
Сравнительный анализ производительности методов экранирования в языках веб-разработки
В данной статье будет проведен анализ и сравнение производительности методов экранирования, применяемых в различных языках программирования, используемых преимущественно в веб-разработке: PHP, Python, Parser3 и Node.js.

Введение
Безопасность остается актуальной проблемой при разработке веб-приложений. Одним из распространённых видов уязвимостей, с которыми сталкиваются веб-разработчики, является XSS (Cross-Site Scripting, межсайтовый скриптинг). XSS атаки позволяют злоумышленникам внедрять вредоносный код в веб-страницы, которые затем отображаются другим пользователям. Это может привести к краже личных данных, распространению фишинга и другим серьезным последствиям.
Важность экранирования управляющих символов HTML
В HTML некоторые символы, такие как '<' и '>', являются управляющими и служат для формирования тегов. Когда такие символы встречаются в пользовательских данных, их необходимо заменить, чтобы они отображались как обычные символы. Процедура преобразования управляющих символов HTML на их текстовое представление называется экранированием. Оно делает невозможным запуск вредоносных скриптов и таким образом защищает от XSS-атак. Например если злоумышленник в сообщении на форуме передаст код ‹script src="https://evil.site/virus.js"/›, то экранирование заменит управляющие символы в визуальные эквиваленты:

Методы экранирования в различных языках программирования
В языке PHP для преобразования специальных символов в HTML-сущности применяется функция htmlspecialchars, которую разработчик должен вызвать при выводе пользовательских данных в HTML. В режиме ENT_COMPAT, эта функция обрабатывает следующие символы:
Знак меньше < становится < , а знак больше > превращается в > блокируя формирование нежелательных тегов.
Амперсанд & преобразуется в &, что предотвращает ошибочное интерпретирование последующих символов как части HTML-сущности.
Двойная кавычка " конвертируется в ", что важно если пользовательские данные выводятся внутри атрибутов тегов, заключенных в двойные кавычки.
В языке Python аналогичную функциональность предоставляет метод html.escape. Помимо указанных выше замен производится замена одиночной кавычки ‘ на '.
В языке Parser реализовано автоматическое экранирование небезопасных символов в зависимости от контекста использования. В третьей версии языка для этого используется разделение данных на безопасные или “чистые” и небезопасные. Безопасные данные – это то, что написал сам разработчик в коде веб-приложения. Остальные данные, которые поступают из внешних источников - передаются посетителем в полях формы или загружаются из файла или другого сайта, считаются небезопасными. При выводе таких данных в HTML страницу управляющие символы будут автоматически экранированы.
В Node.js встроенный метод экранирования отсутствует, поэтому реализуем его самостоятельно двумя разными способами: последовательно заменяя каждый специальный символ на соответствующую HTML-сущность (replace) и используя регулярное выражение, которое ищет и заменяет все специальные символы (regex).

Кроме того, переведем предложенный выше код на другие языки программирования, рассматриваемые в нашем обзоре. Это позволит сравнить, насколько такой подход к экранированию эффективен по сравнению с встроенными методами этих языков. Код на других языках приведен в приложении 1.
Методология тестирования
Для проведения замеров производительности использовалась HTML версия первого тома "Война и Мир". Исходный размер файла составлял 1,415,134 байта, в том числе 28,091 символов, требующих экранирования, что составляет около 2% от общего объема. Это символы включают в себя знаки меньше <, больше >, амперсанды &, а также двойные кавычки. Для унификации результатов между разными языками одиночные кавычки в тексте были заменены на двойные. Кроме того, были подготовлены версии файла с удалёнными экранируемыми символами, с уменьшенной наполовину и удвоенной долей таких символов, чтобы оценить влияние различного процента экранируемых данных на производительность методов экранирования.
Для уменьшения влияния загрузки данных и колебаний производительности, каждый метод экранирования применялся 100 раз. Результатом обработки была строка, содержащая 100 повторений обработанного текста, что соответствовало объему примерно в 142 мегабайта. После замера времени выполнения, результат сохранялся в файл для последующей проверки корректности обработки данных.
Основной цикл формирования результата имитировал вывод записей гостевой книги из базы данных. Его реализация на языке PHP:

