
Охота за битами 2
Прошло уже немало времени с момента рождения первой эксплуатации переполнений буфера. Но с тех пор многое изменилось. Методика, используемая сейчас – это уже нечто больше чем просто шеллкод. Это искусство, требующее от автора профессиональных знаний в программировании, оптимизации и принципов работы эксплуатируемой ОС. Иначе, как можно было бы создавать шеллкоды в таких форматах как UTF-8, UTF-16, base64, Alpha-Numeric…
Прошло уже немало времени с момента рождения первой эксплуатации переполнений буфера. Но с тех пор многое изменилось. Методика, используемая сейчас – это уже нечто больше чем просто шеллкод. Это искусство, требующее от автора профессиональных знаний в программировании, оптимизации и принципов работы эксплуатируемой ОС. Иначе, как можно было бы создавать шеллкоды в таких форматах как UTF-8, UTF-16, base64, Alpha-Numeric…
Еже был сильный противник,
но Петруччо был еще сильнее...
противник чем Еже...
Мысла Владислав // DgtlScrm // digitalscream@real.xakep.ru
Так сложилось, что практически все уязвимости переполнения буфера были успешно эксплуатированы. Информационная индустрия, дарила хакерами множество, на первый взгляд, не решаемых задач. Уже далеко те времена, когда единожды написанный код, использовался для множества других эксплуатаций. Нет, это не значит что раньше, специфических уязвимостей не было вообще. Сложившаяся ситуация, на рынке безопасности программного обеспечения, скорее напоминала хранилище с обогащенным ураном. Вспомнить хотя бы ранние версии Windows, в которых ошибки никто не искал, просто вопрос заключался лишь в том, чтобы как-то избавляться от них.
Сейчас все состоит по-другому. Эксплоит стоит неплохие деньги, успешно внедряются технологии защиты от ошибок в работе с памятью. Более того, стандарты передачи данных ограничивают диапазоны, доступных к использованию команд и операндов. Новые условия, стали диктовать свои правила, так рождались эксплоиты специализированные под UTF-8, UTF-16, base64 и Alpha-Numeric форматы. И это не полный список, а лишь одни из самых распространенных представителей.
Не так давно, мне пришлось столкнуться с одной из таких проблем – приложение, обрабатывающее исключительно строковые представления чисел... только строки хранящие цифры от 0 до 9. Данное приложение было уязвимо, но ограничения на входные данные делали эксплуатацию невозможной. По крайней мере, так мне показалось на первый взгляд…
Формат строкового представления целочисленных данных
Строковое представление целого числа – это обычная строковая переменная (с завершающим нулем), состоящая исключительно из арабских цифр. Каждый разряд такого числа в строковой форме представлен в памяти одним байтом.
Таким образом, диапазон допустимых к использованию символов внутри строки ограничен байт-кодами ‘0’-‘9’:
Символ | Байт | Биты |
0 | 0x30 | 0011 0000 |
1 | 0x31 | 0011 0001 |
2 | 0x32 | 0011 0010 |
3 | 0x33 | 0011 0011 |
4 | 0x34 | 0011 0100 |
5 | 0x35 | 0011 0101 |
6 | 0x36 | 0011 0110 |
7 | 0x37 | 0011 0111 |
8 | 0x38 | 0011 1000 |
9 | 0x39 | 0011 0001 |
Например, число “31337” в памяти будет представлено как последовательность байт “\x33\x31\x33\x33\x37”.
Совместимость с форматом
При эксплуатировании, уязвимостей в обработке, строк хранящих целочисленные данные, возникает множество проблем. Первой, из которых бросается в глаза – это ограниченность команд и операндов, доступных к использованию в шеллкоде. Можно использовать всего 10 байт, десять инструкций из нескольких сотен, существующих на данный момент.
Доступные регистры
Еще одна проблема использования инструкций – это ограниченность доступных операндов-регистров. Если быть точным, то проблемы возникают при формировании байта ModR/M (используется, доступными командами XOR и CMP) или SIM.
Каждый из регистров представлен в виде 3-х битного числа. Разрядность числа определяется последним битом инструкции. В то время, как выбор операндов-регистров/памяти, ограничен значением ModR/M.
Рассмотрев принцип формирования операндов на битовом уровне, легко увидеть, какие именно из их них доступны, а какие нет.
Доступные значения
Не стоит удивляться такому названию подраздела. Как ни странно, есть ограничения и в возможностях манипулирования значениями регистров и даже памяти.
Поскольку шеллкод должен состоять только из символов-цифр, то числа, используемые в нем, ограничены маской 0x3?3?3?3?. Если применить операцию XOR, можно также добиться значений 0x0?0?0?0?. Так, например, можно получить 0x00000101, 0x31323334, 0x00000000 или 0x30303030.
Но не это самая большая проблема. Хуже всего, если на момент переполнения не известны значения регистров. Ведь если задуматься, то нет ни одной доступной операции для явного изменения значений регистров. Не доступны инструкции MOV, POP и т.д. Нет ничего, что позволило бы установить регистр в конкретное значение. Более того, может случиться так, что те регистры, значения которых определены, в момент переполнения не могут быть использованы, потому что являются недоступными или их применение оказывается не возможным в определенных условиях. Так, например eBP в данном контексте – недоступный регистр.
Забегая наперед, скажу, что лучше всего, чтобы было известно значение регистра eAX. Это идеальный вариант. А, учитывая то что перед выходом из функции, на перезаписанный EIP, в EAX помещается результат работы, то он может быть одним и тем же на момент переполнения. Следовательно, не зависеть от каких-либо иных факторов.
