

Кадр из фильма «Великий Гэтсби» @Warner Brothers, Village Roadshow Pictures, Bazmark Films, A&E Spectrum Films и Red Wagon Entertainment (юристы попросили написать)
Захожу я в английский клуб. Там все сидят, выпивают, в карты играют. Смотрю — в очко режутся! Сел я за столик, взял карты. У меня — 18. А мой соперник говорит: «20». Я ему: «Покажи!». А он мне: «Мы, джентльмены, верим друг другу на слово». И вот тут-то мне поперло.
Но в ИБ так не пройдет, нужна здоровая паранойя. Поэтому на слово не верим никому, в том числе и инструментам анализа, а сначала их проверяем.
Всем хорошего дня! Меня зовут Антон Володченко. Я руководитель продукта PT Application Inspector в компании Positive Technologies. В статье хотел бы поделиться результатами внутреннего тестирования инструментов анализа состава ПО (Software Composition Analysis, SCA) и рассказать об одной важной проблеме доступных сегодня анализаторов.
Про open source

Думаю, ни для кого не будет открытием (такой вот каламбур :)), что open source software (OSS) очень плотно вошло в нашу жизнь. Под нашей жизнью я подразумеваю разработку, IT, да и многие смежные отрасли. Все, кто так или иначе соприкасался с IT, знают, что это такое, поэтому вдаваться в подробности не будем. Отмечу лишь, что с годами развитие и использование OSS только набирает обороты. Обратимся к статистике за последний год github.com, как наиболее популярной платформы для open source: 420 миллионов проектов (рост 27%), из них 284 миллиона публичных (рост 22%). А в последнем отчете Synopsys OSSRA 2024 говорится о том, что 96% рассмотренных проектов содержат компоненты с открытым исходным кодом, а 77% всего кода проектов это код ПО из открытых источников.
Иначе говоря, почти в каждом проекте есть компоненты с открытым кодом.
В то же время множатся и угрозы, связанные с использованием таких компонентов и библиотек. Сами угрозы можно разделить на две большие части: лицензионные риски и риски безопасности.
Первые могут привести к юридическим последствиям из-за неправомерного использования OSS. Например, библиотека под лицензией GPL будет требовать от производных продуктов раскрывать исходный код. Для коммерческих разработчиков это условие часто неприемлемо. Другие проблемы с лицензиями могут быть связаны с необходимостью платить правообладателю за использование открытого кода в коммерческих целях, о чем разработчики могут забыть, решив, что «это ж опенсурс, бери да пользуйся». Есть статьи с кратким описанием ограничений разных видов лицензий для распространения ПО и пояснением, в каких случаях их можно использовать. Например, вот такая.
Второй вариант угроз — проблемы безопасности. Они уже не такие очевидные, не всегда заметные и непростые в устранении. Здесь гораздо больше вариаций на тему «как испортить жизнь разработчику/тимлиду/компании/акционерам/пользователям». Последствия предугадать заранее тоже тяжелее, а их спектр значительно шире. Про проблемы безопасности дальше и поговорим, хотя про лицензии тоже забывать не будем.
Уязвимости open source

Статистика явно говорит, что вслед за ростом использования компонентов с открытым кодом в абсолютных числах растет и число проблем с их безопасностью. Ниже на картинке показано количество опасных пакетов, обнаруженных в 2023 году (согласно аналитике Sonatype), которое превосходит все прошлые года вместе взятые.
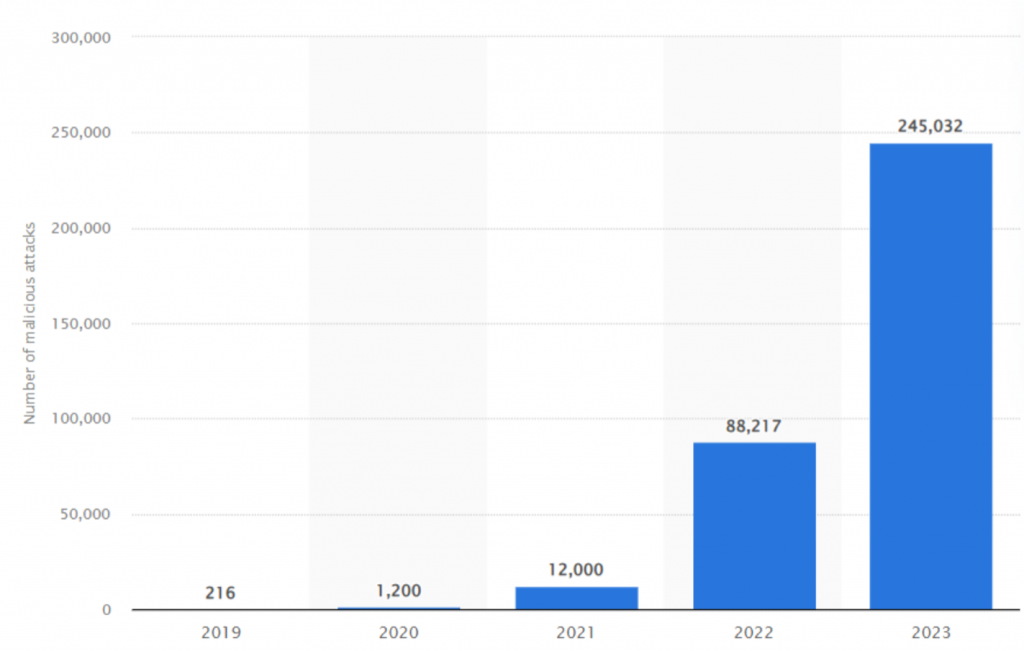
Комментарии тут излишни, так что перейдем сразу к важному: а что с этим делать?
