
Строим защиту от парсинга. Часть 1: основные принципы предотвращения парсинга
Сбор больших объемов пользовательских данных третьими лицами может привести к крупным штрафам, ущербу для репутации и вреду для пользователей. Поэтому администраторам необходимо знать техники предотвращения скрапинга данных и защиты от злонамеренного сбора информации.

Скрейпинг (парсинг) – автоматизированное извлечение данных из веб-приложений. Существует множество мотивов для парсинга: от хакеров, пытающихся собрать большое количество телефонных номеров и адресов электронной почты для последующей продажи, до правоохранительных органов, извлекающих фотографии и пользовательские данные из социальных сетей, чтобы помочь в раскрытии дел о пропавших без вести.
Защита от парсинга (Anti-Scraping) относится к набору тактик, техник и процедур (Tactics, Techniques and Procedures, TTPs), направленных на то, чтобы максимально затруднить сбор данных. Хотя полностью предотвратить скрейпинг невозможно, усложнение парсерам обход защиты приложения, скорее всего, отпугнет злоумышленника.
Основные принципы защиты от парсинга
В технике Anti-Scraping есть 5 основных принципов:
- Требование аутентификации;
- Установка ограничения количества запросов (Rate Limits);
- Блокировка создания аккаунтов;
- Установка ограничения на данные;
- Возврат сообщений об ошибках.
Принципы могут показаться простыми в теории, но на практике они становятся все более сложными с увеличением масштаба. Защита приложения на одном сервере с сотнями пользователей и десятью конечных точек — вполне решаемая задача.
Однако работа с несколькими приложениями, разбросанными по глобальным дата-центрам с миллионами одновременных пользователей, — это совершенно другое дело. Кроме того, любой из принципов, принятый неправильно, может помешать работе пользователя.
Если установить ограничение количества запросов, то сколько именно запросов в минуту пользователь может отправлять? Если ограничение слишком строгое, то обычный пользователь не сможет использовать приложение, что неприемлемо для бизнеса. Надеемся, что дальнейшее углубление в эти темы поможет понять, какие решения организации могут попытаться внедрить, и какие препятствия могут возникнуть на пути.
Поддельный сайт
Поддельный сайт с публикациями пользователей будет использоваться для демонстрации взаимодействия между защитниками, усиливающими защиту своего приложения, и парсерами, обходящими эти средства защиты. Все пользователи и данные были сгенерированы случайным образом. Приложение имеет типичные рабочие процессы входа в систему, создания учетной записи и восстановления забытого пароля.
После входа в приложение пользователю показываются 8 рекомендованных постов. В правом верхнем углу есть панель поиска, которую можно использовать для поиска конкретных пользователей.
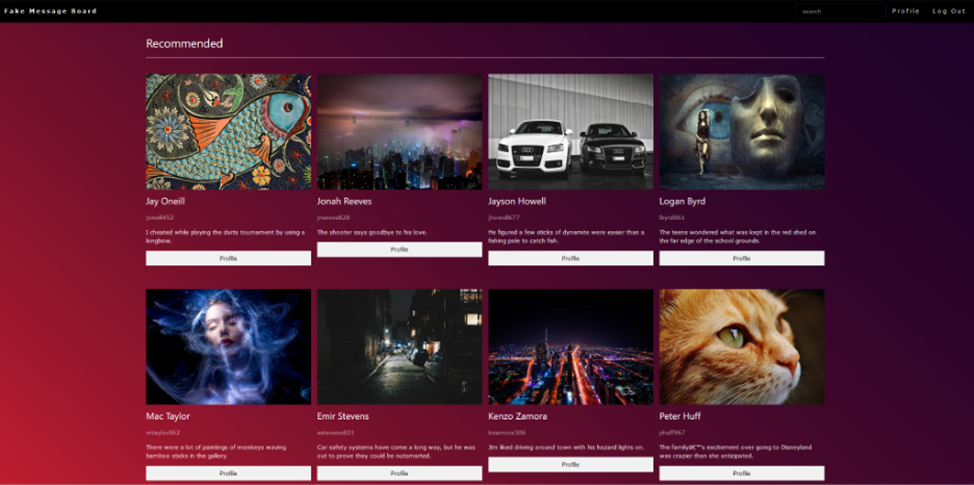
Кроме того, у каждого пользователя есть страница профиля с информацией о нём (имя, email-адрес, биография, дата рождения, номер телефона) и его постах (дата, содержание, комментарии).
