
132 токена в секунду? SambaNova уничтожила всех конкурентов в ИИ-отрасли
Новая облачная платформа компании демонстрирует весь потенциал ускорителей SN40L.

ИИ-стартап под названием SambaNova недавно представил собственное облачное решение для работы с искусственным интеллектом, заявив, что оно способно обслуживать самые крупные модели от Meta* значительно быстрее, чем конкуренты.
Компания утверждает, что её новая платформа может обрабатывать модель Llama 3.1, состоящую из 405 миллиардов параметров, с рекордной скоростью — более 132 токенов в секунду. Это значительно превышает производительность даже самых мощных систем на базе GPU.
Родриго Лианг, генеральный директор SambaNova, сообщил, что даже ближайших конкурентов их новое решение по скорости обработки токенов превосходит как минимум вдвое. Слова Лианга также были проиллюстрированы сравнительным графиком от Artificial Analysis.
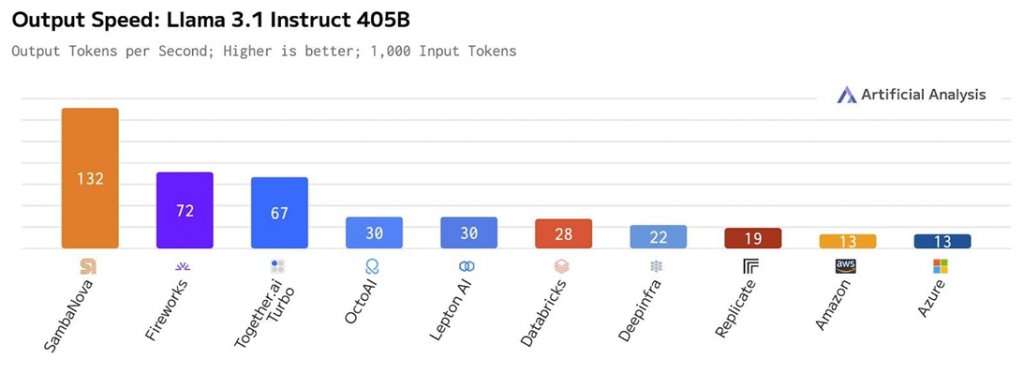
Модель Llama 3.1, представленная Meta в этом году, хоть и уступает по размерам конкурентам от OpenAI и Google, всё же требует огромных вычислительных ресурсов. Запуск этой модели на полной 16-битной точности требует более 810 ГБ памяти. Для достижения столь высокой производительности, SambaNova использует 16 своих ускорителей SN40L с высокой пропускной способностью и значительными объёмами кэш-памяти.
Особенностью архитектуры SN40L является возможность избежать узких мест, которые часто возникают в многоядерных системах с GPU. Как отметил руководитель продуктового направления SambaNova Антон МакГоннелл, их ускорители имеют большие объёмы кэша, что позволяет поддерживать высокую скорость обработки данных и масштабировать производительность при одновременной обработке нескольких запросов.
Тем не менее, несмотря на высокий уровень точности, SambaNova пришлось пойти на компромисс, сократив контекстное окно модели со 128 тысяч токенов до 8 тысяч. Это ограничение введено для обеспечения стабильной работы при большом потоке запросов, но может повлиять на использование модели в задачах с длительным контекстом, таких как обработка документов.
Облачная платформа SambaNova предлагает как бесплатные, так и корпоративные тарифы. В ближайшее время компания планирует выпустить и версию для разработчиков, которая позволит пользователям создавать собственные модели на базе Llama 3.1.
Тем временем, конкуренция в области ускорителей для работы с ИИ не стоит на месте. Так, компания Cerebras в конце августа анонсировала свою облачную платформу, способную обрабатывать до 450 токенов в секунду на модели Llama 3.1 с 70 миллиардами параметров. Кроме того, она также планирует увеличить скорость до 350 токенов для модели с 405 миллиардами параметров. Таким образом, в будущем Cerebras сможет обойти SambaNova по производительности.
Другие игроки на рынке, такие как Groq, также продолжают развивать свои решения, что ещё больше разогревает конкуренцию в борьбе за звание самого быстрого провайдера ИИ-инфраструктуры.