Наводим порядок
Первый шаг — инвентаризация. Нужно понять, что используется в проектах, какие есть библиотеки, каких версий и под какими лицензиями. Тут могут пригодиться генераторы SBOM, предоставляющего список используемого в проекте ПО.
Их выбор, с одной стороны, широкий, с другой — сводится к двум популярным стандартам SPDX и CycloneDX. Первый чуть более громоздкий, второй лучше подходит для работы с уязвимостями, но оба имеют право на жизнь. Инструментов, которые умеют их генерить, много. Для SPDX можно взять генератор, для CycloneDX — пример тут. К слову, у CycloneDX есть еще сканер лицензий. Он довольно полезен для проверки лицензионной чистоты, о которой говорили ранее. Наборы инструментов, чтобы были под рукой, для SPDX и CycloneDX. Есть еще довольно интересный проект Syft, умеющий работать с обоими форматами и выдающий более интересные результаты, чем генераторы по ссылкам выше.
Сразу отмечу, что для себя мы выбрали Syft. Если говорить про сравнение, то таблица с указанием количества найденных зависимостей разными инструментами на наборе репозиториев Go ниже.
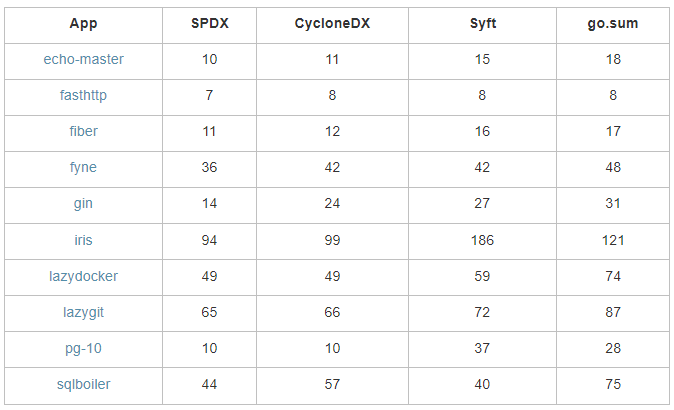
Результаты собирались полуавтоматически с небольшой обработкой скриптами, так что могут быть ошибки, но общая картина понятна: Syft дает результаты ближе к go.sum, хотя и не идентичные. Но его универсальность для нас важнее, так что пока работаем с ним. В будущем планируем работать и с самими пакетными менеджерами, чтобы сводить все воедино. Но начало положено, мы получили список используемого стороннего ПО, так что переходим ко второму шагу.
Проверяем безопасность компонентов

Поговорим про автоматизацию процессов безопасного сборочного конвейера ПО. Зачастую построение безопасной разработки начинают с внедрения SCA-инструментов — анализаторов для проверки сторонних компонентов. Оно и понятно, ведь внедрение SCA обычно не вызывает сложностей, результаты работы анализатора просты для понимания и интерпретации, а устранение проблем заключается в обновление до версии без известных уязвимостей. Но это все на первый взгляд, а дьявол кроется в деталях. Есть много нюансов, которые усложняют жизнь пользователям SCA-инструментов и оставляют дыры в безопасности приложений.
Давайте разбираться. Структура типового анализатора сторонних компонентов состоит из двух основных частей:
-
База знаний (feeds)
-
Обработчик SBOM
и нескольких опциональных:
-
Генератор SBOM
-
Управление уязвимостями
-
Интеграции с CI/CD и системами bug tracking.
