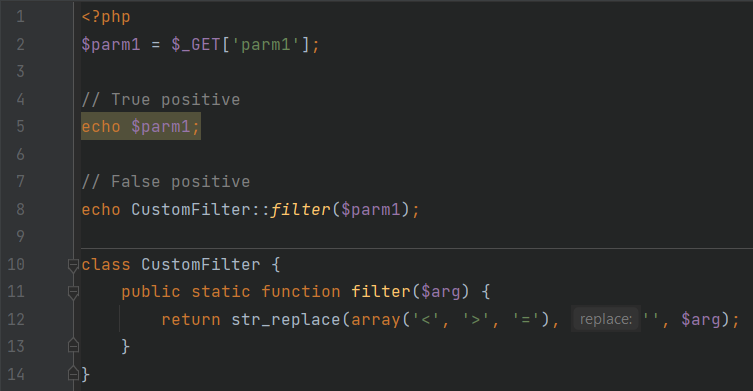
CustomFilteringFunctions.php
На строке 8 зараженные данные попадают в PVO после предварительной фильтрации реализованной ниже функцией filter. Эта функция также отсекает опасные данные, путем удаления специальных символов из заданного набора, поэтому уязвимость в этом месте не должна быть найдена.
Конструкции языка
В заключительном разделе рассмотрим случаи, когда важно правильно эмулировать конструкции анализируемого языка программирования.
Несложный для понимания, но сложный для некоторых видов анализа пример называется TypeCast.
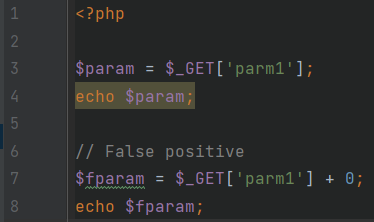
TypeCast.php
В нем содержится два PVO: на строке 4, которая действительно является достижимой уязвимостью XSS, о чем нам и сообщает PT Application Inspector, подсвечивая этот код желтым цветом, — и на строке 8. Во втором случае уязвимость недостижима из-за того, что $fparam преобразуется к численному типу, но может быть зарепорчена taint-анализом, который пренебрегает такой семантикой и просто отслеживает пути распространения «зараженных» данных.
Пример ForCycle демонстрирует нам важную проблему статического анализа.
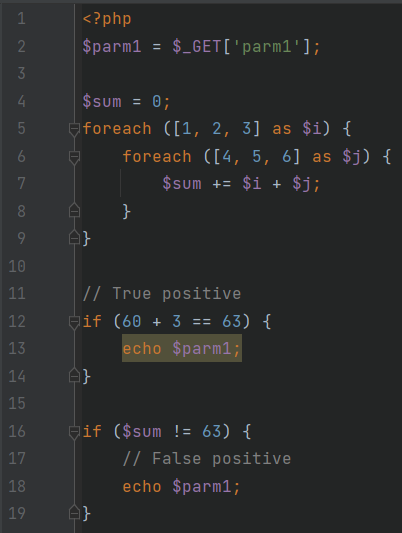
ForCycle.php
Эта проблема заключается в выборе подхода для обработки циклов, они на пару с рекурсией могут значительно увеличить сложность алгоритма анализа. Выбор метода обработки циклов позволяет найти баланс между точностью и производительностью анализатора. Так, в приведенном примере анализаторы, которые игнорируют или недостаточно точно аппроксимируют циклы, сообщат об уязвимости на строке 18, но на самом деле ее там нет, потому что значение переменной $sum будет равняться 63.
Еще один пример показателен для языков, в которых функции являются объектами первого класса. Это означает, что их можно передать как параметр или присвоить переменной.
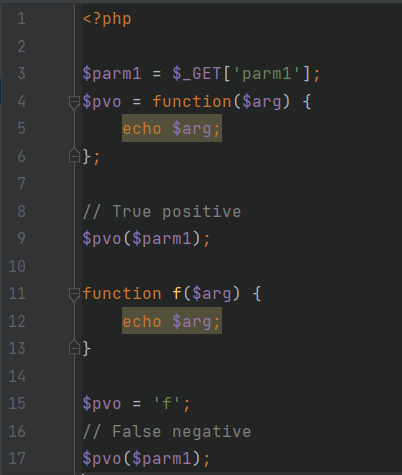
FunctionalDataFlow.php
При таком взаимодействии с функциями анализатор может запутаться и недостоверно построить поток выполнения программы, упустив уязвимости на строках 5 и 12.
Последним примером будет весьма интересный случай.

BrokenCode.php
Интересен он тем, что в нем приведен недействительный код. UnknownType нигде не определен, о чем нам подсказывает IDE. Невалидный код не может быть уязвимым, однако анализаторы, которые это игнорируют, найдут уязвимость в строке 17.
Подводя итоги
Мы поговорили про SAST — технологию, которая позволяет сэкономить много времени и денег, находя уязвимости на ранних этапах разработки. Но выяснилось, что некоторые методики анализа, наоборот, не экономят, а только отнимают ресурсы, выдавая большое количество ложных срабатываний, или еще хуже — не находят то, что должны.
Просканировав наш уязвимый проект IAMeter анализатором PT Application Inspector, использующим технологию символьного исполнения, мы убедились, что SAST вполне может быть как точным, так и полным одновременно, — нашлись все настоящие уязвимости, но не было срабатываний на заведомо ложных.