
Коллеги, всем привет! Меня зовут Илья Косынкин. В компании Positive Technologies я руковожу разработкой продукта для глубокого анализа трафика в технологических сетях — PT ISIM. На проектах в различных компаниях мы много сталкиваемся с практическими вопросами о том, как выстроить мониторинг ИБ в АСУ ТП. И это закономерно, ведь наша система решает именно эту задачу. Появилась идея описать, какую пользу может принести мониторинг ИБ в АСУ ТП, не уходя глубоко в детали функциональности продуктов, их классов и возможной архитектуры внедрения в инфраструктуру компании. Только value от этого процесса, без описания cost. При этом постараюсь рассказать вам научно-популярно, без воды. А для наглядности я буду использовать в статье скрины интерфейсов наших решений.
Если интересно — добро пожаловать под кат.
Мониторинг технологических сетей до сих пор остается одним из самых сложных процессов в обеспечении информационной безопасности предприятий. К этому приводят большой «зоопарк» технологий, применяемых на производствах, использование устаревших версии операционных систем и прикладного ПО, сложности во взаимодействии разных подразделений. Растет число продуктов, которые собирают сведения из технологического сегмента. В дополнение к методам сбора событий, не требующим активного взаимодействия с оборудованием (читай: анализу трафика), популярными становятся методы, связанные с активным подключением (например, безопасные запросы, агенты, устанавливаемые на конечных точках). Но для многих специалистов по ИБ все таким же непонятным остается вопрос: а на что, собственно, обращать внимание при мониторинге ИБ в АСУ ТП?
Попробуем ответить на него. Кроме того, на примере прошедшей в ноябре 2023 года кибербитвы Standoff посмотрим на события безопасности и на то, как они отображаются в PT ISIM и MaxPatrol SIEM .
Типовые векторы атак на технологическую сеть
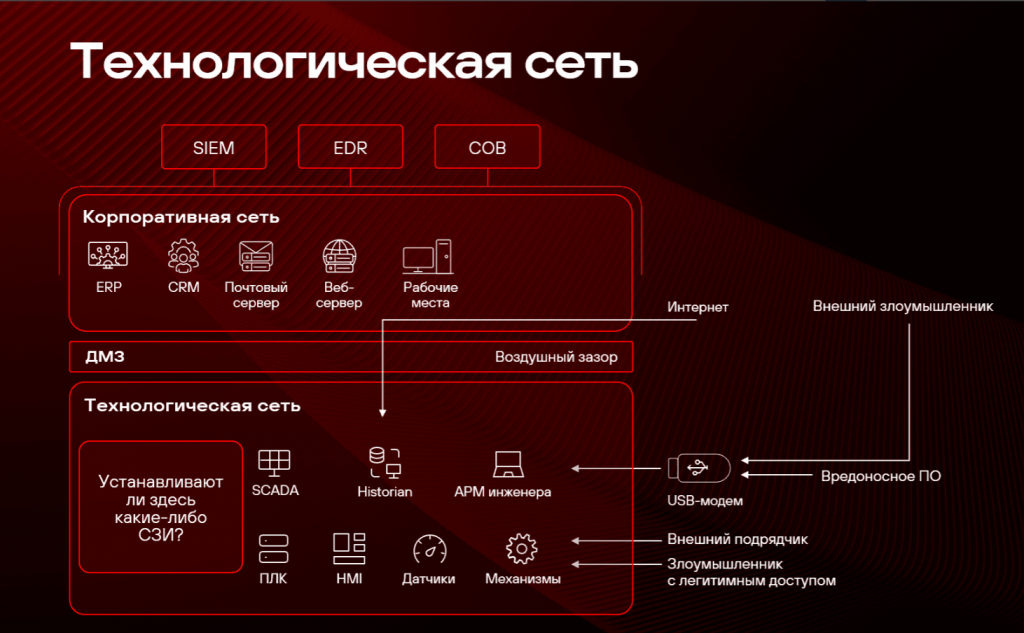
Сеть предприятия обычно состоит из корпоративного и технологического сегментов. Технологический сегмент, как правило, изолирован. В нем могут быть реализованы недопустимые события, которые приведут к нарушению непрерывности бизнеса и параметров качества выпущенной продукции, а также к выходу из строя оборудования. Недопустимые события, которые могут быть реализованы в корпоративной сети, имеют другой профиль и меньше влияют на непрерывность бизнеса. Но в этой сети есть выход в интернет, что делает ее доступной для атак. Давайте рассмотрим несколько наиболее популярных векторов атак:
-
Как обычно строится система обеспечения информационной безопасности таких структур? В корпоративной сети развернут полный комплекс имеющихся средств защиты (решения класса SIEM, EDR , антивирусы, межсетевые экраны, системы анализа трафика), а технологический сегмент изолирован воздушным зазором. Этот подход имеет определенные недостатки. Прежде всего потому что корпоративные и технологические сети все больше сливаются. Возникают мосты через воздушный зазор, нужные среди прочего для решения рабочих и бизнес-задач. Злоумышленник, получив доступ к сети и перемещаясь по ней, может оказаться в технологической сети и сделать там что-нибудь нехорошее.
-
Сотрудники могут подключать к АРМ в технологической сети сменные носители и внешние модемы, несмотря на то что это, скорее всего, запрещено внутренними регламентами. На сменном носителе может быть ВПО, обычно так и начинается заражение. Модем раскроет доступ из технологической сети в интернет там, где он не предусмотрен и быть его не должно.
-
Еще один вектор атаки — через подрядчиков, которые обслуживают и поддерживают технологическое оборудование и у которых есть удаленный доступ к промышленной сети. При этом неизвестно, насколько хорошо защищена ИТ-инфраструктура подрядчика. Если его взломают, то злоумышленник может получить доступ напрямую в технологическую сеть, минуя все СЗИ, которые есть в корпоративной сети.
Поэтому, несмотря на воздушный зазор, злоумышленник может оказаться в технологической сети и реализовать недопустимое событие.
Таким образом, технологическую сеть нужно защищать. Если в нее проник злоумышленник — службе ИБ нужно видеть, что он делает в инфраструктуре. Ниже детально разберем самые распространенные угрозы для технологических сетей, отслеживая которые можно успеть остановить злоумышленника до реализации недопустимых событий.
Угроза № 1. Нарушение периметра технологической сети
Почему это важно
Многие технологические сети проектировались с учетом того, что будут изолированы от интернета или даже корпоративной сети предприятия. Эта эффективная мера защиты, часто именуемая воздушным зазором, позволяет затруднить доступ злоумышленника к системам, в которых реализуются недопустимые события: SCADA-серверу, ПЛК, АРМ инженеров и операторов АСУ ТП.
Как следствие, нарушение периметра может быть одним из первых признаков развивающейся атаки на технологическую сеть.
Кроме того, выход в интернет, особенно с узлов, на которых не установлены средства защиты конечных точек, может привести к заражению устройств вирусами-шифровальщиками или к появлению бэкдоров, которыми злоумышленники воспользуются в обход установленных на других маршрутах средствах защиты.