Доступные команды
Из существующих инструкций, доступны к использованию только 10 (0x30-0x39). Ознакомившись со стандартом Intel-Architecture можно составить их скромный список:
Символ | Байт | Операция |
0 | 0x30 | XOR Eb, Gb |
1 | 0x31 | XOR Ev, Gv |
2 | 0x32 | XOR Gb, Eb |
3 | 0x33 | XOR Gb, Ev |
4 | 0x34 | XOR AL, Ib |
5 | 0x35 | XOR eAX, Iv |
6 | 0x36 | SEG = SS |
7 | 0x37 | AAA |
8 | 0x38 | CMP Eb, Gb |
9 | 0x39 | CMP Ev, Gv |
Таким образом, больше половины всех инструкций это XOR (Logical Exclusive OR). Имеются также функциональные команды AAA (ASCII Adjust after Addition) и CMP (Compare Two Operands).
Инструкция XOR – логическое исключающее ИЛИ. Она может быть использована для изменения значений регистров и памяти.
Префикс SS (0x36) указывает на то, что следующая за ней операция использует адреса лежащие в сегментном регистре. Ее использование имеет смысл в 16-битном режиме, в 32-битном она не имеет никакой функциональности и просто игнорируется.
Инструкция AAA – форматирование после сложения. Применяется для корректирования двоично-кодированных цифр(BSD Integer) после их сложения. В данной ситуации она может быть полезна для зануления старших 4-х бит регистра AL, инкрементирования регистра AH и замены младших 4-х бит AL в случае если их значения превышают диапазон 0-9.
Инструкция CMP – сравнивает два операнда, результат сравнения можно определить, проверив соответствующие флаги. Но, воспользоваться ими не удастся, потому как недоступны условные операции. Тем не менее, правильно подобранное сравнение может повлиять на результат работы операции AAA.
Модифицирование регистров
Учитывая, что значения большинства регистров на момент переполнения неизвестны, их значения придется изменять. Но для того чтобы это сделать, мы будем вынуждены столкнуться с множеством проблем. В зависимости от надобности тех или иных регистров, они могут решаться по-разному. Впрочем, некоторые проблемы являются не решаемыми. В таких ситуациях, необходимо искать другие пути или модифицировать алгоритм работы шеллкода.
Учитывая ограничения, доступных к использованию байт, придется прибегнуть к изощренным техникам написания кода. Которые, в целом представляют собой интеллектуальные методы, идея которых, может быть не совсем понятой. Но я могу вас уверить в том, что такое впечатление возникает только в первый раз. По мере практики, логика операций становится понятной на уровне подсознания, также как примитивное умножение из средней школы. Хотя, это касается не всех применяемых технологий, но такая ситуация имеет место быть. Поэтому я постараюсь начать с более простых вещей, постепенно усложняя воспроизводимую ситуацию.
Поскольку, среди всех доступных операций и операндов, нет конструкций позволяющих, установить новое значение регистра независимо от прошлых данных, к каждому регистру я постараюсь частично описать, возможные альтернативы.
Следует также учитывать, что согласно специфике задачи, некоторые регистры окажутся недоступными, например eBP. Но зато, большинство из них, может быть использовано при косвенной адресации.
Регистр eAX
Из всех регистров, eAX по праву можно считать одним из ключевых (по крайней мере, в представленной реализации). Именно он позволяет наиболее гибко и оптимально воспользоваться всеми доступными десятью байтами. Как разработчики эксплоита, в первую очередь, вы должны ориентироваться именно на него.
Для того чтобы понять весь спектр операций, предоставляемых этим регистром, предлагаю вам внимательно взглянуть на следующий список инструкций, в которых он используется:
| модификация значения регистра | ||
| 8 бит | 32 бита | |
Grp1 | xor al, 0x30 | xor eax, 0x3?3?3?3? |
| aaa | ||
Grp2 | xor byte ptr [eax], dh xor byte ptr [eax], bh | xor dword ptr [eax], edi xor dword ptr [eax], esi |
| xor dh, byte ptr [eax] xor bh, byte ptr [eax] | xor esi, dword ptr [eax] xor edi, dword ptr [eax] | |
| xor dh, byte ptr [eax + esi] xor dh, byte ptr [eax + edi] | xor dword ptr [eax + esi], esi xor dword ptr [eax + edi], esi | |
| xor byte ptr [eax + esi], dh xor byte ptr [eax + edi], dh | xor esi, dword ptr [eax + esi] xor esi, dword ptr [eax + edi] | |
Таким образом, eAX можно свободно модифицировать, независимо от значений других регистров, см. Grp1. Также, его можно использовать в качестве операнда-источника, при операциях с косвенной адресацией, см. Grp2. Кроме всего этого, он применим как для работы с 8 битными операндами-приемниками, так и с 32 битными.
В большинстве случаев, я не буду разделять понятия регистров eAX и AL (а также некоторых других), поскольку это один и тот же регистр с разным количеством разрядов, конкретизируя только специфические случаи.
Способ №1
eAX – единственный регистр, к которому применима операция xor, без использования значений хранящихся в памяти. Это значит, что можно воспользоваться инструкциями < xor eAX, 0x3?3?3?3? > и
Для реализации этой методики необходимо выполнение условия, относительно формата, предыдущего значения регистра eAX:
0xYXYXYXYX |
В данном случае Y(старшие 4 бита в байте) это 0x0 либо 0x3, X – значение в диапазоне младших 4 бит, в диапазоне от 0x0 до 0xF. Такое ограничение накладывает формат шеллкода, поскольку для модификации можно использовать операцию < xor eAX, 0x3?3?3?3? >.
Примеры, использования этого метода для изменения регистра eAX:
| |
| |
|
В случаях, когда Y равен 0x0, для обнуления необходимо дважды выполнить операцию xor. После первого Y превращается в 0x3, а на второй раз опять зануляется.