Опциональные компоненты могут отсутствовать вовсе, подключаться через интерфейсы или входить в поставку инструмента SCA изначально. Не будем затрагивать смежные истории про интеграции и управление уязвимостями (VM). Пока говорим про базу :)
База знаний (feeds)
Это экспертиза, заложенная в анализатор. База знаний содержит в себе информацию об уязвимостях. Чем она шире и точней, тем потенциально лучше будут результаты анализа. Наполняется она из разных источников, вплоть до ручных правил на стороне конечного пользователя. Небольшой список наиболее популярных баз фидов:
-
OSV,
SBOM
Далее SCA-анализатор сопоставляет базу знаний и SBOM — их пересечения и будут результатами анализа, то есть списком пакетов, в которых есть уязвимости. Точность результатов зависит от обеих частей: если некорректно найден компонент, результаты будут нерелевантны, а если в базе знаний нет информации об уязвимости для нужной библиотеки, то и показывать нечего.
Некоторые из SCA-анализаторов работают по готовым SBOM, другие сами их собирают, а какие-то работают с файловой системой для поиска фактически присутствующих файлов пакетов.
У каждого подхода есть свои плюсы и минусы. Так, работа со SBOM на основе манифестов не требует сборки проекта и наличия самих библиотек в доступе, данные берутся из файлов пакетных менеджеров и списков зависимостей. Но в то же время нет гарантий точности совпадения, потому что сюда добавляются факторы окружения, отсутствия указания конкретных версий вообще или задание диапазона в файлах пакетных менеджеров. Например, для pip в requirements.txt встречается PyYAML>=5.4.1, но какая версия скачается в конкретный момент времени, неизвестно. Это будет зависеть от свежей версии в репозитории и от самого репозитория, который