Как отслеживать подобные события и реагировать на них
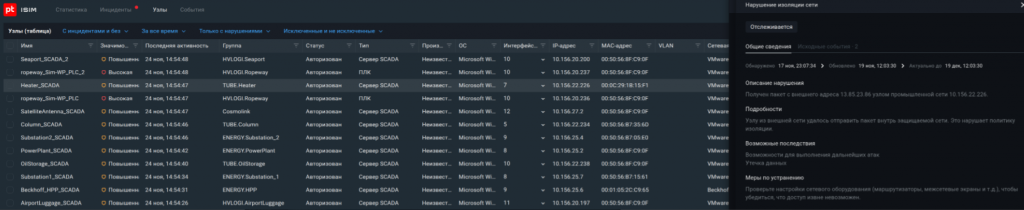
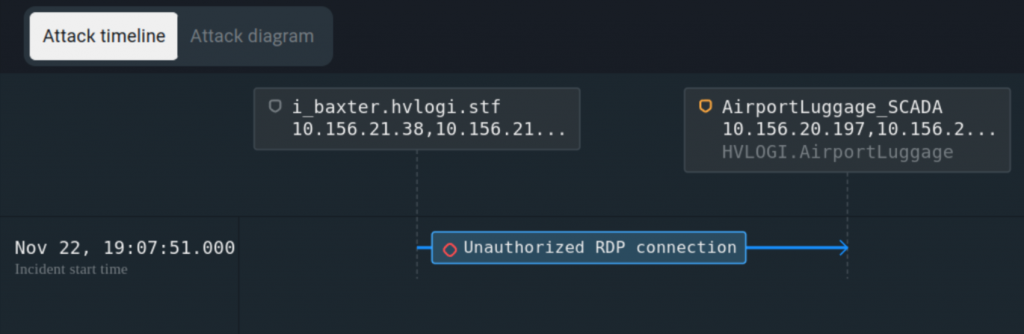
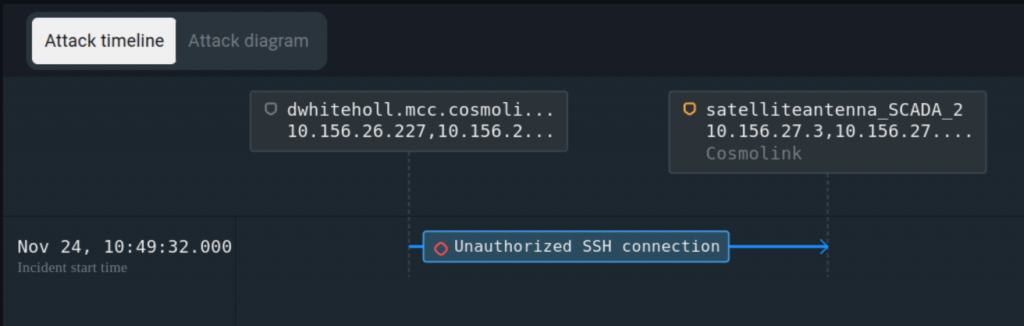
Отслеживать нарушения периметра удобнее всего через анализ внешнего сетевого трафика технологической сети. Любой удаленный доступ к технологической сети приведет к сопутствующей сетевой активности по протоколам удаленного доступа, вроде RDP и SSH.
В самом простом случае подключение будет осуществляться между узлами, которые никогда ранее не имели такой активности. Например, какой-то узел из корпоративной сети провзаимодействовал с АРМ оператора по протоколу SSH, хотя такие соединения запрещены политикой ИБ предприятия и на первый взгляд не требуются для осуществления бизнес-процесса.
Для того чтобы отлеживать появление новых соединений, система обеспечения информационной безопасности (далее СОИБ) должна запомнить соединения в рамках легитимных сетевых коммуникаций и формировать события безопасности в случае появления новых соединений.
При появлении подобных событий лучше всего выяснить у специалистов службы эксплуатации АСУ ТП, является ли коммуникация штатной. Вполне возможно, что технологическая сеть просто модифицируется для обеспечения эффективности производственного процесса. В таком случае сетевую активность нужно зафиксировать как разрешенную и далее не реагировать на нее.
Возможны и более сложные случаи атак, которые уже не фиксируются простым анализом нелегитимных соединений. Если учетная запись администратора, который регулярно подключается из корпоративной сети к АРМ в технологической сети по протоколу RDP была украдена, то выявить аномальную активность можно только анализируя детали поведения пользователя после подключения либо анализируя другие параметры сетевого соединения (например, подключение произошло в воскресенье, когда все администраторы в офисе отсутствовали).
Стоит также заметить, что доступ в интернет может появиться благодаря подключению интернет-флешки. Выявлять в трафике подключение таких устройств сложно, так как сетевое оборудование, на котором обычно развертываются средства мониторинга, не отслеживает трафик интернет-флешки. Обнаруживать такие нарушения лучше средствами защиты конечных точек, которые могут не только предупредить о подключении интернет-флешки, но и заблокировать его.
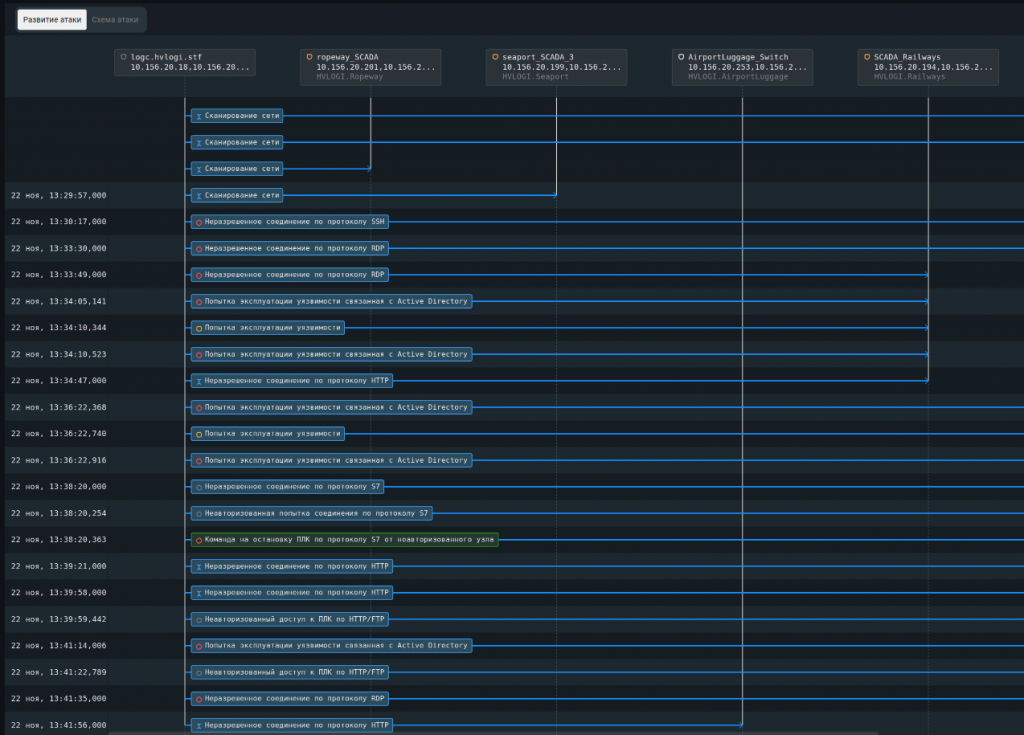
Ниже приведены примеры подобных нарушений изоляции сети, выявленных PT ISIM в инфраструктуре Standoff в ходе кибербитвы в ноябре 2023 года.
