Я много раз подступался к этой теме, но последняя заметка подхлестнула мое желание «закрыть гештальт» с этой темой и подсобрать воедино все разрозненные заметки и мысли, которые у меня были написаны на протяжении последних лет 20 с лишним. По правде говоря, я эту тему еще в своей книге «Обнаружение атак» хотел рассмотреть, но тогда ни у меня не было достаточно насмотренности и опыта, ни технологии не были достаточно развиты, чтобы предметно это обсуждать. А сейчас вроде и можно уже.
Итак, можно ли предсказать кибератаки? Начну с того, что сам по себе термин «предсказание» не самый лучший, как и «пророчество», «ясновидение» и «гадание», в отличие от «прогнозирования«, которое позволяет обоснованно и даже научно судить о будущем состоянии объекта исследования. Не буду писать про экспертные методы, которые сложно воспроизводимы и слишком зависимы от квалификации и роли эксперта. И про статистические методы не буду (может быть позже). А вот методы моделирования при прогнозировании кибератак вполне применимы; более того, активно применяются.
Очевидно, что для прогнозирования нам нужны данные и много. А потом эти данные надо будет анализировать, что требует соответствующей квалификации и инструментария. Можно попробовать снизить требования к первому, но тогда они увеличатся ко второму; и наоборот. У нас в стране пока сложно с обоими вариантами. Исследований в области прогнозирования достаточно много (типа таких), но в них не хватает практической применимости. Свою аналитику по ИБ у нас пишут очень немногие заказчики, а в продукты прогностические модели внедряют единицы вендоров (по пальцам одной руки скорее всего можно посчитать).Попробую не уходить в глубокую математику, а посмотреть с более практической точки зрения.
Кстати, хотите проверить инновационность своих вендоров и их продуктов? Спросите у производителя, есть ли у него подразделение по перспективным технологиям, например, ИИ или блокчейну или квантовым технологиям (зависит от профиля компании).
Даже в, казалось бы достаточно консервативной сфере, такой как криптография, используются прогностические модели. Например, в свое время в интересах Академии криптографии проводилась НИР «Исследование возможности применения риск-ориентированного подхода для оценки качестве преобразований, реализуемых криптографическими алгоритмами».
Однако, надо признать, что все-таки прогнозирование в ИБ пока не так активно развито, так как сегодня фокус больше смещен в сторону описательной и диагностической аналитики. Тот же ML преимущественно для этого используется.
Один из примеров, с которым я столкнулся еще несколько лет назад, связан с обнаружением DGA-доменов. На иллюстрации показан пример, когда был обнаружен вредоносный домен, который прекрасно заблокировали и на этом можно было завершить историю, если бы не было принято провести дополнительное расследование. Заблокированный домен был «приписан» к двум IP-адресам, на одном их которых было также зарегистрировано более 1000 DGA-доменов, пока неучаствовавших ни в одной атаке и ждущих своего часа. Можно спрогнозировать, что в будущем они могут быть использованы. Упс, вот у нас первый пример прогноза.