используется при сборке. У проверки по файлам самих пакетов этой проблемы нет, потому что работа идет с конкретным компонентом, можно определить его версию по атрибутам, хешам и прочему. Но тут возникает необходимость наличия самого файла, что далеко не всегда удобно делать при проверке кода приложения.
Примеры и проблемы SCA
Взяли SCA-инструмент, внедрили его в CI, получаем отчеты, разработчики по ним вносят изменения в продукт. Все молодцы!

Но, как говорится, есть нюанс.
Выше упомянул минусы подходов построения SBOM, но есть и еще проблемы. Зачастую анализаторы не проверяют, есть ли в пользовательском коде вызов опасной библиотеки, то есть существует ли возможность эксплуатации уязвимости. И тут получаем вероятные false positives в результатах. На практике мы имеем бооООоольшое количество ложных срабатываний, которые нужно обработать и проверифицировать, затем потратить много времени на обновление библиотек, хотя нет уверенности, что это надо было делать в принципе.
Просканируем вот этот небольшой пример и посмотрим, как ведут себя популярные SCA-инструменты.
Что в репозитории
Для начала разберемся, что это за репозиторий такой, чем интересен и что будем проверять.
Все довольно просто и тривиально. У нас есть пример кода на Java с уязвимостью Log4Shell в ветках vulnerable и main. Это true positive пример с вызовом опасного метода log4j, то есть реальная уязвимость в библиотеке. И сам код:
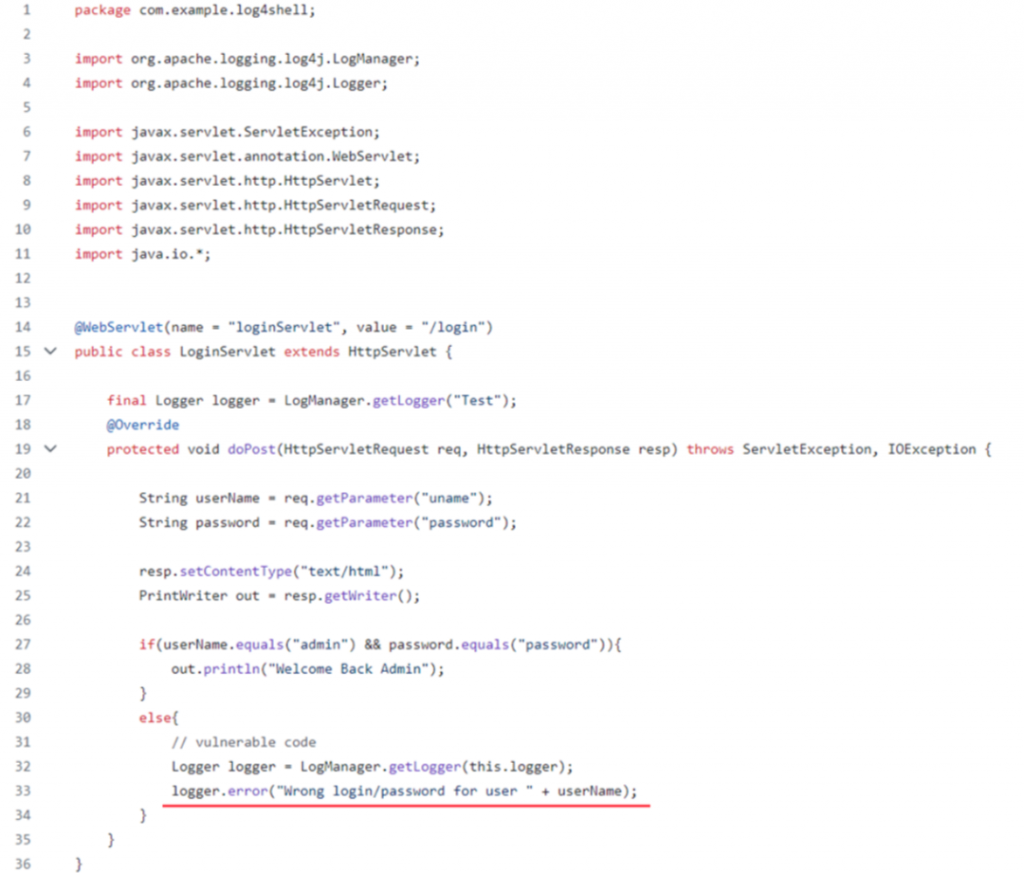
Если посмотреть ветку import, поведение меняется. Включение библиотеки есть, но кроме инициализации логгера других вызовов нет. Значит, хоть библиотека и присутствует, подключена и описана, фактически опасный метод из нее в пользовательском коде не используется. Если анализатор найдёт тут уязвимость библиотеки, это будет false positive. Код из этой ветки:
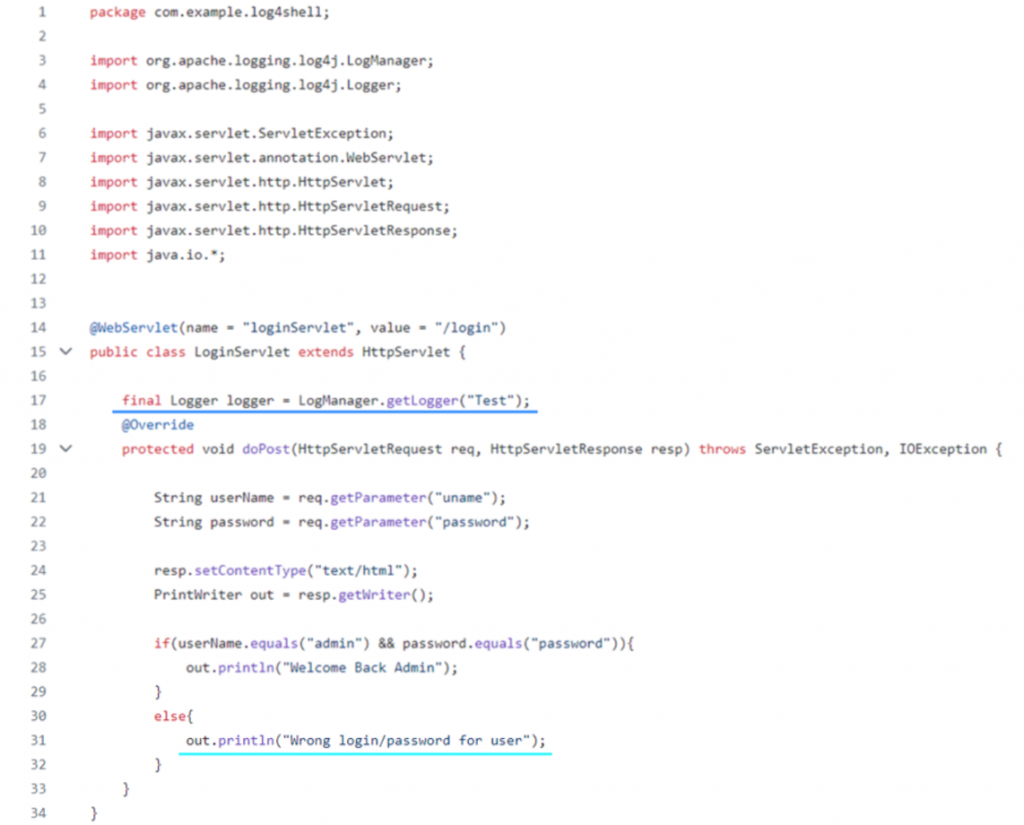
Есть еще одна ветка secure. Тут уже вызов метода для логирования, но без возможности внедрения в нее злоумышленником опасных данных. То есть тоже false positive, но более сложный. К этому примеру будем обращаться, если SCA-инструмент успешно справится с веткой import. Код из ветки secure ниже:
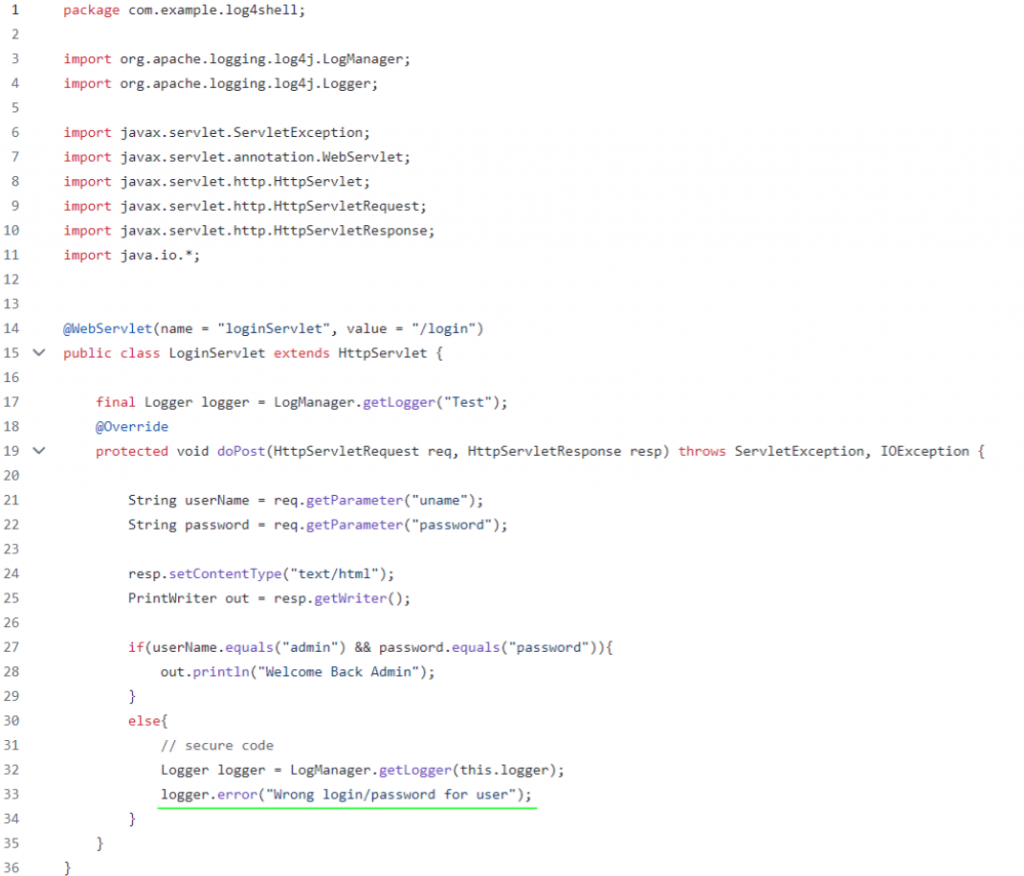
Итого имеем три примера: import, vulnerable и secure. Первый будет базовой проверкой качества анализа, второй может пригодиться для того, чтобы удостовериться, находится ли уязвимость Log4Shell в принципе, а третий — это задача со звездочкой. Чем лучше себя покажет анализатор в этих примерах, тем больше головной боли по разбору результатов он может снять с пользователя. Итак, поехали.
OWASP Dependency-Check
Популярный открытый инструмент от известного сообщества. И большое им спасибо за него (без иронии)! У продукта есть свои плюсы и минусы, но он вполне может подойти многим компаниям. А если говорить про пример с Log4Shell по ссылке выше — тут все плохо.

А в качестве доказательств присутствия уязвимостей приводятся jar, pom, manifest и другие файлы. То есть просто проверка по наличию описания библиотек в pom.xml и наличию файлов в проверяемом каталоге. На первом же примере мы получаем false positive, поэтому другие примеры проверять нет смысла. Ставим минус в нашем тесте.
grype (+Syft)
Следующий кандидат. Хороший инструмент с большим списком поддерживаемых технологий, надежно работающий в связке с Syft, про который мы выше позитивно отзывались. Это должно способствовать довольно хорошему покрытию компонентов.
Запускаем сканирование. Результаты снова не радуют.