Как отслеживать подобные события и реагировать на них
Угроза № 2. Атаки на ОС, ПО, сетевое оборудование, активность ВПО
Почему это важно
Как правило, на устройствах верхнего уровня технологической сети (на АРМ инженеров и операторов, SCADA-серверах) специализированное ПО, необходимое для осуществления технологического процесса, установлено поверх классических ОС — Windows и Linux. Это автоматически означает, что большая часть эксплойтов, которые злоумышленники используют в корпоративных сетях, применимы и к верхнему уровню технологической сети. Более того, устройства технологической и корпоративной сети могут в принципе быть неразличимы на сетевом уровне, и вирус-шифровальщик, проникший в корпоративный сегмент, может случайно наткнуться на забытый сетевой маршрут до технологической сети и зашифровать все АРМ и серверы. Это приведет к потере возможности управлять технологическим процессом или его полной остановке.
Усложняется этот момент тем, что операционные системы в технологических сетях редко обновляются и, как правило, на предприятиях отсутствуют регламенты регулярной установки security-обновлений на эти устройства. Это приводит к тому, что атака, о которой в корпоративных сетях все давно уже забыли, может случайно выстрелить в технологическом сегменте с самыми тяжелыми для предприятия последствиями.
Как отслеживать подобные события и реагировать на них
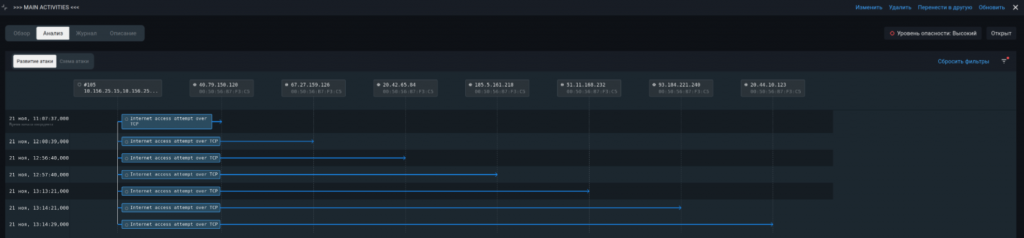
Для отслеживания подобной активности СОИБ, используемая в технологическом сегменте, должна содержать экспертные правила выявления угроз и средства противодействия техникам, применяемым к ИТ-инфраструктурам на базе Windows и Linux.
В комплекте экспертизы СОИБ должны быть средства, позволяющие обнаруживать:
-
Попытки эксплуатации уязвимостей.
-
Техники сетевых атак на распространенные ОС.
-
Техники атак, осуществляемых на узлах.
-
Запуск утилит, регулярно используемых злоумышленниками, например, для повышения привилегий, перемещения внутри периметра.
-
Активность вредоносного программного обеспечения (ВПО).
Важно отметить, что часто правила из этой категории пишутся для конкретной активности, которая специфична для конкретной техники, и склонны давать небольшое число ложноположительных срабатываний. Проще говоря, выявление подобных событий безопасности с высокой долей вероятности говорит о присутствии в сети злоумышленника и требует оперативного расследования. Однако возможны ситуации, когда правила реагируют на штатную активность в сети. Например, правило, фиксирующее сканирование сети, может срабатывать на сканер уязвимостей, который рассылает много сетевых пакетов на разные устройства за короткое время. В этом случает требуется донастройка правила, чтобы исключить повторную фиксацию подобных событий безопасности и сопутствующее расследование.
Для распространенных атак также может применяться автоматическое реагирование, особенно если оно протестировано на совместимость с производителем АСУ ТП.
И давайте снова посмотрим на примеры подобных атак, выявленных PT ISIM на последнем Standoff.
Угроза № 3. Атаки на ПЛК
Почему это важно
Программируемые логические контроллеры (ПЛК) располагаются на среднем уровне технологической сети. Именно ПЛК взаимодействуют с реальными датчиками и исполнительными механизмами и могут оказывать влияние на их работу. Операторы и диспетчеры, как правило, не работают с ПЛК напрямую, а взаимодействуют через пользовательский интерфейс SCADA-системы. А вот между SCADA-системой и ПЛК, напротив, осуществляется интенсивный обмен индикациями и командами. С помощью индикаций ПЛК рассказывают SCADA-системе о значениях параметров технологического процесса (давление масла, скорость двигателя, температура котла). С помощью команд оператор или алгоритм, заложенный в SCADA-систему, переключает режимы работы оборудования, меняет уставки, осуществляет регулирование.
Имея возможность оказывать воздействие на ПЛК, злоумышленник может добиться различных последствий. Например:
-
Подменить значения индикаций, которые видит оператор АСУ ТП. В случае если речь идет об управлении удаленным объектом, это может привести к проблемам, которых оператор даже не заметит.
-
Отправить команду, которая переведет технологический процесс в неверное состояние (состояние, которого бы не было без злонамеренного вмешательства) и вызовет аварию.
-
Незаметно изменить установки работы оборудования, что приведет к его ускоренному износу или позволит украсть важные ресурсы предприятия.
-
Лишить персонал возможности отправлять команды на ПЛК, что приведет к нарушению управления технологическим процессом.
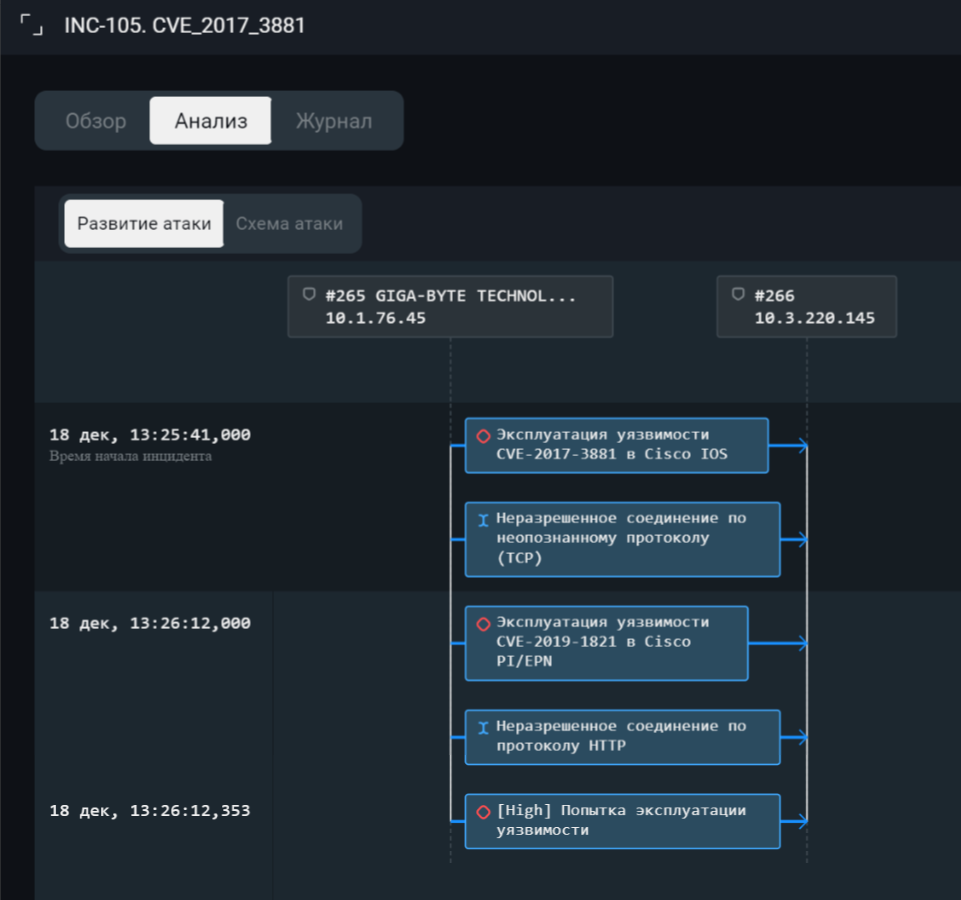
Таких результатов злоумышленник может добиться отправляя на ПЛК «легитимные», «штатные» команды либо эксплуатируя уязвимости. На рынке очень много ПЛК как от отечественных, так и от зарубежных вендоров. К сожалению, многие из этих продуктов редко исследуются на уязвимости, поэтому их либо не устраняют вовсе, либо исправление занимает длительное время, чем и пользуются злоумышленники.