Попыток ограничить скрейпинг не предпринималось. Давайте посмотрим, насколько сложно собрать все 500 000 фальшивых пользователей на платформе.
Действия парсера
Одним из первых шагов парсера будет проксирование трафика для веб-приложения с помощью инструмента Burp Suite. Цель состоит в том, чтобы найти конечные точки, которые возвращают пользовательские данные. В этом случае есть несколько разных областей приложения, на которые стоит обратить внимание:
- Функциональность рекомендуемых постов;
- Панель поиска;
- Страницы профиля пользователя;
- Создание аккаунта;
- Функция восстановления забытого пароля.
Функциональность рекомендуемых постов
Функциональность рекомендуемых постов возвращает 8 разных постов при каждом обновлении домашней страницы. Как показано ниже, пользовательские данные встроены в HTML.
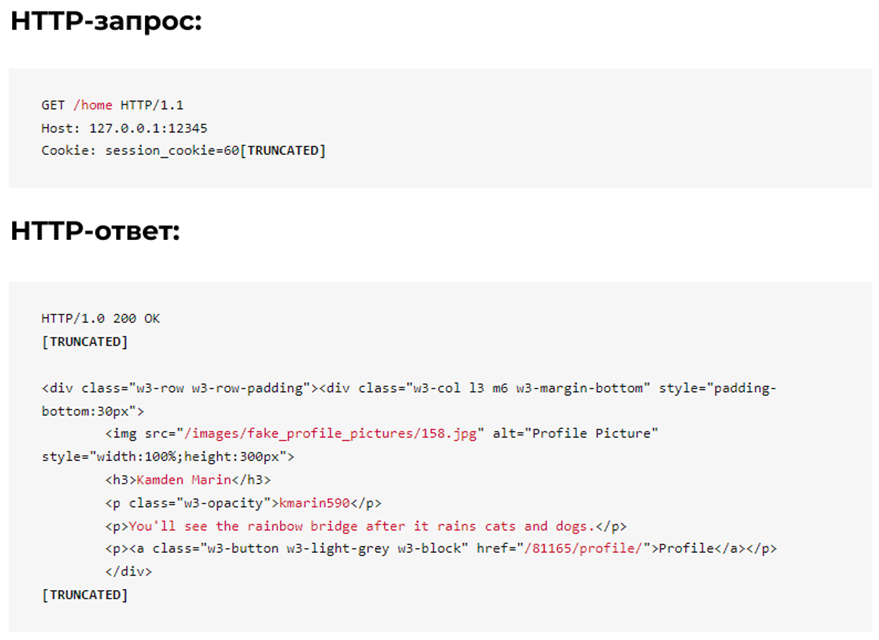
Как парсер, пытающийся выяснить, на какую конечную точку нацелиться, вот несколько ключевых вопросов, которые мы можем себе задать:
- Требуется ли аутентификация: Да;
- Сколько данных возвращается: 8 пользователей/ответ;
- Какие данные возвращаются: идентификатор пользователя, имя, никнейм, биография;
- Легко ли анализировать данные: легко, в HTML.
Панель поиска
Панель поиска по умолчанию возвращает 8 пользователей, связанных с указанным поисковым запросом. Как показано ниже, у поиска есть несколько интересных аспектов.
