По оценкам Microsoft инцидент с CrowdStrike затронул 8,5 миллионов компьютеров! А теперь обо всем по порядку!
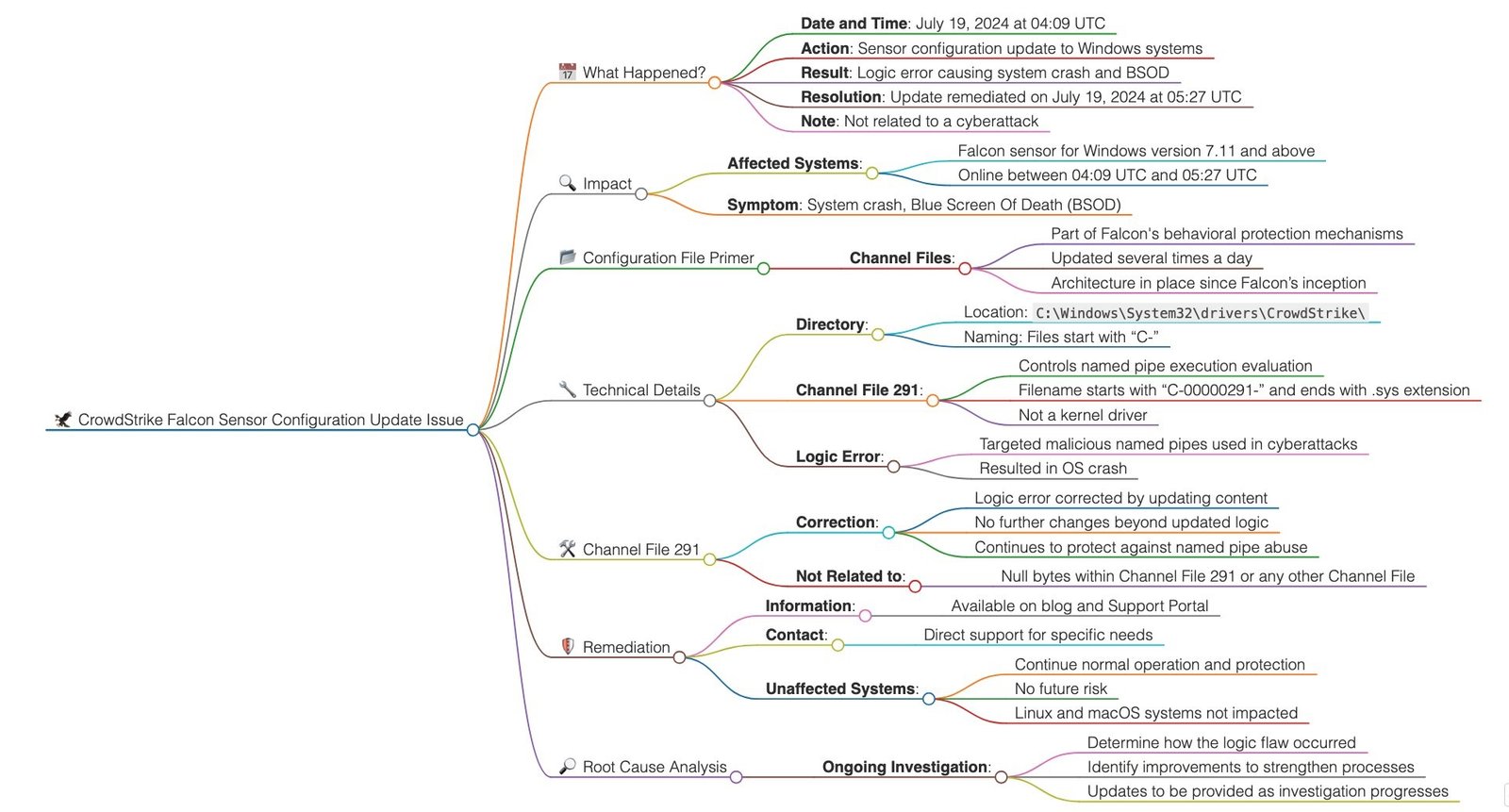
Что случилось?