Более того, если X в каждом месте может быть разным, то все значения Y должны совпадать (кроме последнего вхождения, которое может быть модифицировано как AL):
| |
|
Закон двузначности xor. Выбор старших разрядов | ||
Хороший воин знает, что в бою он может использовать только байты из диапазона {0x30,…,0x39} и, применяя операцию xor к регистру eAX, который равен 0x0?0?0?0?, результатом всегда будет число 0x3?3?3?3?. Повторное же применение этой операции, установит eAX в исходный 0x0?0?0?0?. Если же регистр eAX в начале его пути был 0x3?3?3?3?, второй результат становиться первым, первый вторым, а третий первыми, так было всегда. | ||
Если вы не забыли, в своем шеллкоде, вы не можете использовать байты, в которых младшие разряды больше девяти. Но это не значит, что нет возможности установить их в {0xA, 0xB, 0xC, 0xD, 0xE, 0xF}, обнулить или изменить на любое другое значение. Но это легко проделать, применяя повторную операцию xor:
| |
|
Таким образом, зная старые значения eAX, можно как угодно изменить значения младших разрядов любого байта входящего в него.
Закон многозначности xor. Выбор младших разрядов | ||
Хороший воин никогда не забудет, что имеет полный контроль над значениями младших разрядов регистра eAX. Ибо доступны ему обнуления и изменения. Но лишь умный воин сможет умело воспользоваться этими знаниями, на пути к победе. Превращая, младшие 4 разряда, в нужные ему значения. Осознав это, он раздвинет границы формата, и сможет заносить в регистры не только числа {0x30,…,0x39}, а и {0x3A,…,0x3F}. | ||
Ранее упоминалось, что значением Y должны быть 0x0 или 0x3. На самом деле, это необходимо лишь в том случае, если его требуется обнулить. В общем случае, можно манипулировать любым значением Y, даже пренебрегая условие их одинаковости, таким образом, старшие разряды, имея значения {Y1,Y2,Y3,Y4}, после < xor eAX, 0x3?3?3?3? > превратятся в {Y1^3,Y2^3,Y3^3,Y4^3}.
Закон однозначности xor. | ||
Хороший воин всегда помнит “законы выбора xor” применяя его для победы над регистром eAX. Зная его значение, воин легко модифицирует младшие 4 бита, всех 4-х байт входящих в регистр, превращая их в {0x0,…,0xF}. И при любом значении старших бит, он может изменить их, применив xor на 0x3?3?3?3?. А может и не изменять, это его право. Просто, если старое значение было Y, то новое всегда будет {Y, Y^3}. И лишь значение AL, может изменяться независимо, потому что он стар и мудр. И если остальные байты равны Y, AL свободен принять Y^3, ибо они ему никто и имя ему AL, и он свободен. Глупец тот, кто считает, что старшие разряды всех байт eAX одинаковы. Когда нет согласия между ними, eAX может быть сформирован из 4-х, разных байт {0xA?,0xB?,0xC?,0xD?}. Сила xor может изменит каждого и любого из них, устанавливая 0xA? в 0xA?^3, а 0xB? в 0xB?^3, и наоборот. Влияние xor сильно и безгранично в пределах 32-х бит, и влияет он на всех сразу, наивно пытаясь вернуть согласие между ними. А AL всегда свободен, поэтому он может защититься от силы xor. Но еще больший глупец тот, кто считает проблемой, разность старших разрядов. Мудрый человек знает, что удачное значение eAX может состоять из любых байт, а одинаковые их значения могут принести беду. Потому что плохой воин не победит даже обнуленный регистр, а хороший сделает все для достижения цели. Осознав все это, воин начинает новый путь. Теперь, он уже не просто купец истины, ведущий караваны сомнений. Он обладает знаниями, и разум его чист и однозначен. Так же как и однозначно значение регистра eAX после xor. Это и есть первая победа, победа однозначности, над двузначностью и многозначностью двух половин. Но война еще длится… | ||
Способ №2
Этот способ основан на прошлом методе, но на этот раз будет задействована операция AAA. Он более специфичен, но ознакомится с ним, все же следует, поскольку при непосредственной разработке возникают задачи, которые решаются с использованием именно этой техники.
Настоящий воин, внимательно выслушает слова мудреца, даже если их смысл ему не понятен. Ибо слово его, есть ключ к пониманию других речей. Также как и хорошее вино, ценность которого зависит от выдержки. | ||
Изучив работу инструкции aaa, можно прийти к мнению, что она предоставляет достаточно большие возможности. Хоть кроме нее, нет доступа к использованию других операций над двоично-десятичными числами. Более того, не доступна операция ADD, после которой и предполагается использовать AAA. Но кроме этого, также известно, что aaa обрабатывает и изменяет значение регистра AX, а это самое основное.
Согласно документации результаты работы AAA, полностью зависят от значения AX и флагов AF и CF. В некоторых случаях этим можно воспользоваться, но сначала необходимо разобраться, каким образом можно повлиять на ее работу.
Значение AX можно косвенно изменять, применяя операцию xor к регистрам eAX и AL. Это уже хорошо, поскольку есть непосредственный доступ к изменению обрабатываемых инструкцией данных.
Для изменения флагов, следовало бы воспользоваться, доступной инструкцией CMP. Сравнивая два операнда, можно с легкостью выставлять флаги в требуемые значения. Но этот способ имеет больше недостатков, чем преимуществ. Дело в том, что доступны только два вида сравнений, каждый из которых требует адрес в качестве одного из операндов. Вполне вероятно, что в момент переполнения не окажется доступного регистра с таким значением, а инструкция aaa может понадобиться, в первых операциях шеллкода. В такой ситуации, можно воспользоваться регистром eSP, он в любом случае указывает на доступную память. Если быть точнее, то он ссылается на шеллкод и что хорошо, шеллкод может быть спроектирован таким образом, чтобы по этому адресу находилось заранее известное значение. Но, к сожалению, из всех доступных операндов, eSP используется только в суме с eSI:
1 | cmp dword ptr [esp+esi],esi |
2 | cmp byte ptr [esp+esi],dh |
Следовательно, значение eSI должно быть заранее известным и достаточно маленьким, чтобы их сума не указывала на неизвестные или недоступные участки памяти. Более того, если эта сума будет указывать на шеллкод, который состоит из байт 0x3?, наименьшим значением, которое будет там хранится, это 0x30303030. Учитывая то, что значение eSI, в принципе, должно быть меньше, первый вариант сравнения установит флаги AF и CF в ноль (от этого пользы мало). Следовательно, требуется привязаться к другим участкам памяти или использовать второе сравнение. В таком случае вам или дополнительно потребуется определенное значение в DH или подобрать подходящее смещение от eSP. В таком случае, используя большое количество операций, будет меньше затрат и больше надежности, если отказаться от привязки к указателю на стек и использовать другие регистры. Хотя, не могу поспорить с тем, что очень часто получается осуществить нужное сравнение без особых затрат, но такие возможности в основном возникают уже после исполнения шеллкодом определенного количества инструкций.