Примеры уязвимостей в ПЛК:
Возможность выполнять привилегированные операции без авторизации либо с авторизацией, которую легко обойти.
Недокументированные команды, которые дают возможность вызвать отказ в работе устройства.
Отказ в работе устройства, вызванный обращением к несуществующим портам (например, запустив сканирование сети, злоумышленник может вывести ПЛК из строя и даже не заметить этого).
Как отслеживать подобные события и реагировать на них
К счастью, многие вендоры ПЛК все же ответственно подходят к исследованию и исправлению уязвимостей в своих устройствах. Они публикуют бюллетени безопасности, и часто уязвимости можно устранить с помощью обновления прошивки. Вендорам активно помогают в этом процессе исследователи из компаний, которые производят продукты для обеспечения ИБ в технологических сетях (например, 1 , 2 , 3 и 4 ).
Для отслеживания попыток подобных атак в инфраструктуре важно, чтобы в СОИБ, используемой в технологической сети, были заложены правила и индикаторы обнаружения промышленных угроз.
Традиционно делюсь примером подобной атаки, обнаруженной PT ISIM.
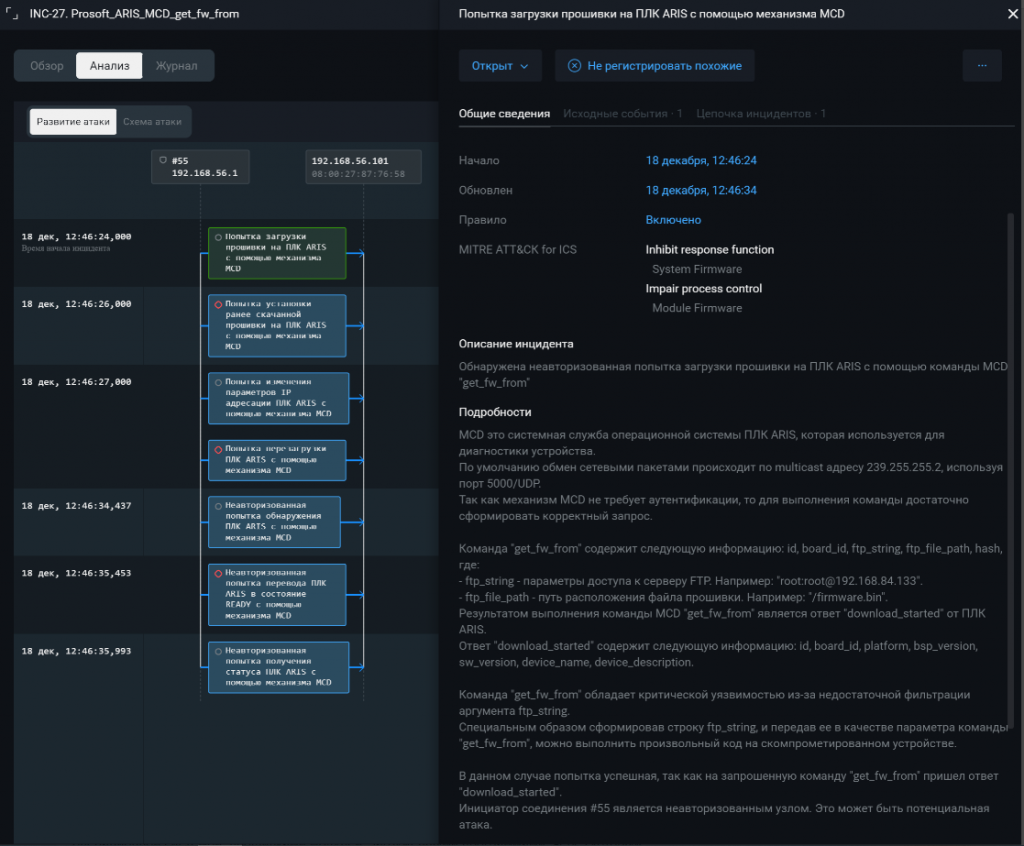
Угроза № 4. Сервисные команды взаимодействия с ПЛК
Почему это важно
Эксплуатация уязвимостей ПЛК — не единственный возможный кейс атаки на такие устройства. Иногда опасность может нести и использование злоумышленником штатных функций ПЛК. Рассмотрим детальнее этот момент.
Большая часть ПЛК в реальности представляет собой промышленный компьютер с собственной операционной системой, прошивками модулей, загруженными программами, через который проходят технологические процессы. Программируются ПЛК с помощью специализированных IDE и имеют свои API, через которые IDE и выполняет настройку. Типичные примеры таких API:
-
Команды на запуск и остановку ПЛК.
-
Команды на обновление исполняемой программы или скачивание ранее загруженной программы.
-
Отладочное чтение и запись переменных в памяти ПЛК в обход логики основной программы.
Во время разработки программ для ПЛК все эти функции полезны. Но во многих ПЛК эти операции можно выполнить без авторизации. Часто они описаны в публичной документации к основному протоколу, который управляет ПЛК, либо их можно найти на GitHub. Злоумышленник, имеющий сетевой доступ к ПЛК, может легко выполнить любое из этих действий. А учитывая, что сети во многих технологических сегментах плоские, хакер получает такие возможности сразу после проникновения.
Какие проблемы может доставить злоумышленник, использующий сервисные команды ПЛК:
-
Запуск и остановка ПЛК.