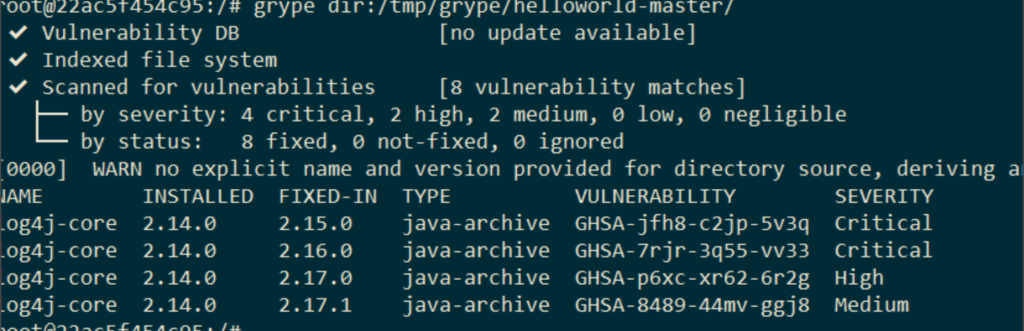
Видим, что grype тоже сообщает об уязвимостях Log4Shell, то есть история повторяется.
Snyk VS Code plugin
Теперь поговорим о коммерческих решениях, которые можно попробовать всем желающим. Компания Snyk молодая, но уже широко известна своими продуктами, исследованиями. Мне было интересно следить за тем, как они развивались и как быстро это происходило. Начинали они с SCA — благодаря сканеру и завоевали популярность. Отдельное спасибо авторам за то, что позволяют пользоваться плагином без лишних телодвижений. Что ж, проверим теперь репозиторий. История повторяется.
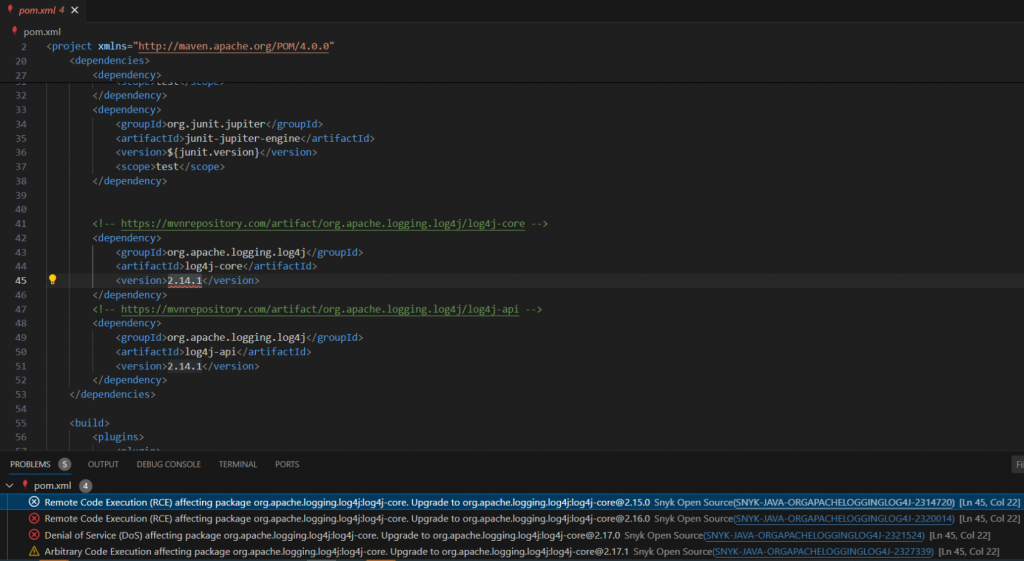
pom.xml без проверки использования. Жаль, но опять ложное срабатывание. Едем дальше.
JFrog
Известная компания в сфере работы с репозиториями, пакетами, артефактами, в том числе и со стороны безопасности ( сам сканер). Позиционируют себя как универсальную платформу для DevSecOps и MLOps. Проводят свои исследования, публикуют отчеты, вебинары. В общем, большой и известный игрок на рынке. Сразу заинтересовало упоминание conextual analysis. Кажется, это то, что должно помочь с нашей проблемой. Компания предоставляет 14-дневный триал, которым я и воспользовался. В рамках него я попробовал плагин для того же VS Code, который позволяет проводить анализ пакетов. И получил более интересные результаты.