Очередное обновление CrowdStrike Falcon вызвало на компьютерах под управлением Windows (Linux и macOS не страдают от этого) логическую ошибку, которая привела к сбою системы и появлению синего экрана (BSOD).
Обновление не затрагивало ядро ОС Windows, что требует согласования с Microsoft. Оно также не относилось к ПО Falcon, чтобы пропускать его через обычную в таком роде процедуру тестирования обновления. Речь шла об обычном конфигурационном файле (да, с расширением .sys), в котором содержались поведенческие сигнатуры для борьбы с новыми способами C2-коммуникаций в рамках свежих кибератак. Посколько речь идет об обычном контенте обнаружения, который прилетает в случае с CrowdStrike, по несколько раз в день на защищаемые компьютеры, то никто не пропускал его через процедуру Detection Engineering и не ждал подвоха.
Да и вообще, признайтесь, кто из вас проверяет прилетающий контент обнаружения в любом из ваших средств защиты — антивирусу, EDR, IDS, WAF, NGFW, SIEM, NTA, XDR?.. Ведь никто же!
Обновление самого ПО (а не контента обнаружения) у CrowdStrike осуществляет раз в две недели и у пользователя есть варианты выбора, ставить их автоматически или с задержкой. Сама поддержка CrowdStrike рекомендует ставить релизы по схеме N-1 для всех критичных сервисов, то есть спустя две недели после выхода очередного обновления, когда все, кто мог, уже столкнутся со всеми возможными проблемами. Для особо критичных сервисов у CrowdStrike есть схема обновления N-2, то есть проходит месяц, прежде чем новая версия поставится на ПК (N — это новый релиз ПО).
Такова архитектура CrowdStrike Falcon, как и почти любого аналогичного средства защиты, неважно, управляемого из облака или работающего целиком в варианте on-prem. Сам защитный агент тесно интегрирован с операционной системой, что и привело к синему экрану смерти во время обработки нового файла.
В середине 90-х годов, этак в 95-96, была история с антивирусом Dr.Web, которую я наблюдал лично. Тогда еще не было Интернета в России и почти весь софт скачивался через различные BBS, а обновления к нему распространялись через сеть FIDOnet. Так вот в один из дней, в одной из антивирусных эх (прообраз Telegram-каналов) было размещено очередное обновление антивируса, которое, при установке и запуске обновленного Dr.Web форматировало жесткий диск. Позже выяснилось, что у российского антивируса в базе сигнатур мог быть и исполняемый код, а не просто сигнатуры/хэши вредоносных программ.
Причем тут Microsoft Azure?
Когда только началась вся шумиха, а фактов еще не было, в Интернет циркулировало две истории — про проблемы с компьютерами на базе Windows, ставшие жертвами обновления CrowdStrike, и про выход из строя облака Microsoft Azure. Потом уже выяснилось, что обновление CrowdStrike накрыло и инфраструктуру Azure, а с ней и некоторые сервисы Microsoft 365, например, Office, OneDrive или Teams. Затронуло даже инфраструктуру Microsoft Defender.
На вопрос «Почему Microsoft для защиты не использует собственный Defender?» отвечу. Так часто бывает и причин тому может быть несколько — от неуверенности в своих продуктах до признания качества других, от наличия договоренностей между компаниями «ты — мне, я — тебе» до исторической наследственности.
Кстати, в отдельных материалах говорилось, от имени Microsoft, что эти инциденты между собой не связаны.
Кто пострадал?
Во-первых, пострадала репутация CrowdStrike, а вместе с ней и ее финансовое положение — акции компании упали более чем на 20% или на 16 миллиардов долларов (и это вряд ли конец, так как еще планируются иски со стороны клиентов). По словам самой CrowdStrike ее решениями пользуется половина компаний рейтинга Fortune 500; а всего у нее 29000 клиентов, бОльшая часть которых используется CrowdStrike на платформе Windows. По данным Microsoft пострадало 8,5 миллионов или менее 1% всех Windows компьютеров.