Остановка приведет к тому, что ПЛК не будет отправлять индикации, принимать команды, а какая-то часть технологического процесса может просто остановиться. Кроме того, опасность кроется и в том, что часто в ПЛК закладывают real-time-функции, такие как регулирование, и остановка технологического процесса может привести, например, к порче оборудования, управляемого с ПЛК. К счастью, такие операции легко обнаружить. Более того, продвинутые SCADA-системы показывают, какой конкретно ПЛК был остановлен. Но ведь злоумышленник может быть хитер. Он может, например, написать скрипт, который удаленно обнаружит, что ПЛК был запущен, и повторно его остановит. В этом кейсе важно выявить, с какого устройства в сети выполняется такое воздействие. И здесь SCADA-система уже не поможет, так как она не отслеживает все устройства в сети.
-
Загрузка новой исполняемой программы или скачивание ранее загруженной программы.
В исполняемой программе заложен весь смысл бизнес-функции на конкретном ПЛК. Скачав программу, злоумышленник может «вынести» ее из инфраструктуры для детального изучения. Он может свободно экспериментировать, без риска быть замеченным с помощью мониторинга. А установив в ПЛК модифицированную программу, можно, например, отключить заложенные в ней защитные механизмы либо изменить установки технологического процесса, и тогда оборудование будет быстрее изнашиваться. Отследить последствия таких перепрошивок сложнее, так как формально ПЛК продолжает исправно работать и внешние проявления могут быть незаметны.
-
Отладочное чтение и запись переменных в памяти ПЛК в обход логики основной программы.
Зачем нужна возможность записи и чтения под отладкой, знает любой программист. Это удобный инструмент, позволяющий упростить написание программ и тестирование сложно воспроизводимых ситуаций. Аналогичные инструменты есть и во многих ПЛК. Часто, кроме непосредственной записи и чтения, возможна так называемая форсированная запись, когда та или иная переменная (и показатель соответствующего входа или выхода ПЛК) принимает заданное значение и не меняет его до снятия форсирования. Такая запись может привести, например, к тому, что операторы не будут видеть реального значения показателей технологического процесса либо не смогут выполнить команду из интерфейса, в котором привыкли работать.
Как отслеживать подобные события и реагировать на них
Несмотря на кажущуюся сложность, отслеживать подобные воздействия довольно просто. Помогают два фактора:
Фактор № 1. Многие сервисные команды документированы и являются частью протокола управления ПЛК. Этот фактор полезен не только злоумышленникам, которые могут получить инструмент для атаки на оборудование «из официальных источников», но и средствам мониторинга, отслеживающим появление в сети таких воздействий. Основная сложность для средств мониторинга — это вопрос, как отличить воздействие злоумышленников от штатной деятельности инженеров. Самый простой ответ — спросить у инженеров. Но есть и другие приемы, позволяющие «расширить контекст». Например, в случае если команда посылалась со скомпрометированного узла (на нем уже зафиксированы успешные атаки), то с высокой долей вероятности это может оказаться злоумышленник. В анализе таких событий также помогает второй фактор.
Фактор № 2. Сервисные команды редко выполняются в реально работающей АСУ ТП. Как правило, технологический процесс настраивается только один раз, а изменения в параметры работы вносятся во время технологических окон. Как следствие, любая подобная команда, выполненная вне обозначенных графиков работ, — это повод для проведения небольшого расследования.
Сложным кейсом обнаружения остается перепрошивка контроллеров, которая выполнялась не по сети, а локально, с флешки. Отследить такие воздействия пассивным анализом трафика невозможно. Но их можно обнаружить активно взаимодействуя с оборудованием. Например, периодически считывать с ПЛК прошивку и сверять хеш-суммы файлов. Кроме того, многие ПЛК могут сообщать SCADA-системе об изменении прошивки. Таким образом, анализ журналов SCADA-системы поможет отследить такие воздействия.
Угроза № 5. Использование слабых и словарных паролей в устройствах
Почему это важно
Многие знают, что, если установить домой новый роутер, нужно сменить дефолтный пароль администратора. Аналогичные меры важны и для устройств технологической сети.
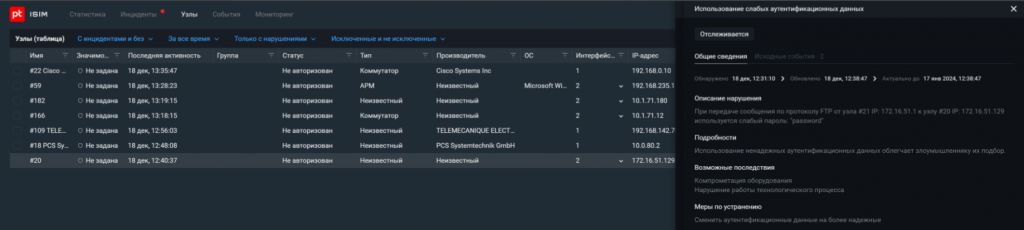
Например, ПЛК может иметь веб-интерфейс для настройки параметров, доступ к которому может быть закрыт паролем и работать только по протоколу HTTPS. Вроде все хорошо с точки зрения безопасности. Но если учетная запись, используемая для доступа, имеет дефолтный пароль, то злоумышленник может получить доступ к ПЛК с любого устройства, которое имеет сетевой доступ к контроллеру. Более того, он может сменить пароль, тогда администраторы технологической сети потеряют доступ к устройству.
Похожая проблема может возникать при использовании слабых паролей, которые легко подбираются злоумышленником по базам таких паролей.
Кроме того, возможна проблема, когда для доступа к устройству были заведены новые учетные записи с сильными паролями, но дефолтные записи остались неотключенными.
Как отслеживать подобные события и реагировать на них
Лучший способ выявлять подобные проблемы — это проактивный аудит устройств, отлеживающий, какие учетные записи используются на устройствах, в операционной системе, программном обеспечении. Этот способ требует доступа к оборудованию, но позволят надежно отследить появление новых учетных записей и забытые дефолтные. Но в этом случае возникают проблемы контроля сложности пароля. Он обычно хранится в зашифрованном виде либо в виде хеш-значений. В таком виде самый простой пароль не отличается от самого сложного. Хорошо, если в используемом оборудовании, как в распространенных операционных системах, можно установить требования к сложности пароля. В этом случае необязательно знать сам пароль, чтобы быть уверенным в том, что он удовлетворяет нужным требованиям. Но такие возможности есть не во всех устройствах.
Альтернативным способом выявления использования слабых паролей или дефолтных учетных записей может быть анализ сетевого трафика. Во многих протоколах существует операция login, и, если протокол не зашифрован, во время этой операции хотя бы один раз передаются учетные данные. Хранения таких данных на СЗИ небезопасно, так как злоумышленник, успешно атаковавший СЗИ, получит доступ к базе паролей, используемой в инфраструктуре. Но пароли можно проанализировать на лету, сравнив, например, с базой слабых паролей, и обратить внимание оператора на то, что в инфраструктуре используются дефолтные учетные записи либо учетные записи с известными словарными паролями.
Реагировать на такие события незамедлительно не требуется (конечно, если это не устройство, которое имеет доступ в интернет или смежные сети). Перед сменой пароля нужно проанализировать, в каких процессах используются учетные записи со слабыми паролями. Может оказаться, что под такой учетной записью к устройству подключается какой-либо сервис, тогда он прекратит работать, если пароль сменить только на самом устройстве.
