
Строим защиту от парсинга. Часть 2: реализация эффективных методов безопасности данных
Статья является продолжением на тему анти-скрейпинговых техник и посвящена внедрению защиты от парсинга на примере тестового сайта, а также тому, как парсеры могут адаптироваться к внедряемым защитным мерам.

Хотя полное предотвращение веб-скрейпинга (парсинга), скорее всего, невозможно, реализация стратегии углубленной защиты может значительно увеличить время и усилия хакеров, необходимые для успешной атаки. В связи этим злоумышленники могут просто отказаться от данной затеи, выбрав себе цель попроще.
Что было предпринято для усиления защиты?
В код используемого для примера тестового сайта с публикациями пользователей, показанного в прошлой статье, было внесены несколько изменений, чтобы попытаться предотвратить веб-скрейпинг.
Не все рекомендуемые изменения, которые мы обсуждали в прошлой статье, были применены к рассматриваемому сайту. Однако это было сделано намеренно, к чему мы ещё вернёмся позже.
Самым серьёзным и важным изменением стало то, что ко всему сайту было применено ограничение на количество возвращаемых данных. Раньше параметр «limit» в поисковой строке не имел какого-то максимально возможного значения, что позволяло получить данные всех 500 тысяч пользователей сайта буквально за несколько последовательных запросов. Теперь же параметр «limit» имеет максимальное принудительное значение «100». Кроме того, все служебные сообщения от системы были приведены к общему виду, который не допускает утечки информации.
Тем не менее, возможность простого и массового создания фиктивных учётных записей до сих пор не заблокирована. А поисковый движок по-прежнему не требует авторизации для работы. Как будет наглядно показано далее по статье, эти упущения существенно подрывают те исправления, которые были внесены для защиты данных.
Внедрение ограничений скорости
Существует множество вопросов, на которые нужно ответить при реализации ограничений скорости. Вот некоторые из них:
- Должны ли эти ограничения быть специфическими для конечных точек или постоянными для всего сайта?
- Сколько запросов минимально необходимо и максимально допустимо выполнять на единицу времени?
- Какими мерами будет «наказываться» превышение лимита запросов?
Кроме того, существует различие между ограничениями скорости для авторизованных и неавторизованных пользователей. Когда злоумышленники создают поддельные учётные записи и используют их для парсинга данных, ограничения скорости для авторизованных пользователей могут помочь приостановить или заблокировать учётные записи с нежелательным поведением, что может наложить существенные ограничения на работу парсера.
Ограничения скорости для неавторизованных пользователей применяются к самим конечным точкам по ряду сигналов, которые можно использовать для идентификации хакера.
Наиболее распространённым сигналом является IP-адрес, однако существуют также и прочие сигналы, такие как пользовательский агент, cookie-файлы и т.п. Далее мы рассмотрим, как на нашем поддельном тестовом сайте реализованы ограничения скорости входа и выхода из системы.
Ограничения скорости входа в систему
Рассмотрим случай, когда ограничения скорости для авторизованных пользователей применяются ко всему сайту.
Каждому авторизованному пользователю разрешено отправлять 1000 запросов в минуту, 5000 запросов в час и 10000 запросов в день. Если пользователь нарушает любое из этих ограничений скорости, он получает предупреждение. Если пользователь получает 3 таких предупреждения, — он блокируется на платформе.
Реализация такой неумолимой стратегии, вероятно, слишком строга для большинства приложений и сайтов, однако достаточно эффективна и проста в реализации.
Тем не менее, определение оптимального количества запросов, разрешённых на единицу времени, является непростой задачей. Ведь последнее, чего мы хотим при реализации анти-скрейпинговых мер, — это повлиять на рядовых пользователей продукта, не представляющих никакой угрозы.
Анализ журналов трафика поможет увидеть, сколько запросов отправляет среднестатистический пользователь. Это и будет иметь решающее значение при определении оптимального параметра.