Помимо авиакомпаний среди пострадавших:
- финансовые организации, например, Visa, Zelle, TD Bank, JPMorgan Chase Bank, Bank of America и Лондонская биржа,
- телекомпании, например, Sky News, TF1 и Canal+,
- операторы наружной рекламы,
- порты в Роттердаме и Гданьске,
- железнодорожные компании, например, Govia Thameslink Railway,
- сети питания, например, McDonalds, Starbucks,
- логистические компании, например, UPS или FedEx,
- медицинские учреждения,
- соцсети, например, Instagram,
- облачные сервисы, например, Azure,
- ретейл, например, сети Waitrose и Morrisons,
- онлайн-площадки типа Ticketmaster, eBay или BetMGM,
- экстренные службы, например, 911 в США,
- операторы связи и т.п.

Некоторые эксперты шутят, что пострадавшие компании внезапно прошли штабные киберучения для проверки своих навыков и разработанных на такие случаи процедур! А у вас такие процедуры разработаны?
Хорошо, что сбой произошел не во время Олимпийских игр!..
Когда все восстановится?
Хрен знает. CrowdStrike отправила свежее обновление (вроде работающее) по своим клиентам, но не уверена в том, что процесс восстановления будет быстрым и автоматическим. Текущий сценарий подразумевает, что каждый компьютер должен быть перезагружен в безопасном режиме, затем должен быть удален определенный файл и потом компьютер опять должен быть перезагружен. Все это в ручном режиме, что, конечно же, займет время и немало в крупных организациях. Проблемы несомненно будут там, где компании полагались на удаленное администрирование своих сетей, — придется тратиться на командировки ИТ-специалистов или отправлять загрузочные флешки (Microsoft обновил процедуру создания таких USB) в удаленные офисы или удаленным сотрудникам, писать подробные инструкции «для чайников» и все время сидеть на видеоконференцсвязи для удаленного контроля восстановления систем.

В отдельных случаях можно попробовать сделать все через сетевую загрузку или специализированное ПО типа SCCM, групповые политики Windows, IBM BigFix, Ivanti Endpoint Manager и т.п.
Судя по описанию процедуры ручного восстановлена на сайте CrowdStrike, жопа для многих предстоит знатная, так как если жесткие диски компьютеров шифровались с помощью BitLocker, то для получения доступа к нужной директории в безопасном режиме нужны ключи BitLocker, что, как оказалось, для многих представляет проблему.
По предварительным оценкам, за несколько дней большинство компаний должно восстановиться, но кому-то понадобятся недели на это. Тогда-то и можно будет оценить весь ущерб от инцидента.
Каков ущерб?
Больше всех пострадали авиакомпании. В пятницу в США было отменено 5100 рейсов, в субботу, только на восточном побережье США еще 2000 рейсов. Это 3,5% от всех американских рейсов. Только в Австралии было отменено больше (в Великобритании, Франции и Бразилии — 1%, в Канаде — около 2%). Всего, по данным FlightAware было отменено 30000 рейсов. Сколько это в деньгах? Так как речь идет не о погодных условиях как причины отмены (а это сокращает стоимость отмены в 2-3 раза), то стоимость отмены одного рейса следующая:
- региональные рейсы — $2750
- узкофюзеляжные самолеты — $15650
- малые широкофюзеляжные самолеты — $29690
- большие широкофюзеляжные самолеты — $42890.
Перемножаем и получаем около около 1 миллиарда долларов только на отмене рейсов за два дня (пятница и суббота) и это еще не посчитаны затраты страховок за отмененные рейсы, питание в аэропорту, нагрузка на аэропорты, выплаты персоналу за внеурочную работу и т.п. А ведь не летали не только пассажирские, но и грузовые рейсы, а это уже компенсации за срыв поставок, испорченный скоропортящийся товар и т.п. Первые оценки первых 20 часов после начала сбоя говорят о 24 миллиардах долларов; отдельные эксперты говорят о триллионах долларов!