Так выглядят слабые пароли, выявленные PT ISIM в сетевом трафике.
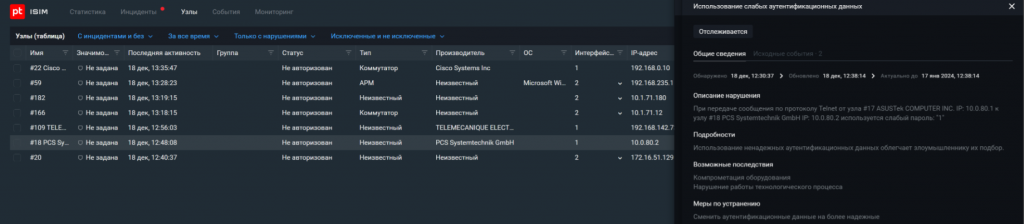
Угроза № 6. Использование слабозащищенных версий протоколов
Почему это важно
Слабозащищенные версии протоколов так же опасны, как и уязвимости. Они фактически дают злоумышленнику возможность легко получить нелегитимный доступ к информации либо оказать воздействие на бизнес-процесс.
Долгий жизненный цикл ИТ-систем в технологических сетях приводит к тому, что многие слабости общесетевых протоколов, о которых в обычных инфраструктурах уже забыли, в технологических продолжают оставаться актуальными годами.
Особенностью протоколов, используемых во многих АСУ ТП, является то, что они проектировались без требований к шифрованию данных или даже к авторизации. Так было из-за требований к производительности или слабых каналов связи. В качестве примера можно привести широко используемый протокол Modbus, когда фактически любой пользователь с устройства, имеющего сетевой доступ к ПЛК, может послать тот же сигнал, что и SCADA-система. Тем не менее это очень широко распространенный, можно даже сказать «заслуженный» протокол в области автоматизации.
Как отслеживать подобные события и реагировать на них
Отслеживать использование слабых протоколов можно с помощью активного аудита и анализа трафика.
Средства активного аудита интересны в этом вопросе тем, что позволяют увидеть неотключенные устаревшие протоколы. Такие протоколы могут быть неактивны во время эксплуатации сети, но злоумышленник может их обнаружить, например, проводя сканирование сети.
Средства анализа трафика не увидят неотключенные протоколы, но могут практически молниеносно обнаружить использование устаревших версий протоколов в трафике, тем самым предупредив о наличии уязвимостей в инфраструктуре.
Реагирование на обнаружение таких протоколов достаточно неоднозначно. Если слабый протокол можно легко перевести на его более современную и защищенную версию — это хорошо. Но во многих системах на использовании подобных протоколов завязаны ключевые сервисы, и бесшовно провести такое обновление без привлечения организации, проектировавшей АСУ ТП, невозможно. Как следствие, такой протокол лучше не трогать, но в сценариях мониторинга нужно учитывать наличие известных слабостей на узлах, где такие протоколы активны.
Привожу примеры использования слабых протоколов.
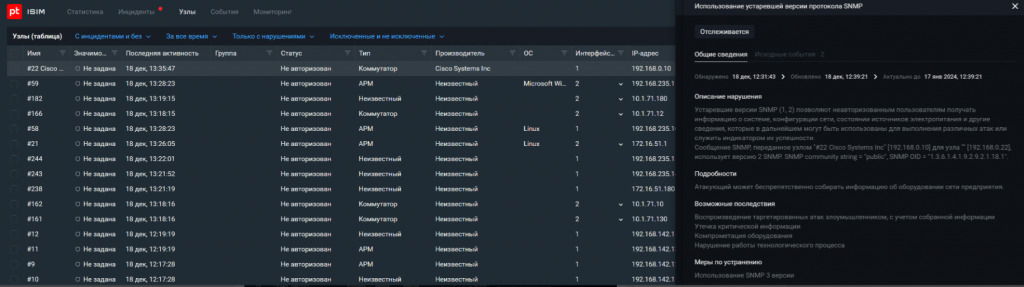
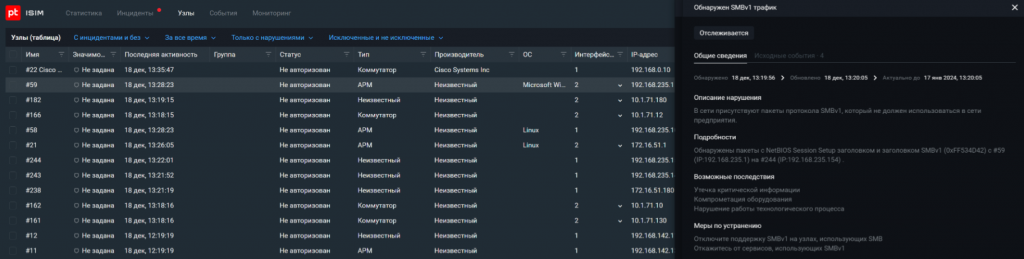
Угроза № 7. Неавторизованные чтения и записи тегов в ПЛК
Почему это важно
Тегами, или технологическими сигналами, обычно называют переменные в памяти ПЛК, в которых содержится либо текущее значение измеряемого физического показателя, либо режим работы того или иного подпроцесса в ПЛК. Иными словами, именно записывая или читая теги, SCADA-система и ПЛК обмениваются командами и индикациями.
Очевидно, что, манипулируя значениями тегов, злоумышленник может достичь негативных последствий.
Более того, известны атаки, в которых злоумышленники действовали так:
Прослушивая сетевой трафик, выясняли, какие теги протокола IEC 104 используются во взаимодействиях. Протокол открытый, без шифрования, очень широко используется в электроэнергетике для управления распределительными сетями.
В момент начала атаки осуществляли случайную запись значений в теги, что приводило к коллапсу части распределительной сети.
Как отслеживать подобные события и реагировать на них
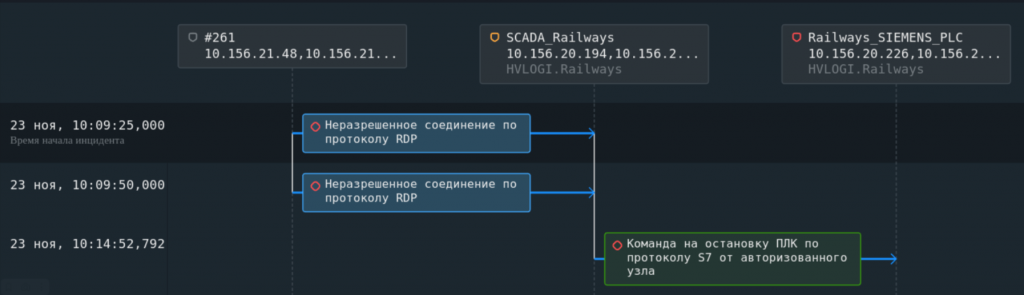
Кейс № 1. Неавторизованное взаимодействие по технологическому протоколу. Проще говоря, к ПЛК по технологическому протоколу обратился узел, который никогда ранее не осуществлял подобных операций. Этот кейс прост в обнаружении, если используются специальные средства анализа технологического трафика. Они понимают, что обращение было неавторизованным, что использовался технологический протокол, а не просто TCP-соединение, они также часто могут подсказать, какая именно команда выполнялась. Реагирование тоже довольно простое — специалисты по ИБ должны обратиться к специалистам службы эксплуатации АСУ ТП и выяснить, что за устройство подключается к ПЛК (может быть, в работу просто ввели новые устройства).