Исходя из всего выше сказанного, для модификации флагов, по возможности, следует использовать альтернативные варианты. Одним из них может быть совместное использование операций XOR и AAA, впрочем, это единственные команды доступные кроме сравнения.
Предлагаемый процесс – банальное использование XOR, для установки младших разрядов AL в число, которое будет больше 0x9. Как результат, последующее исполнение AAA, инкрементирует младшие разряды AL, обнулит старшие, а также инкрементирует AH.
| |
| |
|
Многие из читателей, могут прийти к мнению, что таких же результатов можно достичь, применяя исключительно XOR. Могу вас уверить, что это не так. Применяя вышеописанную технологию, становятся возможными решения очень большого спектра задач.
Используя последовательно XOR и AAA, можно устанавливать значение старших разрядов AL в ноль. Но это скорее не возможность, а особенность использования инструкции aaa.
|
Если флаг AF равен единице, последовательные вызовы aaa позволяют изменять младшие разряды AL с шагом в шесть. Таким образом, результатом в AL, будет последовательность: 0x00+k, 0x06+k, 0x0C+k, 0x02+k, 0x08+k, 0x0E+k, 0x04+k, 0x0A+k. Где k – может изменяться в диапазоне [0x00,…,0x05]. В общем случае алгоритм можно представить следующим образом:
|
Объясняется эта особенность очень просто. Если операция AAA модифицировала AH, флаг AF устанавливается ею в единицу. Следовательно, последующее вызовы инструкции AAA, снова изменят значение AX, но при этом AF не сбрасывается. Флаг будет установлен в ноль, только после исполнения таких операций как XOR, CMP или XOR в комбинации с AAA.
Значит если необходимо воссоздать последовательность: 0x01, 0x07, 0x0D, 0x03, 0x09, 0x0F, 0x05, 0x0B, можно воспользоваться этим алгоритмом:
|
Изменяя коэффициент, изменяется стартовое значение, то соответственно изменяются и элементы замкнутой последовательности. Исходя из этого, общего случая, пример можно адаптировать для последовательного инкрементирования AL:
|
Эта техника своеобразная 3-х байтная замена пары-XOR, которая занимает 2x2=4 байт:
|
| ||
|
| ||
При этом всем, необходимо помнить, что с изменением AL, при установленном флаге AF или если значение AL не соответствует двоично-десятичному числу, регистр AH изменяется вместе с ним. Поэтому, очень важно, вовремя сбросить значения младших разрядов AH, чтобы избежать процесса модификации его старших разрядов. Максимальное “безопасное значение” младших AH будет 0xF. Если при достижении этого числа их не очистить, а дальше продолжать вызовы aaa, исправить ситуацию будет затруднительно:
|
| ||
|
| ||
В то же время, при определенных условиях, такая особенность инкрементировании AH, может оказаться полезной. Так, если значения старших разрядов AH неприемлемы, используя N операций aaa, значение AH увеличится на N. Такой вариант хорош, при небольшом N, потому что не сильно увеличится размер шеллкода. Отличной практикой можно считать, комбинирование последовательностей AAA и операции XOR. В этом легко убедиться, на простом примере: изменить значение eAX с 0x31313131 на 0x0000FF00:
|
Понимание приходит со временем, также как маленький ручей постепенно превращается в реку, сила которой способна разрушить берега или размыть скалы. Терпеливый слушатель, как странник, покидающий свой дом для встречи с самим собой на краю сознания. Он разрывает цепь причин и следствий… теперь он сам причина, а следствие это и есть причина его путешествия. Ибо путешествие это он, цель которого познание непостижимого. Но лишь немногие воины готовы пройти этот путь до конца. | ||
Способ №3
При написании шеллкода, вполне вероятно столкновение с ситуацией, когда нельзя однозначно сказать, какое значение в данный момент храниться в eAX. Если это действительно так, то мне придется вас огорчить, этот регистр, для вас недоступен.
Дело в том, что в шеллкоде нельзя воспользоваться инструкциями:
|
Все доступные операции, производят модификацию уже хранящихся в регистре значений. Кроме того, в связи с налагаемыми ограничениями, к значению eAX нельзя применить операции, использующие косвенную адресацию. В случае же если отклонение от определенного значения не очень велико, можно пойти на уловки, применив AAA. Эта процедура позволит, в дальнейшем изменять регистр AL, но только и всего.
Но все же есть несколько случаев, когда можно корректно обработать хранящееся в eAX значение. Если разница возможных значений, лавирует в пределах регистра AL, поочередное применение к нему операций AAA и XOR. Позволяет, достичь однозначных значений, независимо от того, какое число там хранится в данный момент. Заранее хочу предупредить, что чем больший диапазон значений может принимать AL, тем больше операций придется проделать с ним, для достижения позитивных результатов. Это, прежде всего, математика и комбинаторика. В какой-то мере можно сказать, что мы применяем одну и туже булевскую операцию, потому как логика всего на протяжении всего процесса, является неизменной.
Не углубляясь в подробности, скажу что, немного посидев над решением таких задач, вычисления уже производятся на интуитивном уровне. Хотя, лично я, на данный момент, так и не могу в словесной форме выразить логику происходящего процесса. Так или иначе, все сводится к тому, чтобы постепенно объединять результаты каждого из возможных вариантов. Постепенно образовывая группы из 2-х элементов, потом 4-х, 5-ти и т.д.