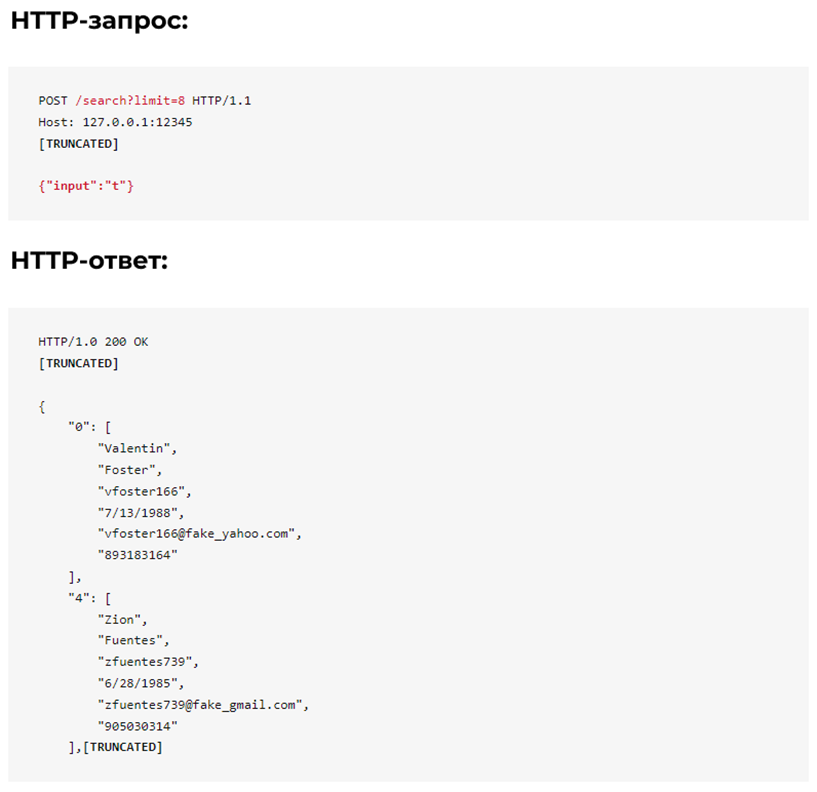
Одна из первых функций, которую необходимо проверить, — требуется ли аутентификация. В этом случае сервер по-прежнему возвращает данные даже после удаления cookie-файла сеанса пользователя. Кроме того, каждый параметр, который сообщает серверу, сколько данных нужно вернуть, является потенциальной целью для парсера.
Что произойдет, если мы увеличим параметр «limit» с 8 до более высокого значения? Есть ли максимальный предел? Как показано ниже, изменение параметра «limit» на 500 000 и поиск значения «t» приводит к тому, что в одном ответе возвращается 121 069 пользователей.
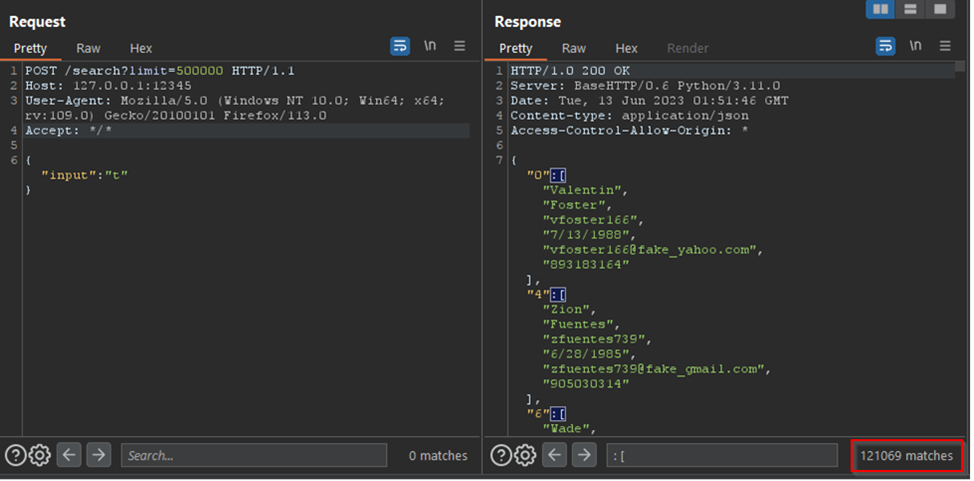
- Требуется ли аутентификация: Нет;
- Сколько данных возвращается: без максимального ограничения;
- Какие данные возвращаются: ID пользователя, имя, никнейм, день рождения, адрес электронной почты, номер телефона;
- Легко ли анализировать данные: да, это просто JSON;
Страницы профиля пользователя
Посещение страницы профиля пользователя возвращает информацию о пользователе, опубликованных им постах и комментариях к ним.
