
80 лет видео в день: аппетиты нового проекта Cosmos от Nvidia

Nvidia тайно собирала миллионы видео с YouTube для обучения ИИ.

Nvidia использовала видео с YouTube и других источников для обучения своих ИИ-продуктов, что стало известно из внутренних переписок и документов, полученных 404 Media.
При обсуждении юридических и этических аспектов использования защищенного авторским правом контента для обучения ИИ-моделей, Nvidia заявила, что их действия полностью соответствуют закону об авторском праве. Внутренние разговоры сотрудников Nvidia показывают, что, когда работники поднимали вопросы о потенциальных юридических проблемах, менеджеры уверяли их в наличии разрешений на использование данных от высшего руководства компании.
Бывший сотрудник Nvidia сообщил, что работников просили скачивать видео с Netflix, YouTube и других источников для обучения ИИ-моделей, таких как генератор 3D-мира Omniverse, системы для беспилотных автомобилей и продукты с «цифровыми людьми». Проект, получивший название Cosmos, пока не был представлен широкой публике.
Целью Cosmos было создание современной модели генерации видео, способной моделировать свет, физику и интеллект в одном месте, что позволило бы использовать Cosmos в различных приложениях. Внутренние сообщения показывают, что сотрудники использовали open-source программу yt-dlp для скачивания видео с YouTube, обходя блокировки через виртуальные машины с обновляющимися IP-адресами.
Проектные менеджеры обсуждали использование 20-30 виртуальных машин в Amazon Web Services для скачивания видео объемом, эквивалентным 80 годам просмотра, каждый день. В мае представитель Nvidia заявил, что компания завершает первую версию конвейера данных и готовится к созданию фабрики видеоданных, которая «ежедневно будет генерировать данные, эквивалентные целой жизни человека».
Представитель Nvidia сообщил, что компания уверена в соответствии своих моделей закону об авторском праве, так как закон защищает выражения, но не факты, идеи, данные или информацию, которые можно использовать для создания своих собственных выражений.
Google и Netflix подтвердили, что использование их контента Nvidia является нарушением условий использования. Работники Nvidia, обеспокоенные юридическими аспектами, получали ответ от менеджеров, что это «исполнительное решение», и они не должны об этом беспокоиться.
Тем не менее, многие исследователи и юристы утверждают, что использование защищенного авторским правом контента для обучения ИИ — это открытый юридический вопрос. В последние годы академики стали чаще лицензировать свои исследовательские данные для некоммерческого использования, чтобы ограничить коммерческое использование их работы.
Проект Cosmos включал использование как публичных, так и внутренних видео, а также данные, собранные исследователями. Однако лицензии многих из этих наборов данных ограничивают их использование исключительно академическими целями.
В обсуждениях внутри Nvidia также поднимался вопрос о потенциальном использовании видео из фильмов для обучения моделей. Сотрудники предлагали загружать фильмы, такие как «Аватар» и «Властелин колец», чтобы получить данные высокого качества. Однако это вызвало опасения о возможных конфликтах с Голливудом и другими заинтересованными сторонами.
Проект столкнулся с рядом технических и юридических проблем, связанных с захватом видео из игр и других источников. Тем не менее, в марте Nvidia удалось скачать 100 000 видео всего за две недели, что стало важным этапом в реализации проекта.
Примечательно, что ведущий ученый Nvidia Франческо Феррони создал канал в Slack с целью создания огромного набора видеоданных для проекта Cosmos. Феррони в канал добавил ссылку на таблицу с перечнем датасетов, включая:
- MovieNet (база данных из более 1 000 фильмов и 60 000 трейлеров к фильмам);
- WebVid (видеодатасет с GitHub, составленный из стоковых изображений и удаленный его создателем после запроса на прекращение деятельности от Shutterstock);
- InternVid-10M (датасет, содержащий 10 миллионов ID видео с YouTube);
- несколько внутренних датасетов с сохраненными кадрами из видеоигр.
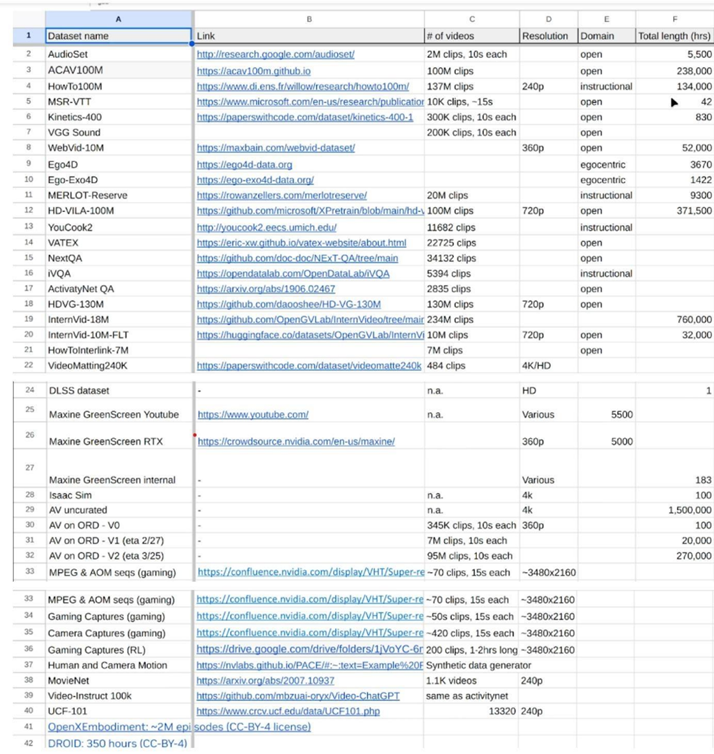
Таблица Феррони
Ситуация с проектом Cosmos наглядно демонстрирует, как крупнейшие технологические компании используют правовые серые зоны для накопления огромных объемов данных, необходимых для обучения ИИ-моделей. В то же время, это ставит под угрозу права создателей контента и вызывает обеспокоенность среди исследователей и правозащитников.
Скандал также показал, что в индустрии ИИ существует значительная культура «не спрашивай разрешения», что подрывает доверие к технологиям и поднимает вопросы о необходимости ужесточения регулирования. До тех пор, пока не будет создана четкая правовая база и стандарты прозрачности, подобные ситуации будут повторяться, ставя под угрозу как права авторов контента, так и доверие общественности к инновациям в сфере искусственного интеллекта.