номер | операции | eax = 0x00000000 | eax = 0x00000034 |
1 | xor al,0x39 | eax = 0x00000039 | eax = 0x0000000d |
2 | aaa | eax = 0x00000009 | eax = 0x00000103 |
3 | xor al,0x37 | eax = 0x0000003e | eax = 0x00000134 |
4 | aaa | eax = 0x00000104 | eax = 0x00000104 |
Думаю, логика происходящего понятна. Но это саамы простой из случаев, когда нужно объединить два разных значения. В общем случае, добавляя возможные варианты, сложность процесс тоже растет.
номер | операции | ax = 0x0000 | ax = 0x0072 | ax = 0x0074 | ax = 0x00C6 |
1 | aaa | ax = 0x0000 | ax = 0x0002 | ax = 0x0004 | ax = 0x0006 |
2 | xor al,0x3f | ax = 0x003f | ax = 0x003d | ax = 0x003b | ax = 0x0039 |
3 | aaa | ax = 0x0105 | ax = 0x0103 | ax = 0x0101 | ax = 0x0009 |
4 | xor al,0x37 | ax = 0x0132 | ax = 0x0134 | ax = 0x0136 | ax = 0x003e |
5 | aaa | ax = 0x0102 | ax = 0x0104 | ax = 0x0106 | ax = 0x0104 |
6 | xor al,0x38 | ax = 0x013a | ax = 0x013c | ax = 0x013e | ax = 0x013c |
7 | aaa | ax = 0x0200 | ax = 0x0202 | ax = 0x0204 | ax = 0x0202 |
8 | xor al,0x38 | ax = 0x0238 | ax = 0x023a | ax = 0x023c | ax = 0x023a |
9 | aaa | ax = 0x0208 | ax = 0x0300 | ax = 0x0302 | ax = 0x0300 |
10 | xor al,0x32 | ax = 0x023a | ax = 0x0332 | ax = 0x0330 | ax = 0x0332 |
11 | aaa | ax = 0x0300 | ax = 0x0302 | ax = 0x0300 | ax = 0x0302 |
12 | xor al,0x39 | ax = 0x0339 | ax = 0x033b | ax = 0x0339 | ax = 0x033b |
13 | aaa | ax = 0x0309 | ax = 0x0401 | ax = 0x0309 | ax = 0x0401 |
14 | aaa | ax = 0x0309 | ax = 0x0507 | ax = 0x0309 | ax = 0x0507 |
15 | xor al,0x37 | ax = 0x033e | ax = 0x0530 | ax = 0x033e | ax = 0x0530 |
16 | aaa | ax = 0x0404 | ax = 0x0500 | ax = 0x0404 | ax = 0x0500 |
17 | aaa | ax = 0x050a | ax = 0x0500 | ax = 0x050a | ax = 0x0500 |
18 | aaa | ax = 0x0600 | ax = 0x0500 | ax = 0x0600 | ax = 0x0500 |
В результате, al равен нулю, но в ah образовалась разница в единицу, от этого можно избавиться, применяя все высшее описанные технологии. Дополнительно следует обратить внимание на шаги 12-17. Это косвенное инкрементирование, используемое для замены значений 0x00 и 0x02 на следующие за ними элементы последовательности.
Собственно говоря, это и все, по поводу непосредственной модификации регистров. Все остальные допустимые конструкции используют косвенную адресацию. Более того, изменение eAX – единственный процесс, не требующий ее и ко всему прочему, она к нему неприменима!
Жизнь воина коротка, но память о нем живет вечно. Настоящий воин не должен чувствовать страх перед неизвестностью, ибо то, что тайно, есть важным. И сила его есть не в знании, а в понимании. И слепцу можно указать верный путь, но увидит ли он его? | ||
Регистры eSI, eDI и косвенная адресация
Говоря о косвенной адресации, имеется в виду, использование в инструкциях операндов, указывающих на некую область в памяти. Таким образом, в обработке участвуют не сами значения операндов, а данные что находятся по тому адресу, на который указывает конструкция:
1 | cmp dword ptr [esp],esi |
2 | cmp byte ptr [esp+esi],dh |
3 | cmp byte ptr [esp+esi*2+4],dh |
Поскольку, только изменение регистра eAX, может быть исполнено без применения косвенной адресации, все остальные регистры могут изменяться, только в зависимости от значений хранящихся в памяти. Кроме этого, к ним операция AAA применяться не может и единственный способ их модификации – это XOR относительно памяти.
Существует ограниченный диапазон [0x30,0x39], допустимых к использованию байт, для формирования ModR/M. Исходя из этого, можно выделить 10 вариаций ModR/M:
Символ | Байт | Биты | Операнды ModR/M | |||
Mod | Register | R/M | Register | R/M | ||
0 | 0x30 | 00 | 11 0 | 000 | ESI | [EAX] |
1 | 0x31 | 00 | 11 0 | 001 | ESI | [ECX] |
2 | 0x32 | 00 | 11 0 | 010 | ESI | [EDX] |
3 | 0x33 | 00 | 11 0 | 011 | ESI | [EBX] |
4 | 0x34 | 00 | 11 0 | 100 | ESI | SIB |
5 | 0x35 | 00 | 11 0 | 101 | ESI | Displace32 |
6 | 0x36 | 00 | 11 0 | 110 | ESI | [ESI] |
7 | 0x37 | 00 | 11 0 | 111 | ESI | [EDI] |
8 | 0x38 | 00 | 11 1 | 000 | EDI | [EAX] |
9 | 0x39 | 00 | 11 1 | 001 | EDI | [ECX] |
Секция Register формируется битами 3-5. Поскольку, допустимые символы имеют маску 0x3X, где X – в пределах от нуля до девяти, можно говорить о том, что существует возможность изменения 3-го бита ModR/M. Причем, если он равен нулю, секция R/M действительно может принимать любые значения. Но если этот бит, установлен в единицу, значение R/M ограничено битами 000 и 001. Остальные биты 4 и 5, всегда равны единицам, а биты секции Mod всегда имеют нулевые значения.