Во многих медицинских организациях были отменены операции и процедуры. ТВ и рекламщики не крутили рекламу, ретейл не мог размещать заказы, экстренные службы не выезжали по вызовам, что могло приводить к преступлениям и смертям людей, банки нарушали временные параметры для финансовых транзакций…
Надо учитывать, что сбой имел и каскадный эффект, как это часто и бывает с критическими инфраструктурами. Например, у вас не работает банк, а значит и всего его клиенты, пользующиеся бухгалтерскими услугами, оказываемыми банком. У вас не работает логистическая компания, а значит она не может доставлять товары клиентам, которые вынуждены снижать производство или срывать поставку заказов и т.п.

А что в России?
Ничего не произошло. Пострадало несколько представительств глобальных компаний (например, Procter & Gamble и L’Oreal), да граждане, улетающие в другие страны, не смогли пересесть на стыковочные рейсы или улететь в закрытые аэропорты. Но в целом, нас этот инцидент не затронул, так как у нас в стране вообще не используется продукция CrowdStrike. И дело не в 250-м Указе Президента, и не в уходе американских компаний из России. Просто CrowdStrike у нас никогда ничего и не продавал. У них не было своего офиса в России, да и партнеры особо это решение не продавали. В итоге у нас даже в доСВОшные времена продукции этой компании особо не было.
Импортозамещение рулит?
Да ни хрена. Я вообще не понимаю, кому пришло в голову взять на флаг эту историю с импортозамещением в данном инциденте и говорить о прозорливости нашего президента правительства, которое своими решениями о переходе на отечественный софт спасло нас от глобальной проблемы. Во-первых, CrowdStrike у нас в стране никогда и не было, а во-вторых, та же самая проблема могла произойти с любым ПО, не взирая на страну его происхождения. Это вообще никак несвязанные между собой вещи.
Можно ли было это предотвратить?
На стороне заказчика нет! Когда меня спрашивали, а вот если бы у заказчиков стоял <имярек> EDR, то можно было бы избежать коллапса? А вот если поставить NGFW или NDR, то предотвратит ли это от повторения? Увы, инцидент не связан с кибератаками или эксплуатацией уязвимостей, а значит замена одного продукта на другой или выстраивание эшелонированной обороны вокруг ПК с EDR ни к чему не приведет. Это проблемы в разных плоскостях.
Можно, конечно, отменить обновление контента обнаружения, но тогда какой смысл в системе защиты, если она не обладает своевременным знанием об угрозах?
Почему это произошло?
А вот это пока не очень понятно. CrowdStrike пишет, что произошло, но не почему. Почему они не проверили обновление перед его выкатыванием в прод? Я могу понять, когда заказчик не тестирует прилетающий ему контент обнаружения, но вендор, его производящий? Что-то с
detection engineering у CrowdStrike сбойнуло. Почему Windows уходит в синеву, получив этот файл, тоже не очень понятно.Хочу напомнить, что сбои такого масштаба бывали и раньше. Обновление Mcafee положило несколько десятков тысяч компов в 2010-м году. Сбой Cloudflare в 2019, в Akamai в 2004, DDoS-атака на Dyn DNS в 2016, сбой в CenturyLink в 2020, отказ в Optus в 2023 и т.п.

А может это хакеры?
Нет, это не хакеры. Хотя такая причина, для тех кто помнит кейс с SolarWinds, не выглядит невозможной. Но если бы это были плохие парни, то они бы старались оставаться незамеченными и их вредоносные импланты были бы направлены на кражу информации, а не на выведение систем из строя. Да и сам CrowdStrike это не подтверждает.

Кстати, пока идет восстановление и ИБшники бегают в мыле, то кто мониторит атаки? Не пропускают ли они что-то?
Как хакеры отреагировали на инцидент?