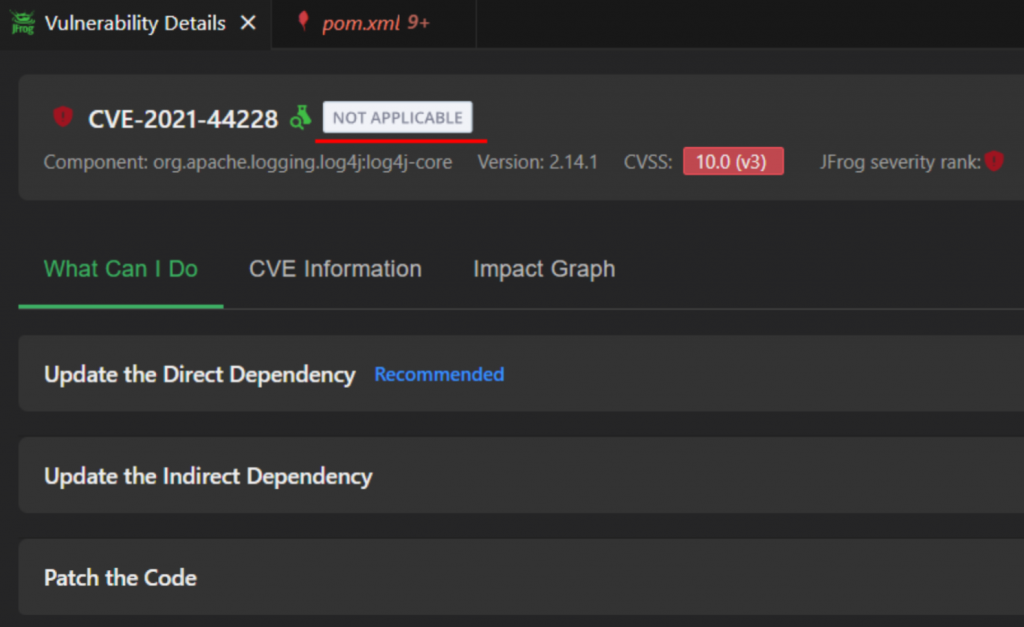
Объясню: инструмент говорит, что уязвимый пакет есть и не применяется. Следом запускаем проверку на ветке secure, до чего мы пока еще не доходили. И снова получаем результат с пометкой Not applicable. А это значит, что учтено отсутствие опасных данных в вызываемом методе пакета. То есть, похоже, используется taint-анализ для проверки, возможна ли эксплуатация уязвимости, что довольно хорошо. Но не все гладко: отметка есть только у одной уязвимости, остальные без пометки применимости, хотя для них история будет аналогичной.
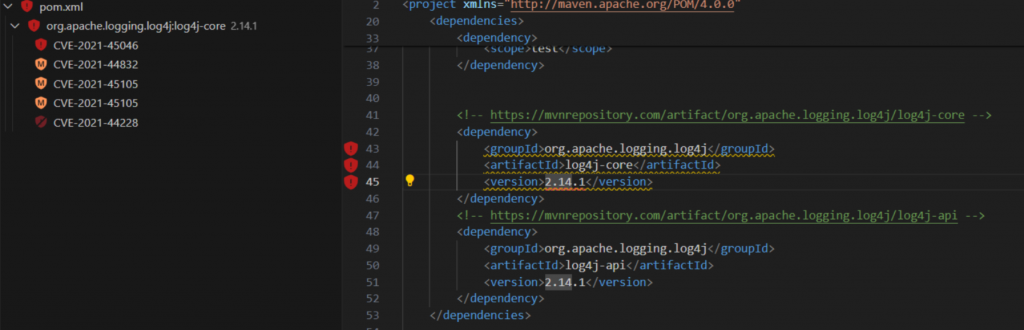
Что имеем: направление хорошее, но реализация далека от идеала, контекст учитывается не для всего, хотя подход к контексту перспективный.
Semgrep
Компания Semgrep широко известна в кругах AppSec своим решением для анализа кода и большим активным сообществом. Не так давно она анонсировала решение для защиты цепочек поставок, на него и посмотрим. Из ключевых акцентов в описании продукта как раз указано избавление от false positive за счет проверки достижимости. Это я и намерен был проверить.
Для Maven есть особенности проверки проектов: нужно предварительно выгрузить зависимости в файл. Подробнее про это написано тут.