Как видно, инструкции, использующие ModR/M, могут работать только со значениями регистров ESI и EDI. Все остальные, доступные регистры, интерпретируются как адреса указывающие на значения в памяти (косвенная адресация). Среди всех значений ModR/M, нужно дополнительно выделить два – 4 и 5.
Displace32 – значит, что операндом будет явно указанный адрес.
SIB (Scale Index Base) – это значение секции R/M, оно позволяет, более гибко использовать косвенную адресацию. Если используется SIB, его нужно дополнительно описать еще одним байтом. Принцип формирования SIB, совпадает с ModR/M. Поэтому кроме таблицы, дополнительные объяснения понадобится, не должны.
Символ | Байт | Биты | Операнд SIB | |||
ss | Index | Register | Register | Index | ||
0 | 0x30 | 00 | 11 0 | 000 | [EAX] | ESI |
1 | 0x31 | 00 | 11 0 | 001 | [ECX] | ESI |
2 | 0x32 | 00 | 11 0 | 010 | [EDX] | ESI |
3 | 0x33 | 00 | 11 0 | 011 | [EBX] | ESI |
4 | 0x34 | 00 | 11 0 | 100 | [ESP] | ESI |
5 | 0x35 | 00 | 11 0 | 101 | Displace32 | ESI |
6 | 0x36 | 00 | 11 0 | 110 | [ESI] | ESI |
7 | 0x37 | 00 | 11 0 | 111 | [EDI] | ESI |
8 | 0x38 | 00 | 11 1 | 000 | [EAX] | EDI |
9 | 0x39 | 00 | 11 1 | 001 | [ECX] | EDI |
Обратите внимание, что если SIB равен 0x35, полученный операнд примет значение [ESI+Displace32], потому что секция Mod из ModR/M в данной ситуации всегда равна нулю.
Исходя из всего этого, можно говорить о том, что в шеллкоде можно использовать косвенную адресацию в сочетании в SIB и ModR/M байтами. Для примера возьмем инструкцию xor и поэкспериментируем с доступными возможностями.
| |
|
Это лишь два примера из множества возможных. Более детально эта тема будет рассмотрена во второй половине статьи. На этом этапе, необходимо запомнить что, контролируя eAX и владея информацией о значениях в памяти, на момент переполнения, можно добиваться требуемых значений доступных регистров.
Написание шеллкода
Из всего диапазона байт, в шеллкоде можно использовать только числа [0x30-0x39]. Такое утверждение, наталкивает на мысль, что для успешного эксплуатирования придется написать декодер, расшифровывающий оставшуюся часть. Поскольку, базовая информация о характере данного типа переполнений, уже известно, следует перейти к практическому использованию предоставленных методов.
Для большей наглядности, все действия, будут применяться к примеру некого уязвимого приложения.
Необходимость написания шеллкода в описанном формате возникает не так часто. Более того, в большинстве случаев, если фильтрование передаваемых данных производит процесс, в котором и происходит это переполнение, можно воспользоваться обычными шеллкодами, потому как не отфильтрованная строка вероятнее всего будет, находится в памяти. Но реальны также случаи, когда процесс фильтрования производит модификацию уже хранящейся в памяти строки или предварительной обработкой занимается другой процесс.
В качестве примера, представлена модель на базе клиент-сервер. Где серверная часть предварительно фильтрует передаваемые данные, а затем передает их на обработку другому приложению.

Такая схеме исключает возможность передачи уязвимому приложению строк содержащих не символьное представление цифр.
Псевдокод уязвимого приложения для платформы Windows XP:
| ||
Собственно говоря, причина возникновения ошибки вас не должна особо беспокоить. Проблематика заключается только в ограниченности инструментов, для написания эксплоита.
Выравнивание и точность
Первое что необходимо учитывать, это диапазон версий приложения, на который рассчитан эксплоит. Если идет разработка эксплоита для одной, конкретной версии, можно быть однозначно уверенным, что в одних и тех же местах, практически всегда будут храниться одинаковые данные. Например, сегмент кода будет неизменным, независимо от системы, на которой запущено приложение и т.д.
Но в этой статье, не будет производиться привязка к версии приложения. Предлагаемый вариант должен быть максимально удобным для его портирования под другие уязвимости. Такой подход вынуждает учесть первую проблему – неточное местоположение шеллкода в памяти.
В данном случае, шеллкод находиться в стеке и в ARGV[1]. Это очень удобно, поскольку, перезаписывая eIP не полностью, можно попасть в диапазон 0x003?3?3?. А переменная ARGV, хранится где-то неподалеку от адреса 0x00323030. Это уже хорошо, но точное местоположение не известно. В таких случаях следует применять инструкцию NOP, код которой 0x90. Тут и возникает первая проблема, NOP нельзя использовать и приодеться искать ему какой либо аналог.
Способ №1
Если известно, что в момент переполнения младшие разряды AL меньше 0x0A (старшие могут быть произвольными), можно вместо NOP воспользоваться инструкцией aaa. Она занимает один байт и является лучшим из возможных вариантов. На AL накладывается такое ограничение, чтобы последовательный вызов aaa не привел к модификации регистра AX. Чтобы убедиться в этом, необходимо вспомнить, что если AL будет больше 0x09, то вызов aaa будет инкрементировать AH и изменять AL.
37 aaa | eAX = 0x00000000 | eAX = 0x0000000a |
37 aaa | eAX = 0x00000000 | eAX = 0x00000100 |
37 aaa | eAX = 0x00000000 | eAX = 0x00000206 |
37 aaa | eAX = 0x00000000 | eAX = 0x0000030c |
… | … | … |
А поскольку, по определению, не известно сколько раз произойдет вызов AAA, в результате eAX будет содержать неизвестное число.