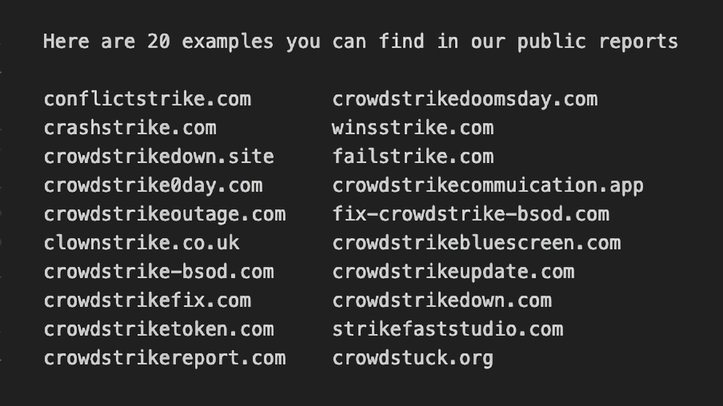
Положительно. Любая глобальная новость, вызывающая страх и неопределенность, сразу берется хакерами на флаг, что они и не преминули сделать и в данной ситуации. Быстро были зарегистрированы фишинговые домены:
- crowdstrikebluescreen[.]com
- crowdstrikefix[.]com
- clownstrike[.]com (этот явно ради шутки)
- crowdstrikebluescreen[.]com
- crowdstrike0day[.]com
- crowdstrike-bsod[.]com
- crowdstrikedoomsday[.]com
- crowdstrikedoomsday[.]com
- crowdstrikefix[.]com
- crowdstrikedown[.]site
- crowdstriketoken[.]com
- crowdstrikeclaim[.]com
- crowdstrikedown[.]site
- crowdstrikeoutage[.]info
- crowdstrikeupdate[.]com
- crowdstrokeme[.]me
- fix-crowdstrike-apocalypse[.]com
- fix-crowdstrike-bsod[.]com
- microsoftcrowdstrike[.]com
- crowdfalcon-immed-update[.]com
а на них были ссылки в фишинговых письмах, озаглавленных «CrowdStrike Support» или «CrowdStrike Security». Сама CrowdStrike зафиксировала распространение вредоносного кода в файле crowdstrike-hotfix.zip нацеленного на пользователей из Латинской Америки. Об этом же пишет и Any.run у себя в X (Twitter), приводя примеры и вредоносов, скрывающихся под обновления CrowdStrike, и фишинговые домены:
Что стоит помнить о средствах защиты?
Стоит помнить, что средства защиты — это такое же ПО, как и любое другое (часто поставляемое в парадигме AS IS). Но заказчики часто смотрят на такие средства как на нечто безопасное и защищенное по умолчанию, что не так. У защитного ПО тоже бывают уязвимости, которые тоже могут быть использованы злоумышленниками. Они могут компрометировать сервера управления средствами защиты и через них получать контроль над всей инфраструктурой заказчика. Они могут даже использовать уязвимости в средствах защиты для распространения вредоносного кода.
В марте 2004-го года на свет родился червь Witty, который стал первым вредоносом, нацеленным на продукты ИБ, — он атаковал решения компании Internet Security Systems, которую я выводил на российский рынок в конце 90-х годов. Witty инфицировал и уничтожал компьютеры (стирая случайные сектора на жестком диске), на которых были запущены RealSecure Server Sensor, RealSecure Network, RealSecure Desktop или BlackICE. Всего 700 строк кода и 12 тысяч компьютеров по всему миру были уничтожены за 45 минут.
Гендиректор Internet Security Systems нанял ряд внешних экспертов, которые провели анализ вредоносного кода и причин, позволивших ему так быстро распространяться, чтобы устранить выявленные уязвимости в своих продуктах и чтобы история не повторилась. Респект!
Так что не надо наделять средства защиты свойством неуязвимости и исключать из их общих политик работы с ПО, включая тестирование обновление, защиту, контроль целостности и т.п. Это может дорого обойтись. Тем более, что в том же CrowdStrike уже находились уязвимости, позволяющие отключать это средство защиты.
Как отреагировали регуляторы?
Оперативно. Американская CISA выпустила соответствующий бюллетень и продолжает его постоянно обновлять по мере появления новой информации. Также поступили регуляторы Великобритании, Австралии и Канады.