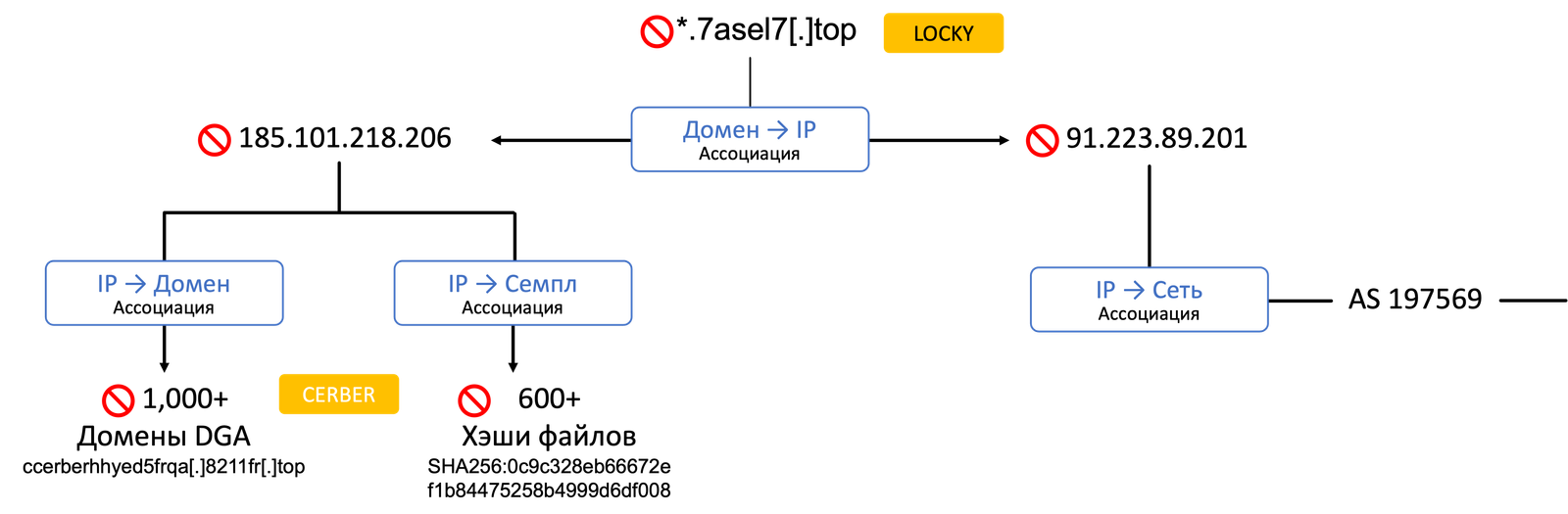
Проводя расследование дальше и сопоставив один из IP-адресов с автономной сетью (AS), удалось выявить, что в этой AS также были зарегистрирован целый ряд DGA-доменов, которые попали на VirusTotal только спустя несколько дней. Достаточно простой, но при этом очевидный пример прогнозирования.
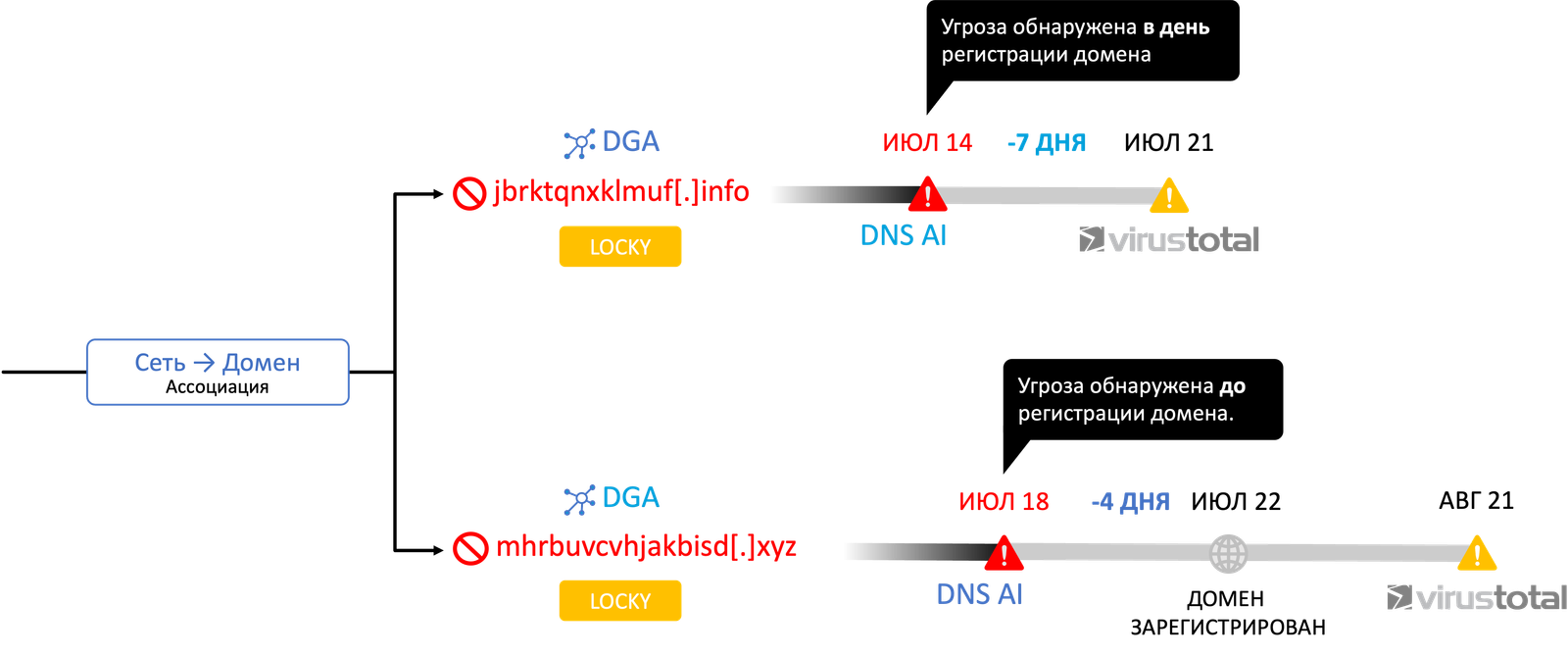
Описанный метод базируется на машинном обучении и он не предлагает вам никаких вероятностей «сбычи мечт», то есть указания, будет ли на вас атака с указанных доменов или нет. По сути он подсказывает вам одно из направлений, по которому вас могут атаковать и уже за вами решение — блокировать эти домены заранее или нет (или автоматизировать эту задачу за счет использования DNS Firewall, он же SASE, который будет на автомате блокировать доступ к DGA-доменам; тот же эффект может быть достигнут и на стороне заказчика за счет применения NGFW или NTA).
Еще один вариант прогнозирования — применение методов OSINT или Threat Intelligence, когда вы следите за тем, что присходит в вашей стране, регионе, отрасли или именно у вас. Он предполагает, что вы сами или кто-то по вашему заданию осуществляет мониторинг угроз, изучение даркнета и бюллетеней TI, в поисках ответа на вопрос: «Попал ли я в прицел киберпреступников или могу ли я в него попасть?». На первую часть вопроса ответ дает мониторинг даркнета, который может быть частью услуги Digital Risk Protection (я про них уже
писал ) или самостоятельной задачей. Если мы видим где-то на теневых форумах интерес к определенной компании, то у меня сразу стрелка виртуального барометра уходит в зону «буря». Если OSINT показывает, что мое имя нигде не встречается, но идет рост атак на отрасль, в которой я работаю, то стрелку барометра мы сдвигаем влево, в зону «ливня». Ну а если атаки идут веерно против целой страны, без фокусировки на конкретных жертвах, то барометр у нас будет показывать «дождь» (не страшно, но базовые меры защиты предпринять стоит).Знаете ли вы, что до сих пор никто так и не научился предсказывать погоду (в отличие от климата) и максимальный (и то, не всегда точный) горизонт прогнозирования — 3 недели?!
2+ года назад атаки на российские организации имели под собой вполне понятную финансовую мотивацию, но с тех пор ситуация сильно изменилась. Сегодня нас атакуют по причине страны происхождения, а не наличия денежных средств или иных каких-либо выгод для нападающих.
Да, есть и те, кто продолжает искать вполне определенные организации для проведения атак, имеющих военные или иные схожие последствия.
