

12 июля в прессе появились пока не подтвержденные официально сообщения о том, что Facebook с Федеральной Торговой Комиссией США по поводу утечки пользовательской информации. Основной темой расследования FTC стали компании Cambridge Analytica, еще в 2015 году получившей данные десятков миллионов пользователей Facebook. Facebook обвиняется в недостаточной защите приватности пользователей, и если сообщения подтвердятся, соцсеть заплатит американской госкомиссии крупнейший в истории штраф в размере 5 миллиардов долларов.
Скандал с Facebook и Cambridge Analytica — первый, но далеко не последний пример обсуждения технических проблем совершенно нетехническими методами. В этом дайджесте мы рассмотрим несколько свежих примеров таких дискуссий. Конкретнее — как вопросы приватности пользователей обсуждаются без оглядки на конкретные особенности работы сетевых сервисов.
Пример первый: Google reCaptcha v3
Новая версия инструмента для борьбы с ботами Google была представлена . Первая версия «капчи» от Google отличала роботов от людей по распознаванию текста. Вторая версия сменила текст на картинки, и то — показывала их только тем, кого считала подозрительными.

Третья версия не спрашивает ничего, полагаясь преимущественно на анализ поведения пользователей на веб-сайте. Каждому посетителю присваивается определенный рейтинг, на основе которого владелец сайта может, например, принудительно запросить авторизацию через мобильный телефон, если посчитает логин подозрительным. Вроде бы все хорошо, но не совсем. 27 июня издание Fast Company публикует большую , где, ссылаясь на двух исследователей, обозначает проблемные места reCaptcha v3 с точки зрения приватности.
Во-первых, при анализе последней версии «капчи» было обнаружено, что пользователи, залогиненные в учетную запись Google, по определению получают более высокую оценку. Аналогично, если вы открываете веб-сайт через VPN или сеть Tor, вас с более высокой вероятностью отметят как подозрительного посетителя. Наконец, Google рекомендует устанавливать reCaptcha на все страницы веб-сайта (а не только те, где необходимо верифицировать пользователя). Это дает больше информации о поведении пользователя. Но эта же особенность теоретически предоставляет Google большой объем информации о поведении пользователей на сотнях тысяч сайтов (по данным Fast Company, reCaptcha v3 установлена на 650 тысячах сайтов, несколько миллионов используют предыдущие версии).
Это типичный пример неоднозначного обсуждения технологий: с одной стороны, чем больше данных будет у полезного инструмента для борьбы с ботами, тем лучше и владельцам сайтов, и пользователям. С другой — провайдер сервиса получает доступ к огромной выборке данных, а заодно контролирует, кого допускать к цифровым данным сразу, а кому усложнять жизнь. Очевидно, что поборникам максимальной приватности, старающимся не держать в своем браузере лишние куки, постоянно использующим VPN, такой прогресс совсем не нравится. С точки зрения Google никакой проблемы нет: в компании утверждают, что данные «капчи» не используются для рекламного таргетинга, а усложнение жизни ботоводам — достаточный повод для подобных нововведений.
Пример второй: доступ к данным в приложениях для Android
В конце июня та самая Федеральная Торговая Комиссия США провела конференцию PrivacyCon. Доклад исследователя Сержа Эгельмана был посвящен тому, как разработчики приложений для Android обходят ограничения системы и получают данные, которые по идее не должны получать. В были проанализированы 88 тысяч приложений из американского Google Play Store, из них 1325 были способны обходить ограничения системы.
Как они это делают? Например, приложение для обработки фотографий Shutterfly получает доступ к данным геолокации, даже если пользователь запретит ему это делать. Все просто: апп обрабатывает геотеги, сохраненные в фотографиях, к которым доступ открыт. Представитель разработчика резонно , что обработка геотегов является штатной функциональностью программы, применяемой для сортировки фото. Ряд приложений обходили запрет на доступ к геолокации, сканируя MAC-адреса ближайших точек Wi-Fi и таким образом определяя примерное местоположение пользователя.