Из наших регуляторов отреагировал только Роскомнадзор, сообщив, что к нему никто из российских компаний по данному поводу не обращался. Остальные регуляторы по понятной причине ничего не написали — решений CrowdStrike в России же нет. Но интересно, как быстро бы они среагировали, если бы такое произошло с каким-нибудь отечественным вендором EDR?..
Почему к Роскомнадзору по данному поводу вообще кто-то должен был обращаться, Роскомнадзор не сообщает!
Как сделать так, чтобы это не повторилось (у вендора)?
Эксперты пишут, что CrowdStrike нужно пригласить внешнего и независимого аудитора, который провел бы анализ произошедшего и опубликовал бы его результаты (как это сделала ISS 20 лет назад). Ровно то, что делают взломанные компании, приглашающие ту же CrowdStrike для независимого аудита и обеспечения чистоты собранных доказательств. Другие какие-то советы сейчас давать бессмысленно, так как мы не знаем истинную причину произошедшего. Менять архитектуру продукта? Менять процессы detection engineering? Внедрять новые уровни QA? Все это можно и нужно делать и оно, в том или ином виде, было у CrowdStrike. Но что-то не сработало…
Как сделать так, чтобы это не повторилось (у заказчиков)?
Не ставить обновления в пятницу? Во-первых, это зависит от того, как у вас вообще выстроена работа ИТ и ИБ. Если вы работаете в режиме 24х7, то день недели для установки любых обновлений вообще не важен. Во-вторых, речь в инциденте идет об обновлении контента обнаружения, а не самого ПО. Поэтому такие обновления прилетают постоянно, по несколько раз на дню, и их никто не проверяет, просто автоматически подгружая в систему. Поэтому этот классический мем про установки патчей в проде в пятницу вечером выкиньте в топку.
Проверять прилетающий контент обнаружения? Ну такое себе. Да, Detection Engineering штука хорошая… когда понимаешь. Я еще могу понять, как проверить правила на YARA, Sigma, Snort, иные IOCи. Но как это сделать для поведенческих сигнатур? А для новых ML-моделей? Почти нереально, особенно для проприетарного ПО с закрытыми форматами данных.
Не ставить сразу обновления? Ну для обновлений ПО схема и так работает, а вот для контента обнаружения этот совет не работает. Он же должен ставиться оперативно, а выдерживание его в течение недели двух и проверка в тестовом окружении?.. Не работает.
Но если уж говорить о процедуре, то я бы сделал следующее (и скорее всего многое из этого у вас уже сделано):
- Во время аналогичного инцидента
- Эскалируйте ситуацию на антикризисную команду и держите их в курсе.
- Классифицируйте пострадавшие активы с точки зрения их важности для бизнеса.
- Вовлеките ИТ-персонал для помощи сотрудникам, но без предоставления последним средств восстановления или повышения их привилегий для самостоятельного восстановления систем.
- Не принимайте спонтанных решений об отказе от CrowdStrike. Лучше делать это после всестороннего разбора ситуации, общения с производителем и следования процедуре управления рисками от поставщиков.
- После полного восстановления
- Оцените «аутсайдеров», компьютеры, которые пострадали и не были восстановлены.
- Проведите анализ аномалий и сигналов тревоги от средств защиты во время восстановления для оценки возможности пропуска кибератак.
- Проведите оценку воздействия инцидента на бизнес и не допускайте спонтанных и эмоциональных решений руководства, которые могут повлиять на ИБ компании.
- Подготовьте презентацию для руководства с описанием текущего статуса, а также изменений, которые позволят не повториться данной ситуации в будущем (хотя, повторюсь, в случае с контентом обнаружения это сложно предотвращаемая история).
- Проверьте, что ваши сотрудники не впали в уныние, вышли из стрессовой ситуации, не выгорели. Если наблюдаются признаки этого, то стоит дать им отдохнуть. Пусть «Happy Friday» будет действительно «Happy»!
- В долгосрочной перспективе
- Пересмотрите свои процессы с учетом извлеченных уроков и внесите в них изменения для широкомасштабных инцидентов (больше запросов на поддержку, больше людей для поддержки, больше стресса…).