Но в целом, уже тот факт, что какая-то организация зарегистрирована в России, дает повод считать ее законной мишенью для определенной категории хакеров. А значит у нас всегда будет «дождь» на нашем барометре и надо быть готовым, что он превратится в «ливень» или даже «бурю». И тут достаточно базовой оценки, чтобы понять, насколько легко нас будет атаковать или нет. Ведь киберпреступники тоже люди и тоже не любят серьезно упарываться в своей деятельности, если она не несет для них никакой пользы. Увидев, что у вас «открыты ворота» в корпоративную сеть, вас сломают «просто так, до кучи». Если же у вас явных пробелов хотя бы на периметре нет, то и тратить на вас время, если нет явного заказа, никто не будет. Поэтому можно построить простенькую модель, которая может базироваться либо на бинарной логике (ответы «да/нет»), либо на трех- или пятибалльной шкале, в которой будут отмечены актуальные для вас темы ИБ — наличие непатченных уязвимостей на периметре, наличие открытых портов, наличие в анамнезе фишинговых кампаний против вас и т.п. А дальше вы собираете все вместе и выносите кумулятивный показатель на какой-нибудь дашборд руководства или свой собственный. И там, в форме светофора, будет видно, насколько вы защищены или насколько вероятно, что вас могут сломать. Именно «могут», так как «будут» зависит уже от мотивации нарушителя, но для России я бы принял этот показатель сейчас за 99%.
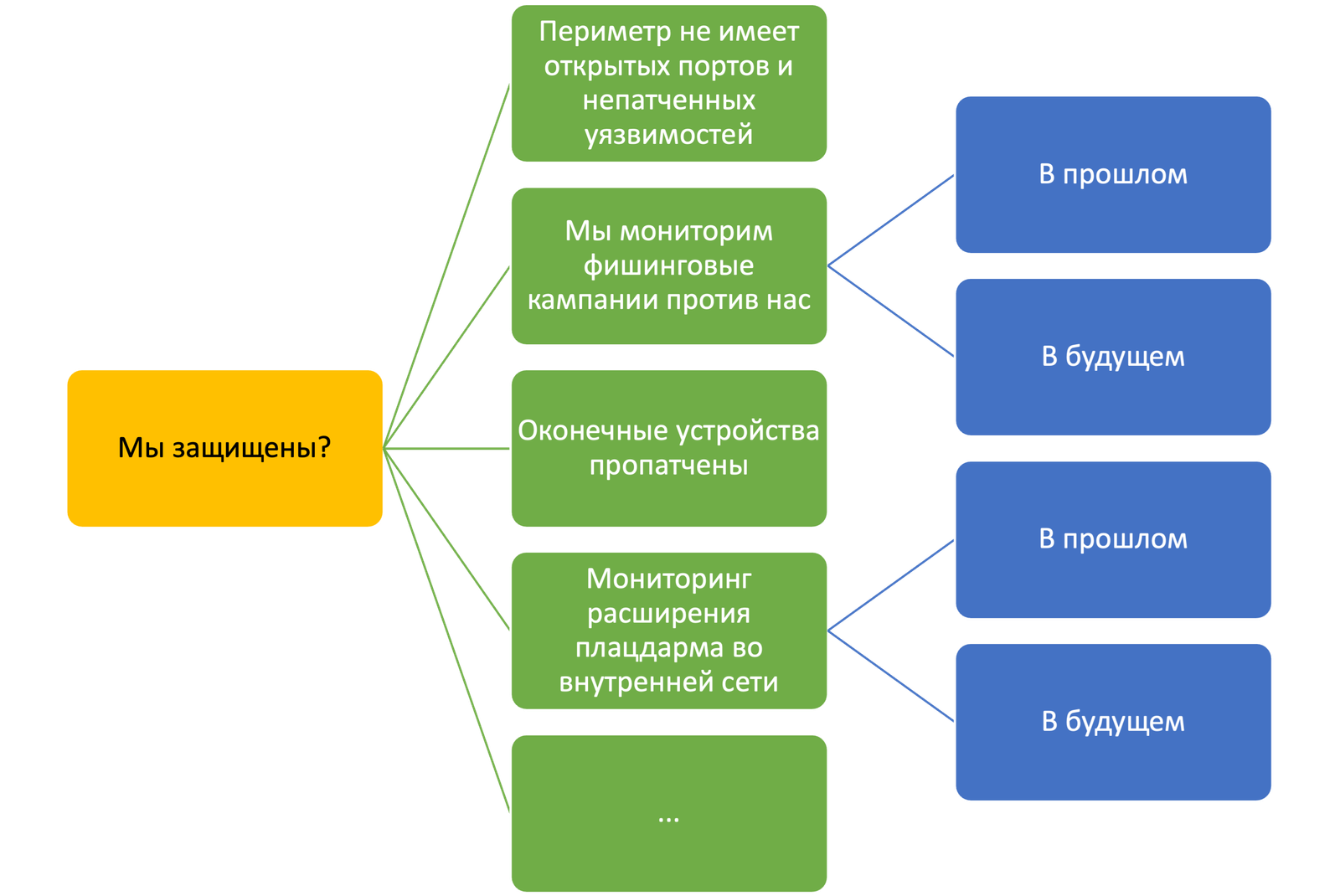
Список конкретных вопросов, которые укладываются в «мы защищены», в каждой компании будет свой. Можно взять за основу идеи, которые положены в основу опросника на портале «Резбез».