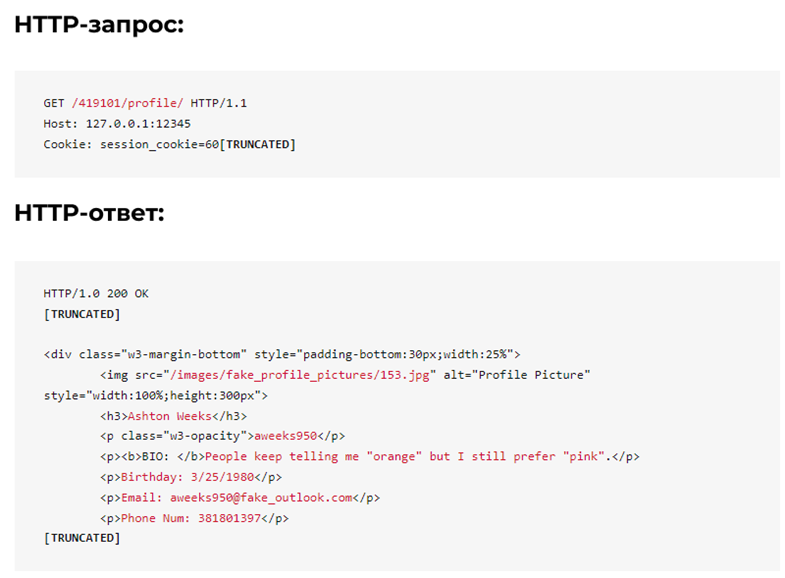
Поскольку ID пользователей генерируются последовательно, мы можем начать с ID 1 и увеличивать его до 500 000.
- Требуется ли аутентификация: Да;
- Сколько данных возвращается: 1 целевой пользователь и 3 комментатора на пост;
- Какие данные возвращаются: идентификатор пользователя, имя, никнейм, биография, дата рождения, электронная почта, номер телефона;
- Легко ли анализировать данные: да, в HTML.
Создание аккаунта
Для создания учетной записи требуется имя пользователя, адрес электронной почты, пароль и, при необходимости, номер телефона.
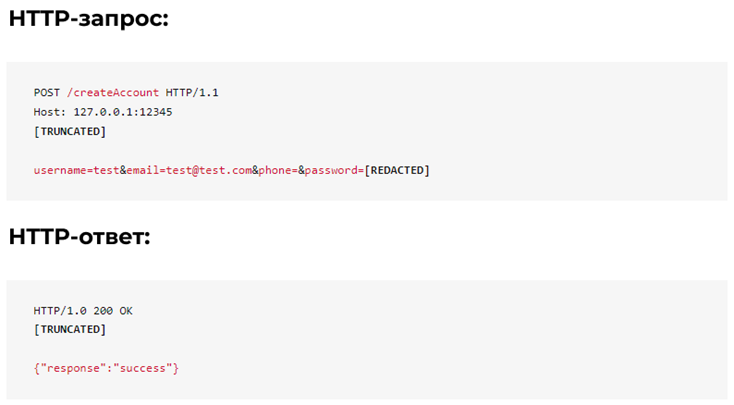
Сервер отвечает сообщением «success» при получении нового имени пользователя/электронной почты/телефона. Что произойдет, если имя пользователя/адрес электронной почты/номер телефона уже используются пользователем?
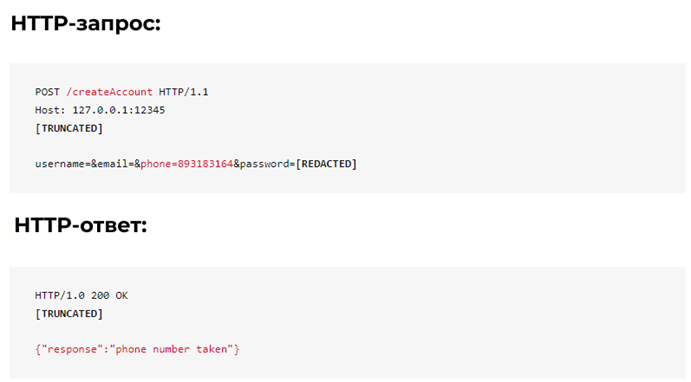
В этом случае учетная запись уже использует номер телефона «893183164», и сервер пропускает эту информацию. Несмотря на то, что конечная точка не возвращает пользовательские данные, данные по-прежнему утекли. Этот недостаток может быть использован парсером, например, для перебора всех возможных телефонных номеров и сбора списка всех номеров, используемых пользователями на платформе.