- Пересмотрите процедуры обновления ПО, например, раскатывать не все сразу, а поэтапно, сначала на менее критичные системы, потом на более и т.д., вплоть до целевых и ключевых систем.
- Проверьте работоспособность тестовом окружении, эмулирующем вашу инфраструктуру (то, что работает у других, может не работать на вашей связке ПО или давать совершенно непредсказуемые эффекты).
- Проверьте работоспособности процедуры OOB-коммуникаций (out-of-band) со своим сотрудниками на такой случай. А то как им сообщить о проблеме, если ни почта, ни корпоративный мессенджер не работают?
- Проверьте план обеспечения непрерывности бизнеса и проведите по итогам инцидента учения со всеми ключевыми сотрудниками, вовлеченными в кризисные коммуникации и в обеспечение киберустойчивости.
И не забудьте про резервное копирование!
Что будет?
Пока сложно оценивать все последствия произошедшего. CrowdStrike явно столкнется с исками от пострадавших клиентов, которые могут поставить компанию на грань выживания. То, что они потеряли 20% своей капитализации еще ни о чем не говорит, если у них есть cash в закромах. Но крупные иски могут прорядить и их и тогда придется как-то выкручиваться.
Не исключаю разбирательств на уровне государства, как это было с Microsoft во время недавних инцидентов с утечками ключей и данных из облачных сред гиганта из Редмонда. Тогда даже был особый правительственный отчет Cyber Safety Review Board, который ставил перед ИТ-компанией неприятные вопросы. Джордж Курц, гендиректор CrowdStrike, даже высказывался про Microsoft по этому поводу. Теперь ему предстоить побыть в шкуре Сатьи Наделлы, CEO Microsoft.
Медицинские организации, которые также столкнулись с выходом из строя своих систем и вынуждены были либо приостановить работу, либо перейти на аналоговые системы и «бумажную» работу, требуют от своих государств усиления требований к безопасности, что может и произойти.
Кто-то предсказывает, что в отрасли ИБ может начаться кризис недоверия, что заставит их еще больше тратиться на рекламу в ущерб повышению качества и защищенности своих продуктов. Точно можно сказать, что внедрение решения класса xDR в АСУ ТП если не прекратится, то замедлится. Лучшей демонстрации эффекта от внедрения в критические инфраструктуры не придумаешь 🙁

Но при этом, бизнес должен задуматься о том, насколько прочно он подсел на ИТ-иглу и как важно оценивать влияние ИТ/ИБ на бизнес. Сейчас, когда ИБшников будут звать на ковер к руководству, стоит тщательно подготовить свое выступление и, возможно, выйти после него с победой.
Чернуха про руководство CrowdStrike
А вы знали, что в в 2010 году у антивируса MacAfee случился косяк с Windows XP, который положил половину западного Интернета.
Это обошлось компании так дорого, что они вынуждены были продаться компании Intel. Человек, который тогда был техническим директором (CTO) MacAfee, сейчас является … генеральным директором (CEO) Crowdstrike (George Kurtz) и антивируса Falcon, который положил вчера аэропорты 🙂
Этот текст, который сейчас перепечатывают отдельные каналы, взят с Пикабу (надежный источник информации), который, в свою очередь, ссылается на еще один популярнейший источник проверенных новостей по ИБ — Hindustan Times. Кто я такой, чтобы спорить с индийским СМИ, но хочу обратить внимание, что достаточно просто посмотреть финансовые показатели McAfee за 2010 год, чтобы понять, что инцидент произошедший в апреле 2010-го года вряд ли мог повлиять на решение Intel купить McAfee, анонсированное 3-мя месяцами позже. Во-первых, Due Dilligence в рамках M&A-сделки такого актива за такой срок провести затруднительно, а во-вторых, акции компании за 2010 год только росли (на 14,15%), что вряд ли говорит о плохом финансовом положении.
Ну а теперь, после долгого чтения, можно и сделать перерыв 🙂

Заметка
Анализ инцидента с CrowdStrike была впервые опубликована на Бизнес без опасности .