Кейс № 2. Запись тегов с авторизованных узлов. К сожалению, отслеживать такие события тяжело, так как они мало отличаются от штатного взаимодействия. Есть устройство, на котором работает оператор, с него регулярно отправляются команды на чтение и запись определенных тегов. Информировать специалиста по ИБ о каждом таком чтении и записи явно не стоит. В этой ситуации аномальные операции можно отследить либо используя заданные правила, либо используя движки для автоматического профилирования и выявления аномалий. Например, можно задать правило на случай, когда команда на остановку подсчета продукции будет выдана до того, как будет подана команда на прекращение работы установки.
Ниже привожу примеры подобных атак.
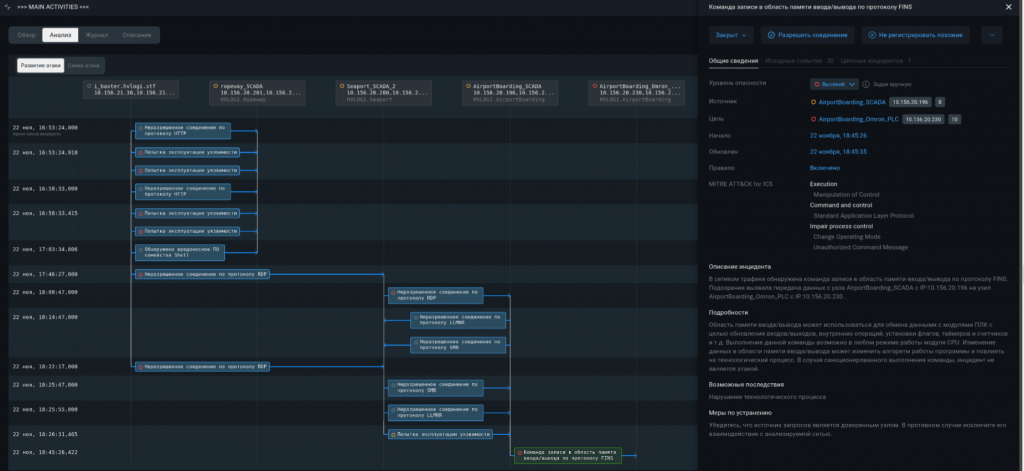
Угроза № 8. Неавторизованное взаимодействие по протоколам удаленного доступа
Почему это важно
Неавторизованное взаимодействие по протоколам удаленного доступа важно отслеживать не только на периметре технологической сети, но и во взаимодействии между ее отдельными узлами. Появление таких событий безопасности может говорить о перемещении злоумышленника внутри периметра либо о неавторизованных операциях в инфраструктуре со стороны персонала.
Как отслеживать подобные события и реагировать на них
Отслеживаются подобные события безопасности с помощью методов, описанных в кейсе о нарушении периметра.
Угроза № 9. Подмена файлов проектов в системах SCADA и HMI
Почему это важно
Файл проекта — сердце любой SCADA-системы. Именно в файл проекта чаще всего зашиты:
-
Мнемосхемы (пользовательский интерфейс), которые видит оператор.
-
Алгоритмы, по которым SCADA-система обрабатывает данные от ПЛК и от оператора.
-
Учетные записи, имеющие доступ к пользовательскому интерфейсу, и операции, которые они могут выполнять.
Чаще всего изменить поведение SCADA-системы можно просто подменив файлы проекта и перезапустив сервисы.
С помощью этого вектора атаки злоумышленник может достичь очень разнообразных и очень опасных последствий:
-
Подменить показания, которые видит оператор, скрыть от него следы аварии.
-
Отключить защитную логику, зашитую в алгоритмы SCADA-проекта.
-
Добавить учетные записи, которые имеют доступ к интерфейсу.
-
Подменить пароль пользователя (часто это просто хеш-значения, сохраненные в файле проекта), тем самым заблокировав операторам доступ к системе.
Как отслеживать подобные события и реагировать на них
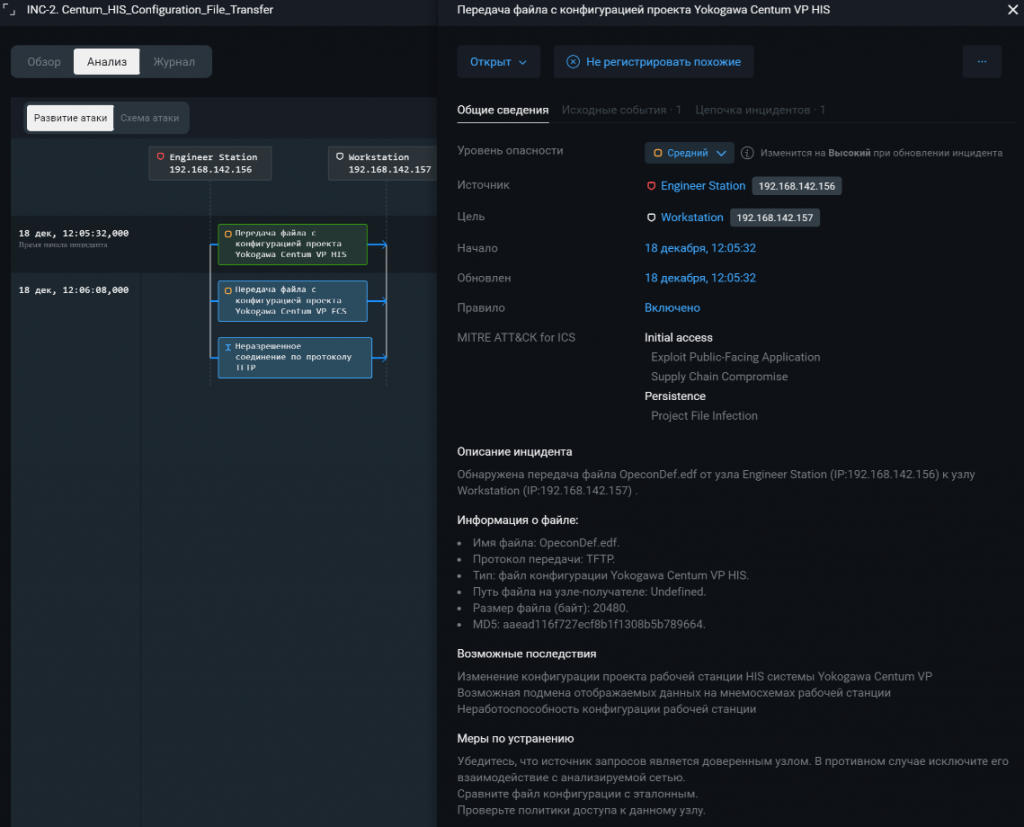
Наиболее действенная мера для отслеживания изменения файла проекта — это мониторинг с помощью SIEM- или EDR-систем. Эти продукты позволяют отлеживать непосредственно изменения в файле, независимо от того, каким образом он был изменен (обновление проекта через IDE разработчика SCADA-системы либо непосредственно в файловой системе). Но, как правило, такие системы могут зафиксировать только сам факт изменения файла и не показывают, что поменялось.