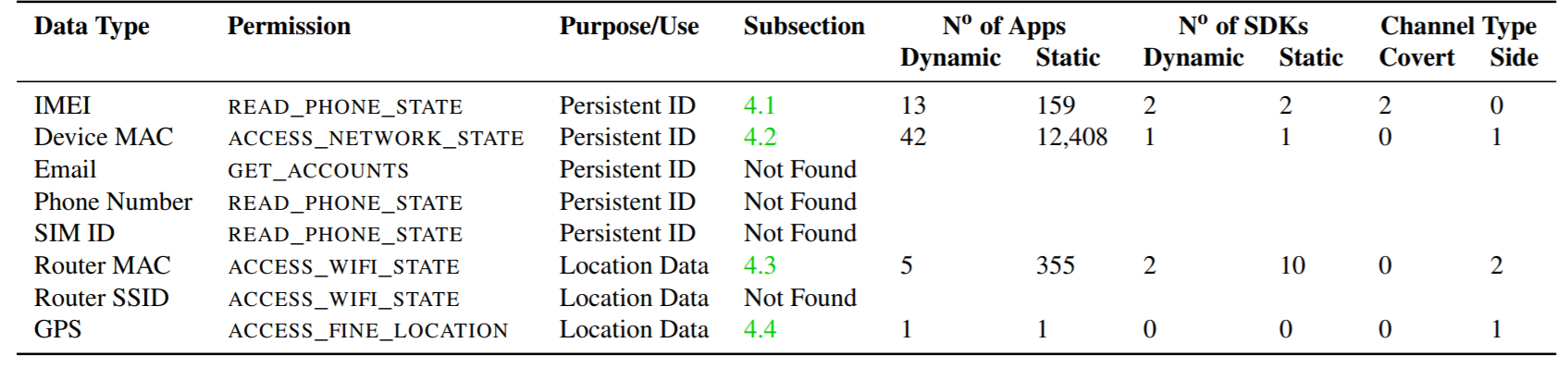
Чуть более «криминальный» метод обхода ограничений был обнаружен в 13 приложениях: один апп может иметь доступ к идентификатору IMEI смартфона. Он сохраняет его на карту памяти, откуда его могут прочитать другие программы, доступа не имеющие. Так, например, делает одна рекламная сеть из Китая, SDK которой встраивается в код других приложений. Доступ к IMEI позволяет однозначно идентифицировать пользователя для последующего рекламного таргетирования. Кстати, с универсальным доступом к данным на карте памяти связано еще одно исследование: была выявлена (теоретическая) возможность при общении в мессенджерах Telegram и Whatsapp. В результате правила доступа к данным в новой версии Android Q будут .
Пример третий: идентификаторы Facebook в картинках
Несколько лет назад такой твит мог инициировать в лучшем случае техническую дискуссию на пару десятков сообщений, но теперь о нем пишут . Как минимум с 2014 года Facebook собственные идентификаторы в метаданные картинок, которые загружаются в сам Facebook или в соцсеть Instagram. Подробнее идентификаторы Facebook разбираются , но как именно соцсеть их использует — никто не знает.
Учитывая негативный новостной фон, можно интерпретировать такое поведение как «еще один способ слежки за пользователями, да что же это такое, как они могли». Но на самом деле идентификаторы в метаданных могут использоваться, например, для ковровых банов нелегального контента, причем заблокировать можно не только репосты внутри сети, но и сценарии «скачал картинку и залил заново». Такая функциональность может быть и полезной.
Проблема общественного обсуждения вопросов приватности в том, что реальные технические особенности работы какого-либо сервиса часто игнорируются. Самый показательный пример: обсуждение государственных бэкдоров в системах шифрования мессенджеров или данных на компьютере или смартфоне. Заинтересованные в беспроблемном доступе к зашифрованным данным говорят о борьбе с криминалом. Специалисты по шифрованию аргументированно доказывают, что шифрование так не работает, и намеренное ослабление криптографических алгоритмов . Но тут хотя бы речь идет о научной дисциплине, которой несколько десятков лет.
Что такое приватность, какой именно контроль над нашими данными необходим, как контролировать соблюдение таких норм — какого-то общего, понятного всем ответа на эти вопросы пока не существует. Во всех примерах в этом посте наши данные собираются для какой-то полезной функциональности, правда, не всегда эта польза — для конечного потребителя (чаще — для рекламодателя). Но когда вы в навигаторе смотрите пробки по пути домой — это тоже результат сбора данных о вас и о сотнях тысяч других людей.
Не хочется завершать пост дурацким выводом «не все так однозначно», поэтому попробуем так: чем дальше, тем чаще разработчикам программ, устройств и сервисов придется решать не только технические вопросы («как сделать так, чтобы оно работало»), но и общественно-политические («как не платить штрафы, не читать про себя гневные статьи в СМИ и не проигрывать конкуренцию другим компаниям, где приватности больше хотя бы на словах»). Как изменится индустрия в этой новой реальности? Появится ли у нас больше контроля над данными? Не замедлится ли разработка новых технологий из-за «давления общественности», на которое нужно тратить время и ресурсы? Вот за этой эволюцией мы и будем наблюдать.
Disclaimer: Мнения, изложенные в этом дайджесте, могут не всегда совпадать с официальной позицией «Лаборатории Касперского». Дорогая редакция вообще рекомендует относиться к любым мнениям со здоровым скептицизмом.