Еще один инструмент для прогнозирования в ИБ — это временные ряды. Хотя обычно их используют для выявления уже случившихся аномалий в решениях класса UEBA (User Entity Behaviour Analytics) или BAD (Behavioural Anomaly Detection). В этом случае они позволяют вам выделять признаки, классифицировать, кластеризовать, искать шаблоны и аномалии. Но с точки зрения прогнозирования нас будет интересовать немного другое — либо так называемые тренды, то есть тенденция к долгосрочному увеличению или уменьшению значений временного ряда, либо точечная аномалия, которая является предвестником чего-то нехорошего. В последнем случае выявить точечную аномалию проще простого — в них поведение процесса серьезно отличается от всех остальных точек. Но вот понять причину этой аномалии непросто и целиком автоматизировать эту задачу невозможно (по крайней мере пока). Даже в задаче обнаружения атак это непросто, так как изначально данные не размечены должным образом и неизвестно, что является аномалией, а что нет. В случае с прогнозированием ситуация еще хуже.
Я, когда готовил эту заметку, решил почитать, что пишут в отечественных диссертациях на тему прогнозирования кибератак. Взял работу на соискание степени кандидата технических наук «Разработка методов прогнозирования негативных событий при компьютерной обработке данных» (2021). Первую главу, в которой упоминались тест Дики-Фуллера, модель Бокса-Дженкинса, эффект Слуцкого-Юла, экспоненциальное сглаживание, сети Петри-Маркова, я быстро пролистал, так как там вообще ни слова не было про кибербезопасность — просто переписанный учебник по матстату и терверу. Вторая глава изобиловала суммами Эрдеша-Реньи, m-мерными Евклидовами пространствами, матожиданиями, коммутативными несимметричными n-базисами, формулами Стирлинга, неравенствами Чебышева. Закончилась глава выводом, что время эффективной обработки данных прямо пропорционально надежности парольной системы (количеству вариантов пароля) и обратно пропорционально наносимому ущербу (первый вывод очевиден даже школьнику и не требовал применения коммутативного несимметричного n-базиса, а второй неочевиден даже с применением оного).

Третья глава оказалась ближе к теме и в ней попробовали прогнозировать различные негативные события, связанные с атаками, хищением денежных средства, использованием уязвимостей и т.п. Но самое интересное было в четвертой главе, так как именно в ней автор попробовала предложить свою прогнозную аппроксимирующую функцию на базе метода Лагранжа построения интерполяционного многочлена, метода наименьших квадратов и метода Берга. В итоге был выбран метод наименьших квадратов. К слову, этот метод был придуман еще в 1795-м году Гауссом и мне кажется, что он не очень подходит для столь динамичной среды как кибербезопасность; есть методы и с лучшими статистическими свойствами. Но не мне указывать кандидатам наук и принимающим их работы докторам.
Если вы устали читать про многочлены, то подождите, я уже подхожу к финалу.
