
Новый ускоритель Hopper H100 NVL от Nvidia повышает производительность при работе с массивными языковыми моделями
Ускоритель использует все шесть стеков памяти HBM3 и обеспечивает пропускную способность до 7,8 Тб/сек.

Новый ускоритель Hopper H100 NVL от компании Nvidia позволяет значительно ускорить работу с массивными языковыми моделями, такими как ChatGPT. Он объединяет два ускорителя H100 интерфейсом NVLink и обеспечивает 12-кратный прирост производительности по сравнению с предыдущим поколением A100 при работе с GPT-3.
Новинка использует все шесть стеков памяти HBM3, общий объём которых достигает 188 ГБ, что в 2,35 раза больше, чем у предшественника. Компания Nvidia также заявила о пропускной способности до 7,8 Тб/сек и производительности 68 TFLOPS (FP64), 134 TFLOPS (Tensor Core FP64) и 7916 TOPS (INT8).
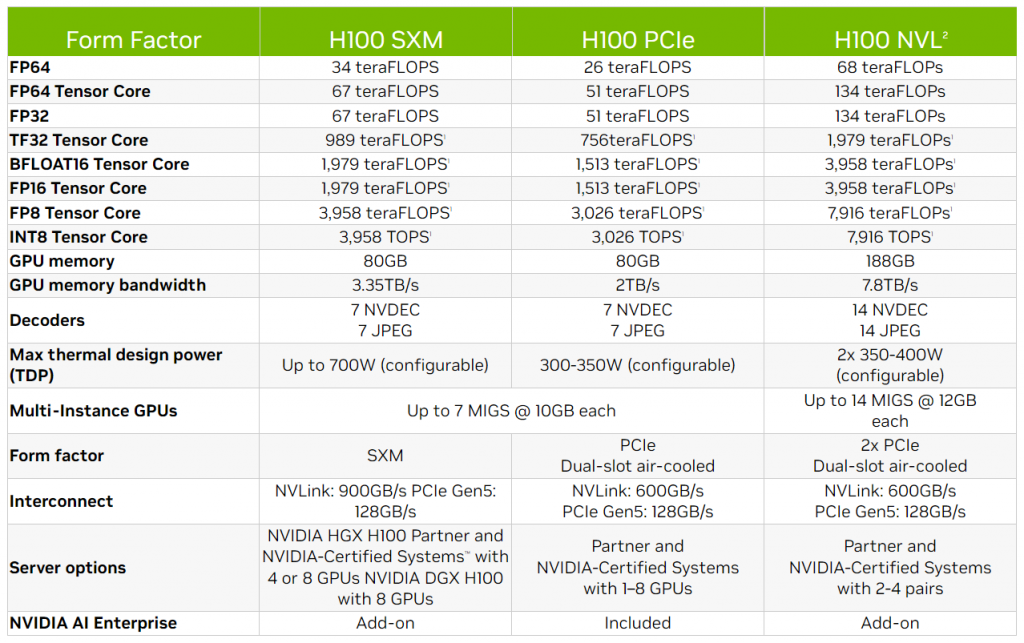
Согласно сравнительной таблице, представленной компанией, новый Hopper H100 NVL значительно опережает своего предшественника H100 (в SXM и PCIe). На данный момент, Nvidia не сообщила подробностей о новом ускорителе, но планирует его запуск во второй половине 2023 года.
В прошлом году NVIDIA анонсировала экспортную версию A100 - A800, чтобы обойти ограничения на экспорт. Она имела немного меньшую пропускную способность NVLink, 400 Гб/с вместо 600 Гб/с. Сейчас NVIDIA запускает в массовое производство архитектуру Hopper, аналогичную флагманской Ampere. Усовершенствованный чип получил модельный номер H800 и также имеет ограничения в NVLink, как и A800. В H100 NVLink имеет пропускную способность 900 Гбайт/с в базовом SXM-варианте.