Таким образом, в процессе создания учетной записи нет защиты, поэтому мы можем создать большое количество поддельных учетных записей, которые затем можно использовать для будущих парсингов.
Функция «забыл пароль»
Функция восстановления забытого пароля требует имени пользователя и отправляет электронное письмо/смс для восстановления, если учетная запись существует.
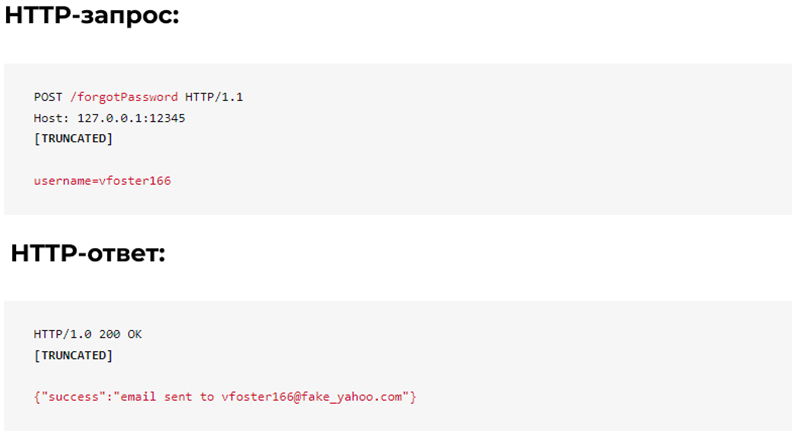
Обратите внимание, что, если указано действительное имя пользователя, сервер возвращает адрес электронной почты учетной записи. Такое действие может использоваться парсером для сбора email-адресов путем перебора имен пользователей или сбора имен пользователей из других мест приложения.
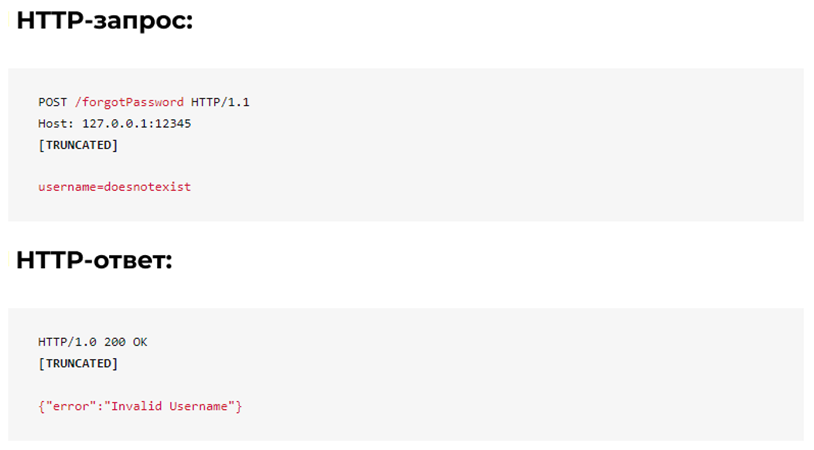
Если указано неверное имя пользователя, сервер возвращает сообщение об ошибке, как показано ниже:
Заключение
Давайте посмотрим, как поддельное приложение работает с 5 основными принципами защиты от парсинга.
- Требование аутентификации:
- Поиск доступен после выхода из системы;
- ·Установка ограничения количества запросов (Rate Limits):
- Ограничение запросов отсутствует во всем приложении;
- Блокировка создания учетной записи:
- Блокировки нет;
- Установка ограничения на данные:
- Поиск принимает параметр «limit» без принудительного максимального значения;
- Возврат сообщений об ошибках:
- Функции создания аккаунта и восстановления пароля обеспечивают утечку информации через сообщения об ошибках.
При отсутствии защиты парсинг всех 500 000 поддельных пользователей приложения можно легко выполнить за считанные минуты с помощью нескольких запросов. Во второй части мы будем внедрять в приложение средства защиты от парсинга и рассмотрим, как парсеры могут адаптироваться к изменениям.