В пятой главе я все-таки наткнулся на исследование точности разработанного механизма. Автор, ссылаясь на то, что данных по ИБ у нее нет, а разработанный метод универсален, решила апробировать его на предсказании курсов мировых валют, драгметаллов, объема памяти и быстродействия ЭВМ. Заморачиваться с поиском курсов валют и золота я не стал, а вот по второй паре показателей данные у меня были. Автор спрогнозировала, что в 2024-м году производительность ЭВМ будет на уровне 1834 петафлопса (1221 петафлопс в 2021-м году), а емкость жестких дисков в 2024-м году будет равна 45,3 ПБ (2,27 ПБ в 2021-м).
Что же у нас в реальности? Самый мощный суперкомпьютер сейчас — это Frontier от HPE с заявленной производительностью в 1102 петафлопс (хотя в пике он показал 1680 петафлопс). Все остальные суперкомпьютеры (Aurora, Eagle, Фугаку, LUMI и т.п.) в два раза слабее по своим показателям (на уровне 2016 года по прогнозной модели автора рассматриваемой диссертации). С жесткими дисками ситуация еще хуже. В феврале Seagate анонсировала продажи жестких дисков Exos Mozaic 3+ на… «жалких» 30 ТБ. Сегодня это мировой рекорд. Пластины в этом диске по 3 ТБ, но производитель вскоре обещает увеличить их до 5 ТБ, что даст максимальную емкость в 50 ТБ. Согласно диссертационному прогнозу такой объем должен был быть достигнут в 2017-м году, а в 2024-м он должен был составлять 45,4 ПБ (пета, мать его, байт).