На Python:

На Parser3:

На Node.js:

Условия тестирования и результаты экспериментов
Для проведения экспериментов использовалась следующая тестовая среда:
Аппаратное обеспечение состояло из процессора Intel(R) Core(TM) i5-8600 с 6 ядрами, оснащенного 32 ГБ оперативной памяти и NVME накопителем. Эти характеристики обеспечивают достаточную мощность для обработки больших объёмов данных и выполнения программ без значительных задержек.
В качестве операционной системы использовался Debian версии 12.5. Для тестирования применялись поставляемые в этом дистрибутиве версии языков программирования: PHP 8.2.18, Python 3.11, Parser 3.4.6. Node.js использовался v20.12.0. Эти версии актуальны и широкого используются в современной веб-разработке.
Такая тестовая среда позволяет оценить производительность и эффективность различных методов экранирования в условиях, максимально приближенных к реальным.
Ниже представлены результаты замеров времени экранирования в секундах для разных реализаций экранирования в зависимости от языка и процента экранируемых данных.
PHP
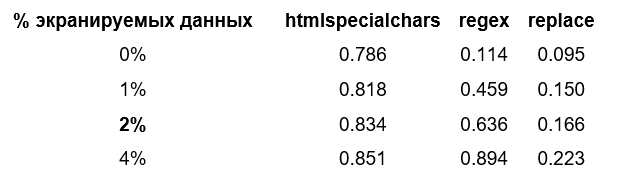
Python
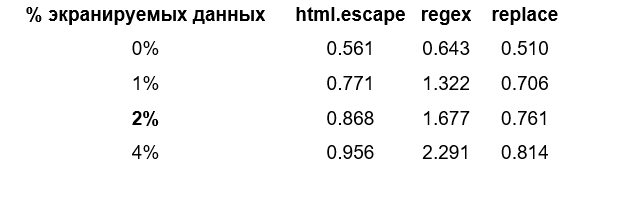
Parser
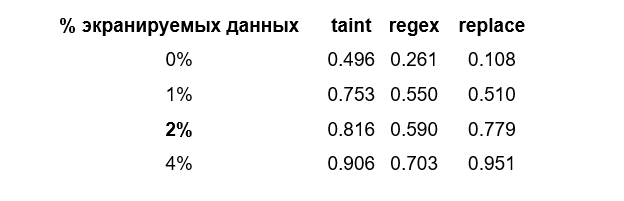
Node.js
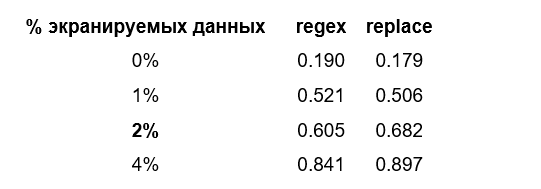
-
% Экранируемых данных: Указывает на долю символов в тексте, требующих экранирования.
-
html.escape, htmlspecialchars, taint: стандартные инструменты для экранирования HTML в PHP, Python и Parser3 соответственно.
-
regex, replace: альтернативные реализации методов экранирования.
Визуализация этих данных в виде графиков:
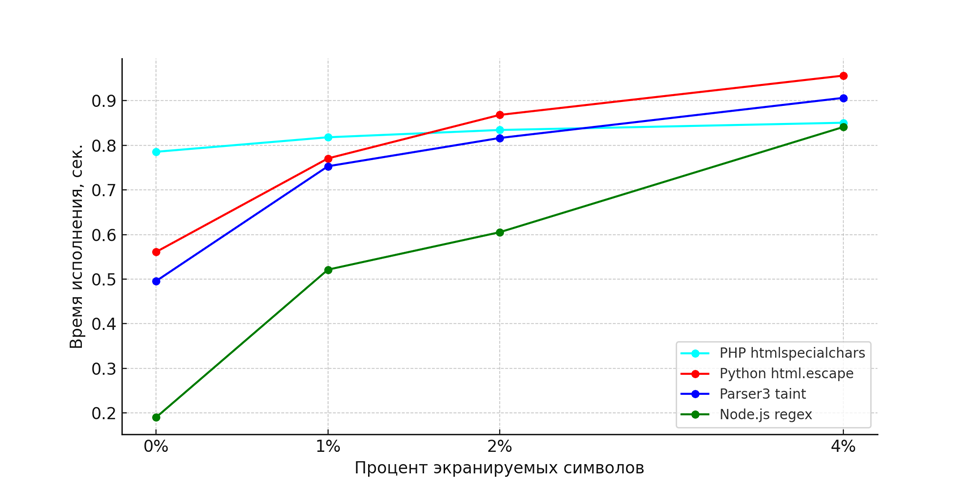
Рис 1. Сравнение производительности стандартных инструментов экранирования.
Для Node.js использована показавшая большую эффективность реализация с регулярным выражением.
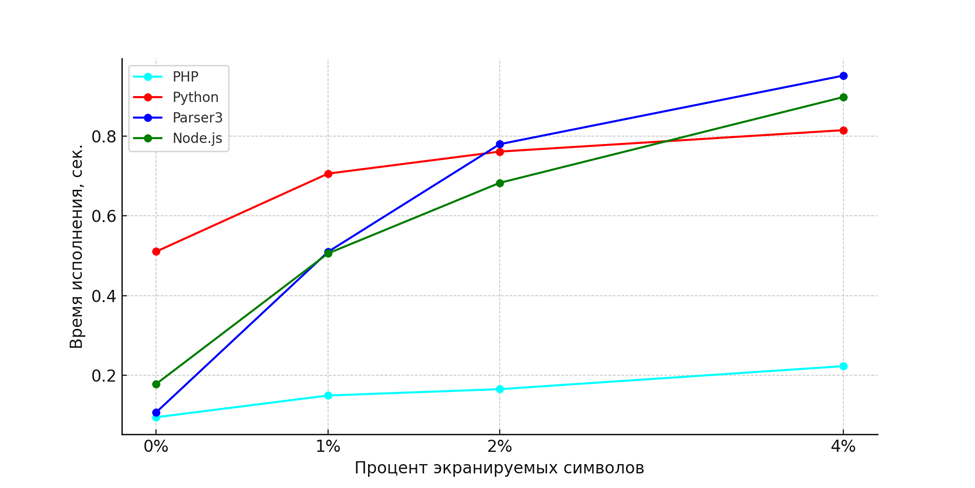
Рис 2. Сравнение производительности реализаций экранирования в виде последовательной замены.
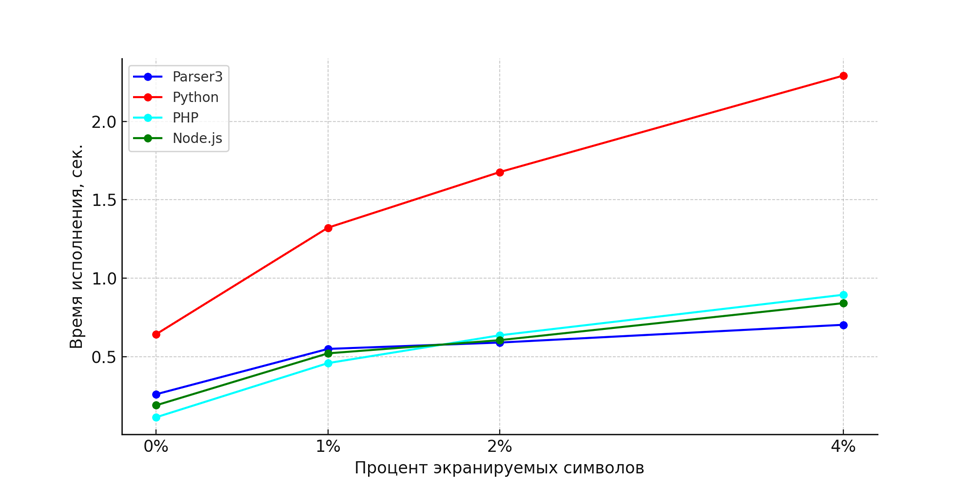