При просмотре пользователей, отправляющих наибольшее количество трафика, может быть трудно отличить подлинный трафик от неправомерного использования платформы с помощью автоматизации. Для этого, скорее всего, потребуются ручные исследования и всестороннее тестирование в предпроизводственных средах.
Также стоит отметить, что ошибки в коде продукта могут привести к повторной отправке запросов от имени пользователя без его ведома. Наказание этих пользователей за ваши же ошибки было бы огромной оплошностью.
Если пользователь отправляет большое количество запросов на одну и ту же конечную точку, а возвращаемые данные не меняются, то наиболее вероятно, что это ошибка на платформе, а не последствия работы парсера.
Ограничения скорости для неавторизованных пользователей
Ограничения скорости для неавторизованных пользователей мы также рассмотрим применимо ко всему сайту целиком.
Каждый IP-адрес может отправлять 1000 запросов в минуту, 5000 запросов в час и 10000 запросов в день. Если IP-адрес нарушает любое из этих ограничений скорости, он получает предупреждение. Если IP получает 3 таких предупреждения, — он блокируется на платформе.
Это весьма неидеальное решение. Основной её недостаток заключается в том, что некоторые IP-адреса могут использоваться сразу несколькими пользователями. Например, общедоступные Wi-Fi точки или университетские системы могут выдавать каждому пользователю одинаковый IP-адрес. И в случае, если сразу несколько таких пользователей захочет воспользоваться платформой с подобными ограничениями, система несправедливо накажет их за чрезмерное количество запросов.