Способ №2
Можно воспользоваться инструкцией xor al,0x34, поскольку ее байт код будет 0x3434. Таким образом, в результате значением eAX могут стать:
|
|
Какое именно из них получится на выходе, неизвестно. Опять-таки, потому что неизвестно, сколько раз исполниться операция XOR. Более того, следует учесть также выравнивание. Дело в том, что в этой ситуации NOP заменен 2-х байтовым “аналогом”. Игнорирование этого условия может привести к неработоспособности шеллкода:
|
|
Обратите внимание, как преобразился код, когда смещение было парным или непарным. Поэтому, после серии XOR AL,0x34 необходимо вставить выравнивающую конструкцию. Но не aaa, поскольку предполагается, что AL больше 0x09. В таком случае можно поступить так:
|
|
Таким образом, независимо от выравнивания, NOP-секция сработает корректно. Исходя из работы XOR, в результате значением eAX будет одно из чисел 0x00, 0x36, 0x34, 0x02. Применяя “XOR-Adjustment” можно свести значение eAX к однозначному результату.
Способ №3
Прошлый способ достаточно неплохой. Но есть более элегантное решение данной проблемы. Его суть заключается в том, чтобы использовать префикс сегментного регистра:
|
|
|
Как вы уже видите, в данном случае существуют три состояния выравнивания, но все они приводят только к повторному исполнению XOR AL,0x36. На этот раз, значение eAX уже будет иметь меньшее количество возможных значений. Если быть точным, то два значения 0x00 и 0x36. И опять-таки, можно применить “XOR-Adjustment” и сравнять значения, хранящиеся в регистре AL.
Когда в мыслях воина нет однозначности – все вокруг потеряно в хаосе. Но только не его мысли… холодный рассудок ничто по сравнению с интуицией. Ибо чувствовать – это понимать хаос, а любая случайность есть предопределенной и неизбежной. | ||
Установка регистров в нужные значения
Можно считать, что NOP-секция исполнилась, после чего применялась технология “XOR-Adjustment” и eAX хранит некое однозначное значение. Следующий этап – это установка регистров в требуемые значения, чтобы начать декодирование остальной части шеллкода.
Тут начинаются новые проблемы. Если на момент переполнения eAX будет известен, так как в нем хранится значение, возвращаемое функцией перед выходом, то значения других регистров могут оказаться неизвестными. В таком случае можно прибегнуть к технологии “XOR swapping”.
Идея заключается в том, что если существует регистр, значение которого не известно, можно применить последовательность операций xor и обменять неизвестное значение на известное.
|
Правда, у этого способа есть один небольшой минус. Область памяти с которой произошел обмен, после этой операции хранит уже неизвестное значение. Поэтому, следует помнить, что для N изменений K*8 битных регистров с помощью “XOR swapping”, необходимо иметь в памяти N*K байт, значения которых известны. Значит, если нужно установить в известные значения регистры eSI и eDI, необходимо 2*4=8 байт в памяти, значения которых будут известны.
Поскольку возможность доступа к тем или иным участкам памяти ограничена значением eAX, для каждого шеллкода известными можно принять различные области памяти. Это может быть стек, служебная информация и т.д. Можно отталкиваться даже от бинарного кода приложения, правда, в этом случае придется еще иметь доступ к области памяти, в которую возможна запись. Кроме этого, если известными являются другие регистры, можно воспользоваться ими, вместо eAX.
|
В этой статье можно найти множество, так называемых, одноразовых приемов. Например, если eSI равен нулю, можно его установить в значение, которое следует в стеке сразу за перезаписанным адресом возврата:
|
После этого, eSI уже не нулевое и eSP+eSI будет указывать на другую область памяти. А поскольку в шеллкоде можно использовать только байты из ограниченного диапазона, скорее всего, эта область не будет нести какую-либо полезную информацию.
Поскольку, предполагается написать максимально портируемый шеллкод, привязка будет делаться максимально независимой. Можно привязываться к значениям в стеке и хип области (там должен лежать шеллкод), к заголовку файла (“MZ” и т.д.), или каким либо другим областям памяти.
Если есть возможность, можно использовать адрес 0x7FFDF000, там хранятся служебные данные работы приложения (информация о подгружаемых модулях и т.д.).
В данном случае привязка будет сделана к адресу 0x10000. Именно с этого адреса начинается приватное адресное пространство исполняемого приложения. Интересно также, что по этому адресу хранится что-то вроде PATH. Но поскольку, переменные окружения разные для каждой системы, там должны храниться разные данные. Но это не совсем так, вот как выглядит начальный фрагмент по адресу 0x10000(далее известные данные в памяти, будут называться константными блоками):
|
|
|
Советую обратить внимание на первые 0x0f байт. Эта последовательность, является стандартной. Хоть в спецификации Windows систем, не сказано, какая именно информация должна храниться по этому адресу, но было проведено множество тестов. Результат везде совпадает, первые 0x0f байт являются стандартными. Далее идущие Unicode-строки, иногда указывают на “Program Files”, “Document and Settings”, “ALLUSERSPROFILE” и т.д. В данном случае они не будут использоваться, для предотвращения необходимости в последующей реорганизации работы шеллкода.
Воспользовавшись этой информацией можно установить регистр в известное значение:
|
|
В действительности, ограниченный набор возможных байт в шеллкоде, диктует свои правила. Ведь на самом деле применяя xor к 0x3?, можно получить только значения 0x0? и 0x3?. Контроль над 4-ма битами, это неплохо, но все же этого недостаточно, чтобы создать в памяти декодер. А производя “XOR swapping”, происходит манипуляция с данными хранящимися в памяти. Исходя из всего этого, можно построить несколько утверждений:
- На момент переполнения, значения регистров не определены. И нет возможности непосредственного их изменения.