Кроме того, иногда подозрительные операции с файлами проекта можно отслеживать с помощью анализа сетевого трафика. Мы все привыкли к тому, что файлы — это что-то неразрывно связанное с файловой системой, дисками. Но файлы могут передаваться по сети, более того, часто установка проекта из IDE сопровождается его передачей по таким распространенным протоколам, как FTP, TFTP, SMB, HTTP. Как следствие, средство анализа трафика, обученное извлекать файлы из трафика и узнавать из них файлы проектов, может предупредить специалистов по ИБ о подозрительной операции.
Конечно, сам факт изменения файла проекта либо передачи его по сети не говорит о наличии в сети злоумышленника. Но может служить неплохим триггером к тому, чтобы провести небольшое расследование на узлах, где была зафиксирована подобная активность, либо обратиться к персоналу АСУ ТП и выяснить, не выполнялись ли штатные обновления на серверах.
Ниже снова привожу примеры подобных событий безопасности, выявленных PT ISIM в инфраструктуре Standoff в ходе кибербитвы в ноябре 2023 года, а также примеры событий изменения проекта, которые могут быть зафиксированы системой MaxPatrol SIEM с пакетами экспертизы, отслеживающими воздействие на прикладное программное обеспечение в АСУ ТП.
Угроза № 10. Запуск инженерного и управляющего ПО в АСУ ТП
Почему это важно
Запуск управляющих утилит обобщает многие из кейсов, описанных выше, так как позволяет подключаться к технологическому оборудованию с помощью штатных утилит (без эксплойтов). Как правило, у каждого вендора АСУ ТП имеются штатные утилиты, позволяющие выполнить диагностику оборудования, его обнаружение в сети и, конечно, перенестройку. Часто такие утилиты просто запускаются из EXE-файла и не требуют специальных прав на установку ПО. Соответственно, доставив такие утилиты на устройства технологической сети, злоумышленник может как выполнить разведку, так и оказать влияние на процесс производства.
Как отслеживать подобные события и реагировать на них
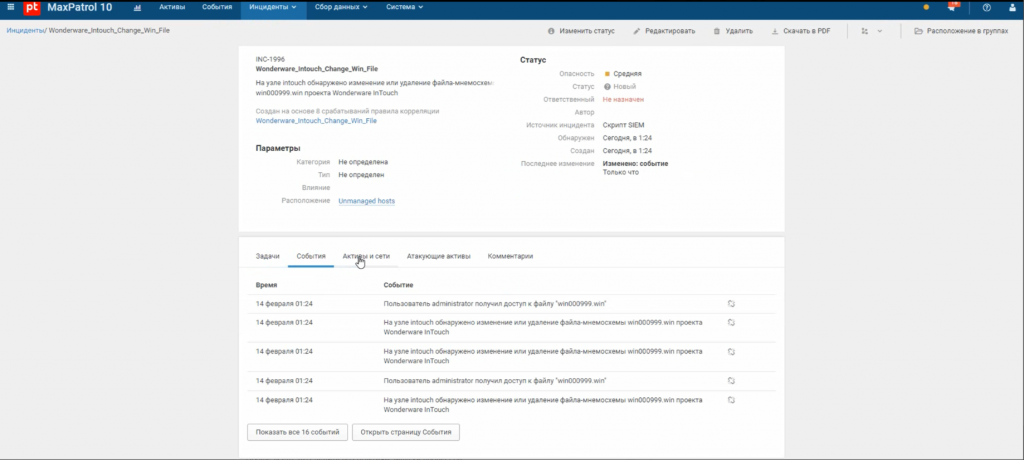
Отслеживать запуск инженерного и управляющего ПО можно с помощью SIEM- или EDR-системы. Проще всего это сделать по событиям запуска процессов.
Часто запуск такого ПО сопровождается появлением в сетевом трафике управляющих протоколов. Отслеживая появление неавторизованных соединений по таким протоколам, можно обнаружить нелегитимный запуск утилит на устройствах, где нет сбора событий SIEM-системой или не стоит система защиты конечных точек.
Конечно, запуск инженерного ПО, как и многие другие процессы в технологическом сегменте, нельзя трактовать как однозначный признак наличия злоумышленника в сети. Подобные операции могут выполняться персоналом, обслуживающим АСУ ТП. Однако практика показывает, что в реально работающих сетях подобная перенастройка случается крайне редко.
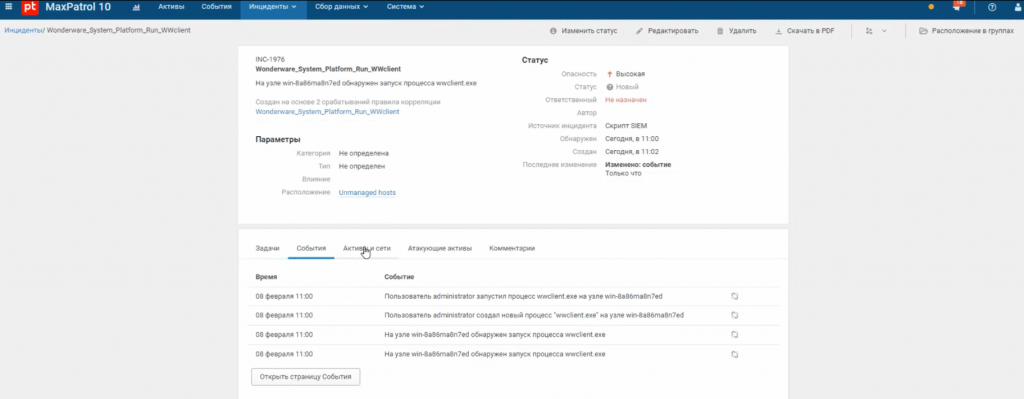
Ниже приведен пример события безопасности, зафиксированный MaxPatrol SIEM. Был отмечен запуск утилиты WWClient, позволяющей выполнять удаленное управление тегами в системе Wonderware System Platform.
Вместо заключения
Я думаю, вы заметили, что многие угрозы, с которых стоит начать выстраивать мониторинг ИБ, очень похожи на угрозы для корпоративных сетей и что их отслеживание не требует глубокого знания архитектуры АСУ ТП.
Но основной принцип информационной безопасности «Знай, что защищаешь!» особенно применим к технологическим сетям. Поэтому для начала необходимо разобраться в том, какое оборудование используется в защищаемой АСУ ТП, все ли нужные события с него поступают в используемые СЗИ и какие конкретно события безопасности СЗИ регистрируют на этом оборудовании.
А после того как будет выстроен базовый мониторинг безопасности, можно переходить к выстраиванию процессов реагирования совместно со службой эксплуатации АСУ ТП и оперативно-диспетчерским персоналом. И напоследок: будьте проактивны, анализируйте и изучайте свое оборудование, ищите в нем слабые места.

Илья Косынкин
Руководитель разработки продуктов для безопасности промышленных систем Positive Technologies