Другим существенным недостатком такого подхода является то, что парсер может контролировать почти любой фиксируемый системой внешний сигнал. И ему ничего не будет стоить подделать свой IP-адрес или другие сигнальные данные.
Применение ограничений на количество возвращаемых данных
Настройка лимита объёма данных, которые могут быть возвращены за один ответ, является важным элементом в борьбе с парсингом. Раньше на рассматриваемом тестовом сайте в поисковой строке был параметр «limit», который мог выдавать данные сотен тысяч пользователей за один ответ. Теперь же за один ответ можно вернуть данные только 100 пользователей. А если запрашивается больше — возвращается сообщение об ошибке, как показано ниже.
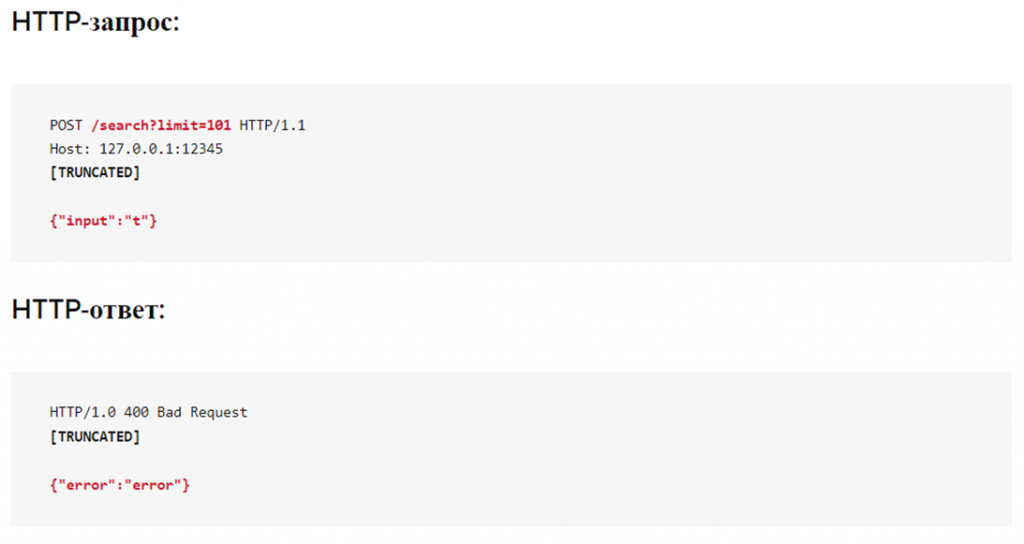
Общие сообщения об ошибках
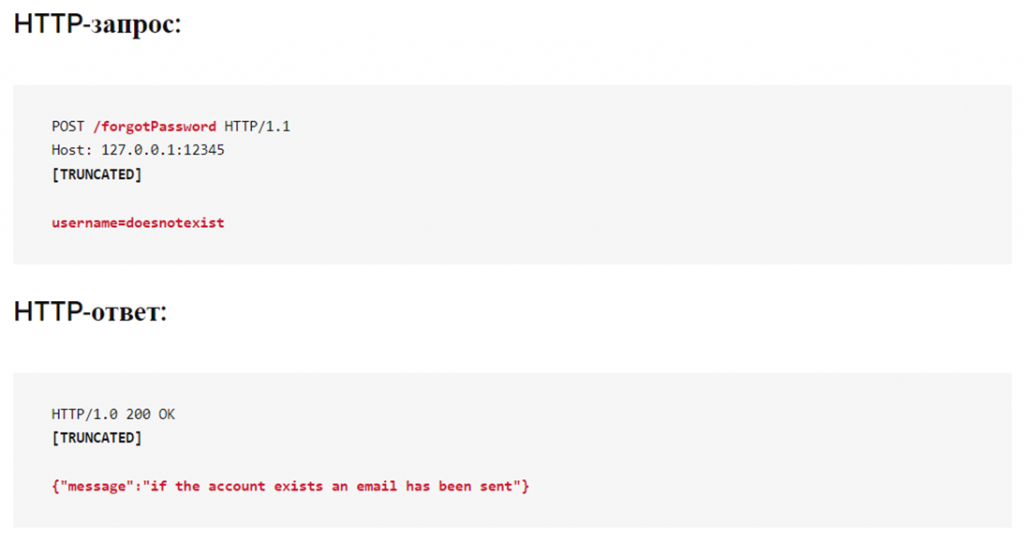
Ранее на тестовом сайте служебные сообщения о восстановлении забытого пароля или создания новой учётной записи — пропускали полезную для парсеров информацию.
Так, злоумышленники могли добраться до реального адреса электронной почты пользователей, инициировав процесс сброса пароля, указывая различные имена пользователей или мобильные номера методом перебора. Теперь же служебные сообщения о сбросе пароля, вне зависимости от наличия или отсутствия в системе конкретной учётной записи, всегда возвращают одно и то же сообщение: «Если учётная запись существует, электронное письмо туда было отправлено».
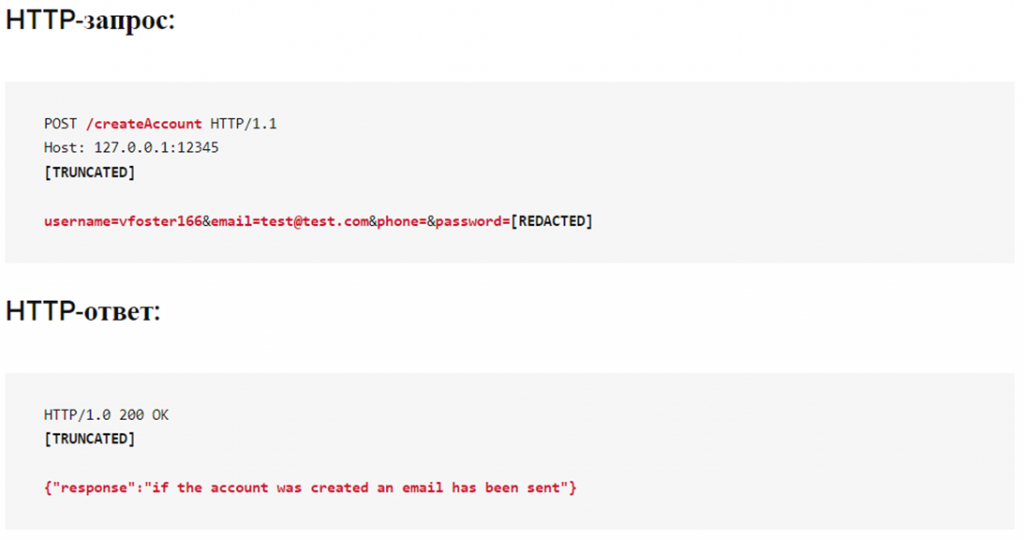
То же касается и процесса создания учётной записи злоумышленником с целью выявления, занято ли уже конкретное имя пользователя, адрес электронной почты или номер телефона. Теперь всегда возвращается служебное сообщение «Если учётная запись была создана, электронное письмо отправлено».