Большинство просмотренных мной диссертаций и публикаций по теме прогнозирования кибератак обладают одной объединяющей их чертой — много сложных и непонятных формул и полное отсутствие проверки предложенных моделей на практике; причем именно в ИБ. Иногда, правда, авторы пишут, что у них полное совпадение с опубликованной статистикой по атакам, но когда начинаешь копаться, то оказывается, что эта статистика прошлых периодов и авторы, похоже, просто подгоняли свои модели под результат.
Последним (в данной заметке) инструментом прогнозирования я бы хотел назвать казуальные модели, а точнее идею, заложенную в них — причинно-следственные диаграммы. Применительно к ИБ речь идет о цепочках атак, но используемых при их прогнозировании, а не обнаружении. Обычно ведь как — вы собираете данные от средств защиты (сенсоров) и собираете их в цепочки, отслеживая перемещение хакера по корпоративной или ведомственной сети.
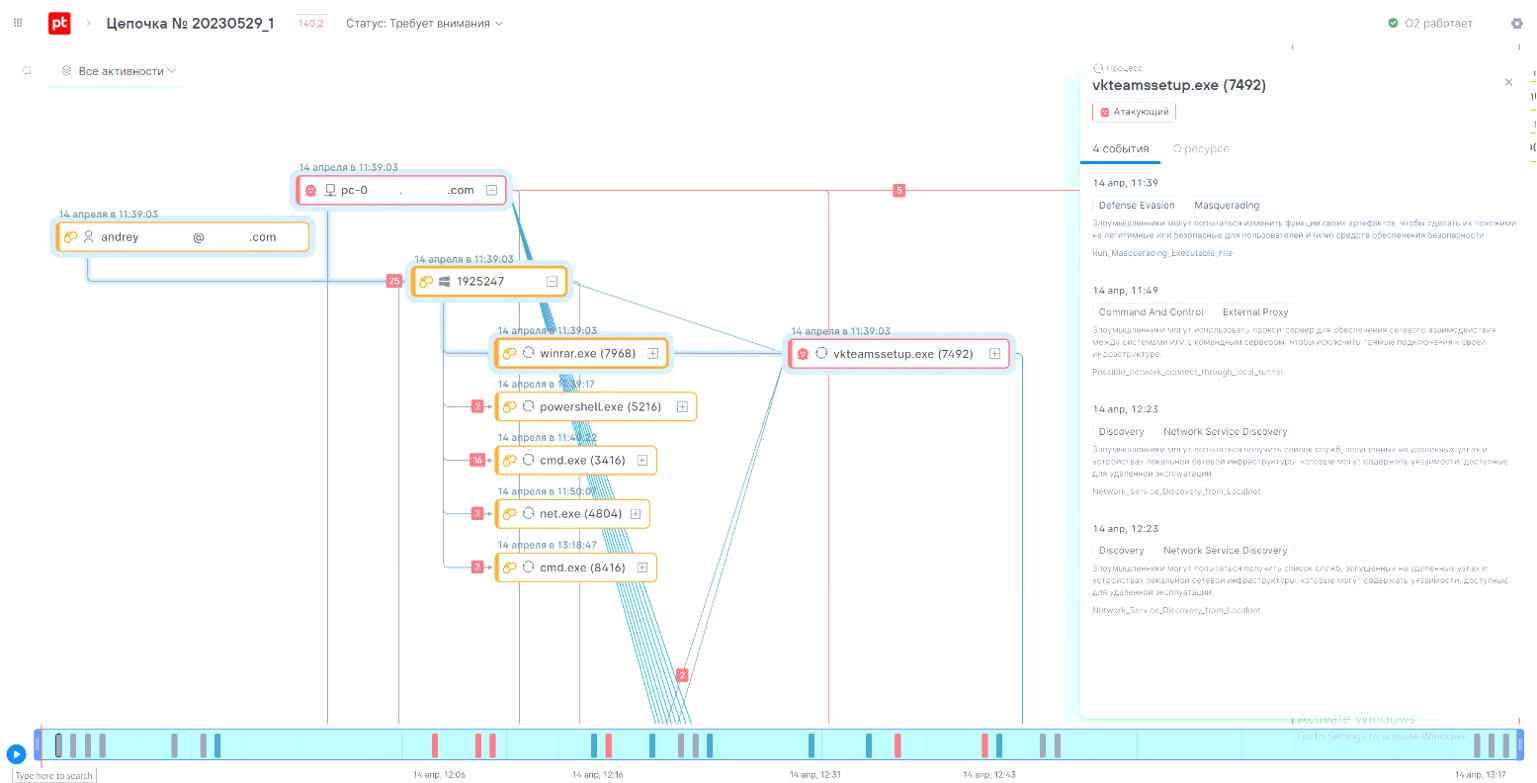
Но ведь можно сработать и на опережение! Если вы знаете про все возможные (или, как минимум, самые распространенные) цепочки, то предсказание возможных путей движения хакера существенно упрощается.
Да, я знаю про возможное число комбинаций и приводить мне в пример шахматы не стоит!
В реальной жизни, первичных векторов атак у вас не так уж и много, как и вторых/третьих шагов. Их число конечно и обычно легко описываемо. Важно своевременно фиксировать нужные события и делать на их основе прогнозы.
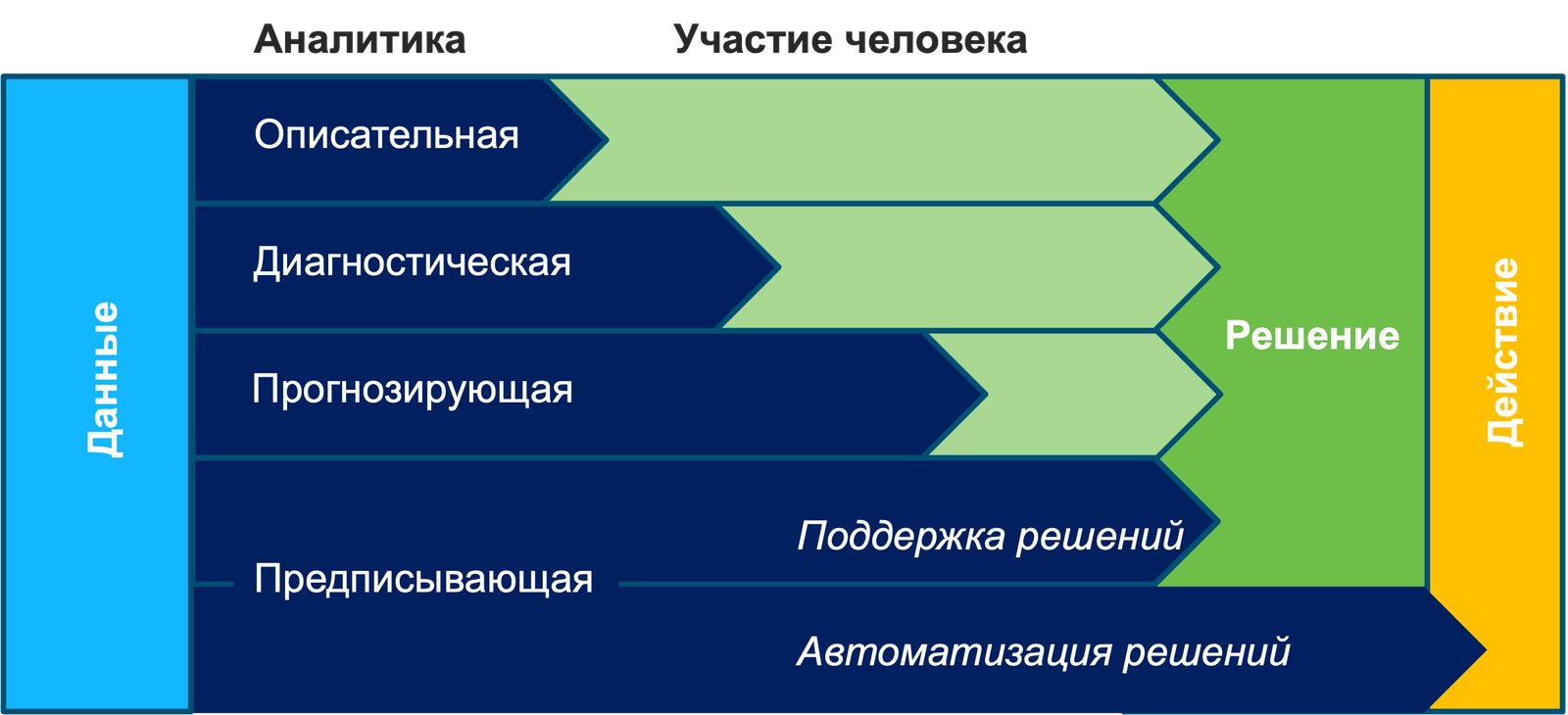