После окончания проверки уязвимости появились, даже есть отметка про недостижимость:
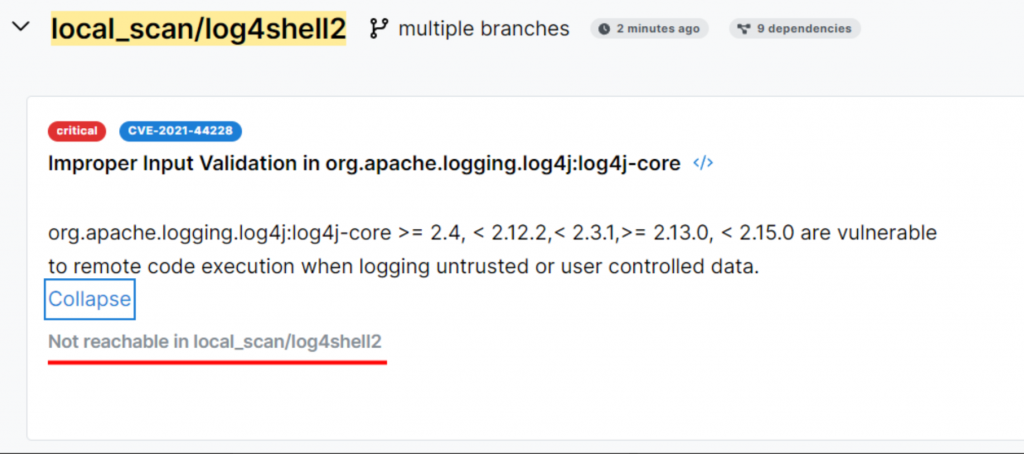
Тест пройден, так что идет в ветку secure. И тут уже результат расстроил: отметка об использовании проставлена для безопасного кода.
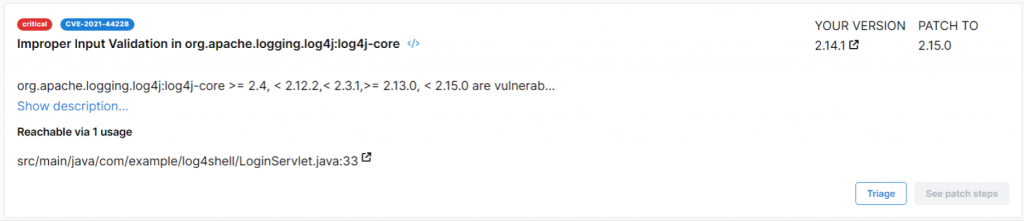

По всей видимости, taint-анализ тут не применяется.
Сам инструмент мне очень интересен, так что я дополнительно проверил еще пример из статьи, доступный тут. Для него результаты уже релевантны, предварительных действий не потребовалось, отсылки к коду корректные, использование библиотеки присутствует и представляет опасность.
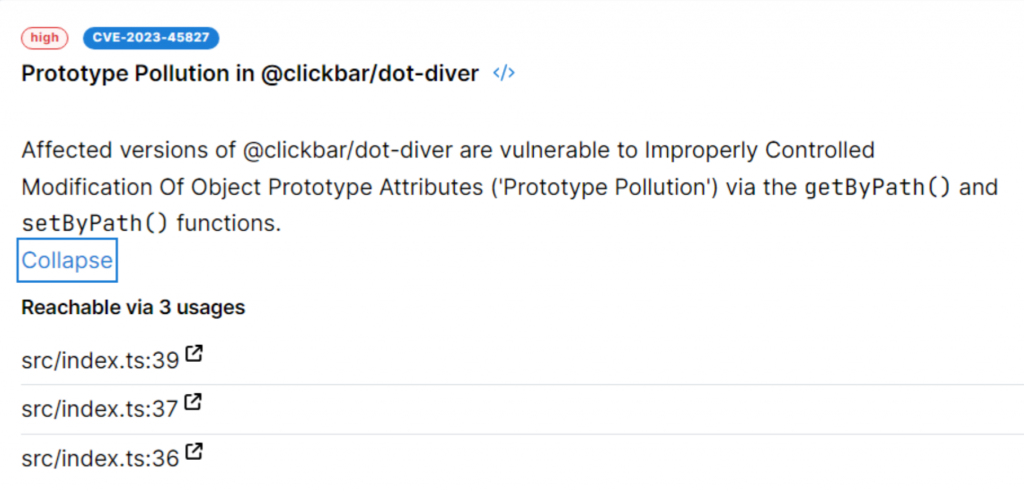
В целом фича достижимости важная, может быть реально полезной при работе с большим числом результатов, так как позволяет отбросить часть нерелевантных сработок. Semgrep выбрали правильное направление для работы, но немного не дошли до идеального результата.
Вместо итога
В статье прошелся по основным моментам в контексте SCA-инструментов, дал базовое представление и направление для исследований, рассмотрел несколько популярных анализаторов, а также чуть подробнее рассказал об одной из значимых и сложных проблем текущих инструментов. Из рассмотренных анализаторов JFrog и Semgrep показывают более интересные результаты в контексте достижимости, но каждый со своими проблемами. Первый обладает более мощным контекстным анализом, но применяет его не ко всей базе знаний. Второй сделал проверку достижимости для всех уязвимостей в базе знаний, но не использует taint-анализ, из-за чего тоже выдает ложные срабатывания.