Рис 3. Сравнение производительности реализаций экранирования в виде регулярного выражения.
Выводы
Главный вывод, который можно сделать из этих данных - производительность экранирования во всех рассматриваемых языках более чем достаточна для большинства практических применений и едва ли будет узким местом в приложении.
Если перейти к цифрам, то все сравниваемые языки позволяют в секунду экранировать порядка 200 мегабайт данных, содержащих около 5 миллионов небезопасных символов. Это даже в один поток больше, чем можно передать по гигабитному каналу подключения к сети интернет.
Видно, что с увеличением доли экранируемых данных время обработки увеличивается, что логично, учитывая дополнительную обработку, необходимую для преобразования дополнительных символов. Однако этот рост не более чем линейный и не приведет к критическому увеличению времени выполнения даже при значительном увеличении количества экранируемых символов.
Сравнение производительности по языкам и методам:
PHP: метод htmlspecialchars выделялся среди других, демонстрируя наиболее стабильную производительность (см. рис. 1). При низком проценте экранируемых данных метод был в аутсайдерах, но с ростом числа небезопасных символов он показал лучшую производительность. Реализация последовательной замены на этом языке тоже оказалась самой эффективной (см. рис. 2).
Python: производительность метода html.escape на уровне остальных языков (см. рис. 1), а вот реализация экранирования регулярным выражением оказалась явным аутсайдером (см. рис. 3). Причем дополнительное исследование показало, что дело именно в библиотеке регулярных выражений, а не накладных расходах на вызов лямбда-функции.
Parser3: Производительность автоматического экранирования в Parser находится на уровне производительности встроенных методов экранирования в языках PHP и Python (см. рис. 1). Для автоматического экранирования необходимо хранить информацию об источнике данных для каждого символа и это действительно