Можно заметить, что описываемые методы позволяют строить прогнозы на разных временных горизонтах — как правило, краткосрочные и среднесрочные. Долгосрочные и дальнесрочные прогнозы сродни предсказанию погоды — невозможно оценить детали для конкретной организации, но можно показать общую картину (то есть речь идет о климате, а не погоде). Есть методы простые, а есть требующие достаточно сложной математики, большого объема данных и экспериментов для проверки корректности выбранных моделей на практике. При этом, подозреваю, что для разных типов прогнозируемых событий ИБ и модели будут разные, а не одна универсальная. Все будет очень сильно зависеть от задач. Где-то это вообще будет просто сценарный анализ, как делает тот же Gartner, когда опирается на мнение своих аналитиков и дает предсказание, которое должно сбыться с точностью в 80% к определенному году (часто не сбывается, кстати). Есть еще форсайты, то есть экспертная оценка направлений развития, которые могут оказать воздействие на определенную область (могут и не оказать). Это может выглядеть примерно вот так:
В целом, тема прогнозирования низкоуровневых (типа расширение плацдарма или подбор пароля), среднеуровнеых (типа шифровальщиков) или высокоуровневых (типа кражи денежных средств или реализации иных недопустимых событий) кибератак очень интересна и еще ждет своих исследователей. Главное, не отрываться от реальности и приземлять все эти «интерполяционные многочлены Лагранжа» на конкретные ситуации, дающие простой, понятный и измеримый эффект.
Заметка
Можно ли предсказывать кибератаки? была впервые опубликована на Бизнес без опасности .