Чем же ответит парсер?
Поскольку сайт был обновлён, давайте рассмотрим каждую часть его функционала и выясним, как потенциальный атакующий может обойти защиту:
- Функционал рекомендованных постов: сюда требуется аутентификация, система ограничивает любую учётную запись после 1000 запросов.
- Панель поиска: сюда не требуется аутентификации, возвращает 100 пользователей за ответ и ограничивает доступ с конкретного IP-адреса после 1000 запросов.
- Страницы профиля пользователя: требуется аутентификация, присутствует ограничение скорости после 1000 запросов.
- Создание новой учётной записи: больше невозможно использовать для утечки данных, но всё ещё можно легко создавать поддельные учётные записи.
- Процесс сброса пароля: больше невозможно использовать для утечки данных.
В целом сайт претерпел множество улучшений по сравнению с изначальной версией. Введение ограничений вынуждает хакеров адаптировать свои методы, будут ли они достаточно эффективны, чтобы всё равно собрать пользовательские данные или можно открывать бутылку шампанского и отмечать победу над парсингом? Об этом далее.
Парсинг с входом в систему
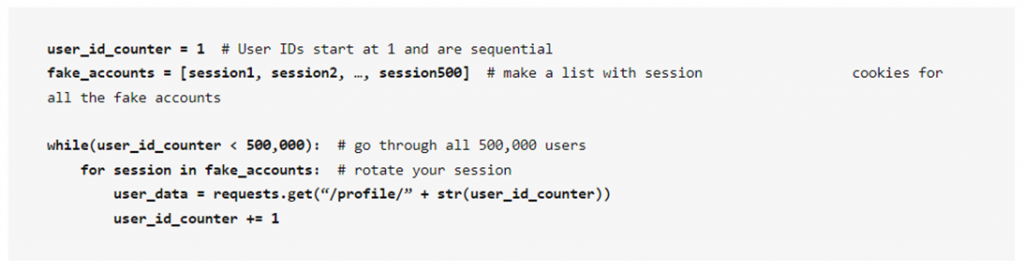
Итак, тактика парсинга с входом в систему будет заключаться в чередовании сеансов. Поскольку злоумышленник может легко создать множество поддельных учётных записей, он будет отправлять небольшое количество запросов с каждой такой учётной записи, переключаясь затем на другую, тем самым он сможет обойти установленное нами ограничение на количество запросов. По итогу, он не столкнётся с ограничением скорости и сможет вытянуть необходимые ему данные.
Цель хакера состоит в том, чтобы извлечь с сайта данные обо всех 500 000 пользователей, используя либо функционал рекомендованных публикаций, либо страницы профилей пользователей. Поскольку страницы профиля пользователя возвращают больше данных о последнем (идентификатор, имя, имя пользователя, адрес электронной почты, день рождения, номер телефона, сообщения и т.д.), это будет наиболее приемлемый для злоумышленника вариант атаки.