дает небольшие накладные расходы, заметные на малом числе экранируемых символов. Но если в других языках методы экранирования разработчик должен вызывать самостоятельно, то Parser берёт на себя значительную часть работы по обеспечению безопасности приложения, что делает код проще и менее подверженным ошибкам.
Node.js: Использование регулярных выражений и последовательных замен показало схожую производительность, с некоторым превосходством метода замены при низком проценте экранируемых данных. В обоих случаях наблюдается значительное падение производительности с ростом процента экранируемых данных.
Рекомендации
При работе с большими объемами данных важно учитывать процент данных, требующих экранирования. Если этот процент мал, можно рассмотреть более производительные методов экранирования, чем встроенные методы. Однако, как показывают результаты экспериментов, необходимость в специальных оптимизациях для большинства практических применений сомнительна. В ситуациях, где производительность является критичной, рекомендуется провести дополнительное тестирование с реальными наборами данных, чтобы точно определить, какой метод будет оптимальным.
Подводя итоги исследования, становится очевидным, что разработчики могут обеспечивать безопасность веб-приложений без значительной потери производительности. Рассмотренные языки программирования предлагают эффективные инструменты для экранирования, которые позволяют быстро обрабатывать большие объемы данных. Это обеспечивает защиту от XSS-атак и других угроз, связанных с неправильной обработкой входных данных.
Приложение 1
Реализации экранирования последовательной заменой каждого специального символа на соответствующую HTML-сущность (replace) и с использованием регулярного выражения, которое ищет и заменяет все специальные символы (regex).
Для языка PHP:

Для языка Python:

И для языка Parser3. В этом языке есть специальный метод для табличной замены, используем его.

Автор Константин Моршнев