- Устанавливая регистр в точное значение, необходимо наличие константных блоков. Доступные для манипуляции данные определяются набором байт в блоке и их xor-комбинациями друг с другом.
- Шеллкод тоже является константным блоком. В случае, когда его местоположение точно известно, его можно использовать для модификации регистров. Если нет точного адреса, можно увеличить размер NOP-секции. Набор байт: 0x3?.
- Использование более чем одного константного блока, расширяет выборку возможных значений. Количество значений, в которые можно установить регистр определяется сумой количества разных, не одинаковых байт, и их xor-комбинаций. Так, как будто, все они входят в один константный блок.
В данном случае, все именно так и обстоит. А в компонентов NOP-секции используется:
|
Фактически это повторяющаяся последовательность байт “0x36,0x36,0x36,0x36,0x34,0x36”. В виде символов, ее можно представить как строку “666646”. Поэтому, далее вместо повторного написания кода, будут употребляться именно такие обозначения. Например:
|
| ||
|
|
Это значит, что используя только блок 0x10000, регистр можно установить в байты 0x00, 0x3a, 0x3d, 0x5c. Но если к ним применить xor, выборка дополняется элементами:
|
По определению, известно, что шеллкод находиться в стеке. Непосредственного доступа к стеку нет. Но если вспомнить, что к нему можно осуществить доступ через конструкцию [eSP + eSI], а также что стек растет в низ, можно установить eSI в достаточно маленькое число и быть уверенным, что значения обнаруженные по этому адресу будут заранее известными. Единственное что придется сделать, несколько увеличить NOP-секцию (если быть точным, то не увеличивать ее а создать предшествующий ей константный блок). Следовательно, следующий шаг – увеличить выборку засечет привлечения данных из шеллкода. Тут есть два варианты развития сюжета:
- Создать одну константную секцию, для получения конкретных значений. Недостаток – ограниченность доступных байт.
- Создать несколько секций, для увеличения выборки на большее количество байт. Чреватость этого метода заключается в увеличении размеров шеллкода.
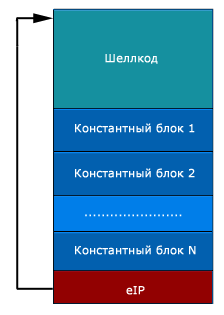 В общем случае на данном этапе структура шеллкода должна иметь следующий вид:
В общем случае на данном этапе структура шеллкода должна иметь следующий вид:
Каждый из искусственно созданных блоков, должен хранить в себе только одинаковые байты. Размерность блока определяется точностью попадания в него. Так, например, если по адресу 0x00120000 есть блок, состоящий из 200 байт 0x34. Чтобы занести в регистр число 0x34343434 необходимо предполагать, что нужные данные лежат по адресу начала блока, но с возможным отклонением в 100 байт. Поэтому искомый адрес будет “адрес блока + отклонение“:
0x00120000+0x64=0x00120064
Элементы искусственного блока, обязательно должны быть одинаковыми. Дело в том, что из-за неточности, в регистр могут быть занесены совершенно другие данные. Хотя для случая, когда наперед известно местоположение шеллкода, это правило не касается.
В этом случае, будет создана только одна такая секция, хранящая 0x37 размером 184 байт. Этот подход позволит добавить в выборку 4 элемента: 0x0a, 0x0d, 0x30, 0x37. Поэтому, появляется возможность установки регистра eSI в значение 0x00303030, а это значение очень близко к адресу, по которому храниться ARGV[1] (шеллкод).
|
|
Размер секции выбран не случайно, на момент операции доступны всего лишь 8 байт. Среди них есть значение 0x5c, а учитывая что [eSP + eSI] должно указывать на середину секции 0x5c*2 = 184 = 0xB8. Это лишь формальность, не обязательно обращаться именно в середину, просто этот факт можно учитывать.
Также можно было установить eSI в ноль, а поправку контролировать изменением регистра eAX. Но проблема в том, что в eAX можно контролировать только младшие разряды, а старшие работают как триггер. Поэтому, в этой ситуации можно столкнуться с такой проблемой как необходимость выделения секции, с минимальным размером в 0x100 байт. Но в таком случае результат установит eSI в 0x37373737, в отличие от первого варианта, где eSI=0x37373737^0x5c = 0x3737376B.
Предварительные итоги
На данном этапе, мы располагаем большим количеством регистров, имеем возможность их модификации, можем редактировать память и т.д. Но, тем не менее, доступные нам операции не позволяют написать шеллкод, несущий некую особую функциональность. Исходя из этого, следующим шагом будет написание декодера. Если до этого момента, вам что-то показалось непонятным, непременно следует со всем этим разобраться, иначе вторая половина статьи может стать для вас совершенно бессмысленной. И помните, «31337» - это
33 31 xor esi,dword ptr [ecx]
33 33 xor esi,dword ptr [ebx]
37 aaa
И обращаясь напоследок к читателю, хочу попросить извинения за то, что материал выложен в несколько тяжелой для восприятия форме. Дело в том, что на написание такого рода эксплоита у меня ушло несколько месяцев. Трудно чего-то добиться, когда на самом деле не располагаешь никакими инструментами. Больше всего пугало, просыпаясь осознавать, что даже во сне ты перебираешь доступные инструкции и операнды… когда ты идешь с друзьями в бар, а твои мысли заняты этими десятью байтами,… когда ты уже ксоришь в голове, а код пишешь на мобильном телефоне. Надеюсь, закончив вторую половину материала, мне все-таки удастся выложить все идеи заполнившие на тот момент мою голову. И я буду искренне признателен, за все ваши высказывания по поводу статьи. Возможно, вам удастся заметить, то, на что я не обратил внимания. Это как паранойя, от которой нет спасения. Честно говоря, после этого шеллкода, когда я смотрю на UTF-8, UTF-16, base64 и Alpha-Numeric шеллкоды, ничего кроме улыбки не возникает на моем лице. Главное успокоится…
(продолжение следует)

Conference