Даже предполагая то, что за один ответ можно получить данные лишь одного пользователя, каждая поддельная учётная запись может отправлять до 1000 запросов в минуту без ограничения скорости. Если злоумышленник создаст 500 поддельных учётных записей, то всего за минуту он будет иметь на руках базу пользователей со всеми их данными.
Код парсера:
Парсинг без входа в систему
Чтобы извлечь данные всех 500 000 пользователей вообще без входа в систему, злоумышленник может воспользоваться функцией поиска, которая всё ещё доступна неавторизованным пользователям. Однако это будет уже не так просто, как раньше, ведь теперь за один ответ возвращаются данные только 100 пользователей.
Тем не менее, поскольку с каждого IP-адреса может отправить до 1000 запросов в минуту без каких-либо ограничений, значит с каждого неавторизованного сеанса хакер сможет вытащить данные 100 тысяч пользователей без блокировки.
Это означает, что для парсинга таким способом потребуется буквально 5 IP-адресов и немного времени. Большинство инструментов ротации IP-адресов используют десятки тысяч IP-адресов, поэтому получение такого мизерного количества айпишников вообще не является проблемой для опытных парсеров.
Код парсера:

Промежуточный итог
Имея в своей системе несколько средств защиты, парсинг всех 500 000 пользователей за несколько минут по-прежнему довольно прост. Именно поэтому крайне важно соблюдать все основные принципы защиты от парсинга. Их всего пять и описать их можно следующим образом:
- обязательно требовать аутентификацию для любых действий с данными;
- применять ограничения скорости, как для учётных записей, так и для конечных точек;
- блокировать создание фейковых учётных записей внедрением дополнительных методов верификации;
- применять ограничения на вывод данных за один запрос;
- возвращать только общие служебные сообщения без подробностей.
Как показано в этой статье, невыполнение даже одного из этих принципов может полностью свести на нет пользу от всех остальных реализованных мер и существенно подорвать безопасность платформы.
Дополнительные средства защиты
Есть несколько дополнительных методов анти-скрейпинга, на которые стоит обратить внимание, прежде чем мы закончим.
В процессе внедрения мер против создания поддельных учётных записей внедрение CAPTCHA является очень важным шагом, который колоссально усложнит парсерам их деятельность.
Требование от пользователя обязательно предоставить номер телефона для регистрации также может сильно раздражать атакующих. А если установить ограничение по количеству учётных записей на один номер телефона и заблокировать любые виртуальные номера, создавать поддельные учётные записи в больших масштабах станет гораздо сложнее.
Если пользовательские данные возвращаются в формате HTML, добавление случайности к ответам является ещё одним важным сдерживающим фактором. Изменяя количество и тип HTML-тегов вокруг пользовательских данных, не влияя на сам пользовательский интерфейс, парсеру станет значительно сложнее автоматизировать анализ большого объёма данных.
Что касается ограничений скорости, обязательно применяйте их к учётной записи пользователя, а не к текущему сеансу. Ведь ограничения к сеансу можно обойти, банально перезайдя в систему.
Для ограничений скорости неавторизованных пользователей блокировка определённых диапазонов IP-адресов, таких как IP-адреса TOR или прокси-провайдеров / VPN-провайдеров, может иметь большой смысл, особенно если большая часть трафика является недостоверной.
Наконец, идентификаторы пользователей не должны генерироваться последовательно. Для работы многих парсеров сначала требуется список идентификаторов. Если их трудно угадать и нет простого способа собрать их в большой структурированный список, то это также может значительно замедлить атакующего или отказаться от атаки на ваш сайт в принципе.
Заключение
Надеемся, что некоторые тактики и приёмы защиты от парсинга, представленные в этой статье, были вам полезны. Хотя полностью предотвратить столь коварное явление как парсинг, вероятно, невозможно, внедрение мощной защиты и соблюдение вышеописанных принципов безопасности — будут иметь большое значение для сдерживания злоумышленников и растраты их времени.
С первой частью статьи «Основные принципы предотвращения парсинга» можно ознакомиться по ссылке.